
Apache Spark and Big Data
Overview:
As big data becomes one of the most important assets an enterprise can possess, enterprises are demanding more out of the data. Enterprises expect data to provide complex and multidimensional insights at high speeds. To provide such insights, companies need appropriate framework, technologies and tools. Steep expectations from big data are going to define the relationship between enterprises and data. Apache Spark provides the framework to perform multidimensional actions such as processing, querying and generating analytics at high speeds and looking at the future, it seems likely that Apache Spark is going to be the most popular platform for big data. An important factor in this context is Apache Spark is an open source framework which increases its appeal in an otherwise expensive proprietary technology market. Apache Spark is seen as a competitor or successor to MapReduce. There are some experts who still consider Spark a framework at its nascent stages and it can right now support only a couple of operational analytics.
Context for Apache Spark
Apache Spark has emerged at a time when the enterprises expect the data they have to offer more but are constrained by several factors. Enterprises are facing problems on several fronts such as inadequate framework and technology, expensive technology and lack of skilled personnel. Let us examine these problems a little bit more closely.
Inadequate framework
The frameworks available are unable to process data with a high degree of efficiency. Speed, cross-platform compatibility and querying are all, in varying degrees, issues with current software frameworks. With time, the expectations from data are becoming more varied, complex and multidimensional. This is creating a gap between the expectations and the capabilities
High cost of software
Costs of proprietary software or framework are prohibitive and that is creating an exclusive club because mid-sized to small companies are unable to purchase and renew the licenses. Only big companies with deep pockets can afford such expenses which means that smaller companies remain deprived of the higher data processing capabilities.
Incompatibility
The available frameworks have compatibility issues with other tools. For example, MapReduce runs only on Hadoop. Spark does not have such compatibility issues. It can run on any resource manager such as YARN or Mesos.
Reasons Apache Spark is the future platform for big data
When you want reasons Apache Spark is the future platform for big data, it is kind of inevitable to compare Spark with Hadoop. Hadoop is still the most favorite big data processing framework and there had better be good reasons Spark replaces Hadoop. So here are a few reasons Spark is considered the future.
Efficient handling of iterative algorithms
Spark is great at handling programming models involving iterations, interactivity that includes streaming and much more. On the other hand, MapReduce displays several inefficiencies in handling iterative algorithms. That is a big reason Apache Spark is considered a prime replacement for MapReduce.
Spark provides analytics workflows
When it comes to analytics platforms, Spark provides a wealth of resources. It has, for example, library for machine learning (MLlib), Application Programming Interfaces (APIs) for graph analytics, also known as GraphX, support for SQL-based querying, streaming and applications. All these constitute a comprehensive analytics platform. According to Ian Lumb of Bright Computing, “Workflows can be executed in a batch mode or in real time using the built-in interactive shell support available in Scala and Python. Because the notable stats package R is already one of the supplemental projects, Spark’s analytics stack is quite comprehensive. Spark can access any Hadoop data source – from HDFS (and other file systems) to databases like Apache HBase and Apache Cassandra. Thus data originating from Hadoop can be incorporated into Spark applications and workflows.”
Better memory management
In a recent benchmarking study on in-memory storage of binary data, it was discovered that Spark outperformed Hadoop by 20x factor. This is because Spark offers the Resilient Distributed Datasets (RDDs). Alan Lumb of Bright Computing adds, “RDDs are fault-tolerant, parallel data structures ideally suited to in-memory cluster computing. Consistent with the Hadoop paradigm, RDDs can persist and be partitioned across a Big Data infrastructure ensuring that data is optimally placed. And, of course, RDDs can be manipulated using a rich set of operators.” So with better memory utilization, enterprises can look forward to better resource management and significant cost savings.
Better results
In a best-case scenario for Hadoop, Spark beat Hadoop by a 20x factor. See the image below, it shows that Spark beat Hadoop even when memory is unavailable and it has to use its disks.
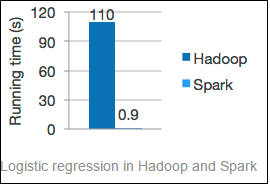
Spark and Hadoop comparison
According to the Spark Apache website, Spark can “Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. Spark has an advanced DAG execution engine that supports cyclic data flow and in-memory computing.”
Generality
Spark can combine streaming, SQL, and complex analytics. It can power a stack of libraries that include SQL, GraphX, MLlib for machine learning and DataFrames, and Spark Streaming. You can combine all these libraries seamlessly within the same application.
Spark can run everywhere
Spark can run on Mesos, standalone, Hadoop, or in the cloud. It can also access diverse data sources the list of which includes Cassandra, HDFS, HBase, and S3.
Significant uptake
Spark can put available resources to better use. Bright computing, which provides software solutions for deploying and managing big data clusters and HPC and OpenStack in the data center and in the cloud, observes, “Spark 1.2.0 was released in mid-December 2014. Over 1,000 commits were made by the 172 developers contributing to this release – that’s more than 3x the number of developers that contributed to the previous release, Spark 1.1.1.” Spark’s achievements lie in the fact that it can involve the whole community of software developers into contributing.
Summary
While there are a lot of positive vibes about Spark, it still needs to be deployed across enterprises and the use cases need to be tested. Theoretically, the features and capabilities are impressive and it promises to deliver a lot.