
Apache Spark
BY RADEK OSTROWSKI – SOFTWARE ENGINEER @ TOPTAL
I first heard of Spark in late 2013 when I became interested in Scala, the language in which Spark is written. Sometime later, I did a fun data science project trying to predict survival on the Titanic. This turned out to be a great way to get further introduced to Spark concepts and programming. I highly recommend it for any aspiring Spark developers looking for a place to get started.
Today, Spark is being adopted by major players like Amazon, eBay, and Yahoo! Many organizations run Spark on clusters with thousands of nodes. According to the Spark FAQ, the largest known cluster has over 8000 nodes. Indeed, Spark is a technology well worth taking note of and learning about.

Image1: Apache Spark
This article provides an introduction to Spark including use cases and examples. It contains information from the Apache Spark website as well as the book Learning Spark – Lightning-Fast Big Data Analysis.
What is Apache Spark? An Introduction
Spark is an Apache project advertised as “lightning fast cluster computing”. It has a thriving open-source community and is the most active Apache project at the moment.
Spark provides a faster and more general data processing platform. Spark lets you run programs up to 100x faster in memory, or 10x faster on disk, than Hadoop. Last year, Spark took over Hadoop by completing the 100 TB Daytona GraySort contest 3x faster on one tenth the number of machines and it also became the fastest open source engine for sorting a petabyte.
Spark also makes it possible to write code more quickly as you have over 80 high-level operators at your disposal. To demonstrate this, let’s have a look at the “Hello World!” of BigData: the Word Count example. Written in Java for MapReduce it has around 50 lines of code, whereas in Spark (and Scala) you can do it as simply as this:
sparkContext.textFile(“hdfs://…”)
.flatMap(line => line.split(” “))
.map(word => (word, 1)).reduceByKey(_ + _)
.saveAsTextFile(“hdfs://…”)
Another important aspect when learning how to use Apache Spark is the interactive shell (REPL) which it provides out-of-the box. Using REPL, one can test the outcome of each line of code without first needing to code and execute the entire job. The path to working code is thus much shorter and ad-hoc data analysis is made possible.
Additional key features of Spark include:
- Currently provides APIs in Scala, Java, and Python, with support for other languages (such as R) on the way
- Integrates well with the Hadoop ecosystem and data sources (HDFS, Amazon S3, Hive, HBase, Cassandra, etc.)
- Can run on clusters managed by Hadoop YARN or Apache Mesos, and can also run standalone
The Spark core is complemented by a set of powerful, higher-level libraries which can be seamlessly used in the same application. These libraries currently include SparkSQL, Spark Streaming, MLlib (for machine learning), and GraphX, each of which is further detailed in this article. Additional Spark libraries and extensions are currently under development as well.
Spark libraries
Image2: Apache Spark libraries
Spark Core
Spark Core is the base engine for large-scale parallel and distributed data processing. It is responsible for:
- memory management and fault recovery
- scheduling, distributing and monitoring jobs on a cluster
- interacting with storage systems
Spark introduces the concept of an RDD (Resilient Distributed Dataset), an immutable fault-tolerant, distributed collection of objects that can be operated on in parallel. An RDD can contain any type of object and is created by loading an external dataset or distributing a collection from the driver program.
RDDs support two types of operations:
- Transformationsare operations (such as map, filter, join, union, and so on) that are performed on an RDD and which yield a new RDD containing the result.
- Actionsare operations (such as reduce, count, first, and so on) that return a value after running a computation on an RDD.
Transformations in Spark are “lazy”, meaning that they do not compute their results right away. Instead, they just “remember” the operation to be performed and the dataset (e.g., file) to which the operation is to be performed. The transformations are only actually computed when an action is called and the result is returned to the driver program. This design enables Spark to run more efficiently. For example, if a big file was transformed in various ways and passed to first action, Spark would only process and return the result for the first line, rather than do the work for the entire file.
By default, each transformed RDD may be recomputed each time you run an action on it. However, you may also persist an RDD in memory using the persist or cache method, in which case Spark will keep the elements around on the cluster for much faster access the next time you query it.
SparkSQL
SparkSQL is a Spark component that supports querying data either via SQL or via the Hive Query Language. It originated as the Apache Hive port to run on top of Spark (in place of MapReduce) and is now integrated with the Spark stack. In addition to providing support for various data sources, it makes it possible to weave SQL queries with code transformations which results in a very powerful tool. Below is an example of a Hive compatible query:
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql(“CREATE TABLE IF NOT EXISTS src (key INT, value STRING)”)
sqlContext.sql(“LOAD DATA LOCAL INPATH ‘examples/src/main/resources/kv1.txt’ INTO TABLE src”)
// Queries are expressed in HiveQL
sqlContext.sql(“FROM src SELECT key, value”).collect().foreach(println)
Spark Streaming
Spark Streaming supports real time processing of streaming data, such as production web server log files (e.g. Apache Flume and HDFS/S3), social media like Twitter, and various messaging queues like Kafka. Under the hood, Spark Streaming receives the input data streams and divides the data into batches. Next, they get processed by the Spark engine and generate final stream of results in batches, as depicted below.
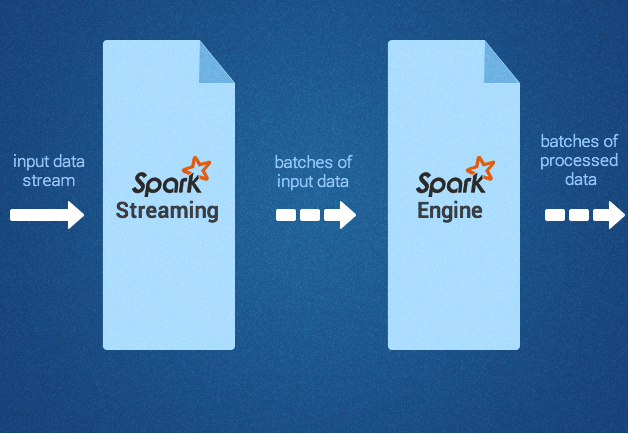
Spark streaming
Image 3: Spark streaming and engine
The Spark Streaming API closely matches that of the Spark Core, making it easy for programmers to work in the worlds of both batch and streaming data.
MLlib
MLlib is a machine learning library that provides various algorithms designed to scale out on a cluster for classification, regression, clustering, and collaborative filtering, and so on. Some of these algorithms also work with streaming data, such as linear regression using ordinary least squares or k-means clustering (and more on the way). Apache Mahout (a machine learning library for Hadoop) has already turned away from MapReduce and joined forces on Spark MLlib.