
Big Data and Python
Overview :
Python is a general purpose programming language which is open source, flexible, powerful and easy to use. One of the most important features of python is its rich set of utilities and libraries for data processing and analytics tasks. In the current era of big data, python is getting more popularity due to its easy-to-use features which supports big data processing.
In this article we will explore features and packages of python which are widely used in the big data use cases. We will also walk through a real life example which shows big data processing (unstructured data) with the help of python packages and programming.
Some background of Python:
Python was first introduced in the year 1980s and then implemented in the year 1989 by Guido Van Rossum. Python was developed as an open source project which can also be used in commercial environment. The basic philosophy of python is to make code easy to use, more readable and write less number of lines for accomplishing more tasks. The most attractive part of python is its standard library which contains ready to use tools for performing various tasks. Python Package Index was introduced in Jan.2016, containing more than 72000 packages for third party software usage.
Python features
Following are some of the important features of python which makes it a perfect fit for rapid application development.
- Python is interpreted language so the program does not need to be compiled. Interpreter parses the program code and generates the output.
- Python is dynamically typed, so the variables types are defined automatically.
- Python is strongly typed. So the developers need to cast the type manually.
- Less code and more use makes it more acceptable.
- Python is portable, extendable and scalable.
Why Python is important in big data and analytics?
Python is very popular for big data processing due to its simple usage and wide set of data processing libraries. It is also preferred for making scalable applications. The other important side of python is its ability to integrate with web applications. All the above features provide support for big data processing and generating quick insights. This quick and dynamic insight (which changes very frequently) is valuable to the organizations. So they want some powerful language/platform/tools to get this value instantly and remain competitive in the market. Python plays an important role here and supports the need of the business.
How to download, install and setup Python?
In most of the Linux distribution, python comes as a default installed package. So in those scenarios, users do not need to install it separately. For Windows, the installer can be downloaded from the link below and then install as per instruction. Just remember to check ‘Add Python.exe to path‘ so that it is automatically added in the path.
Following is the download link:
https://www.python.org/downloads/
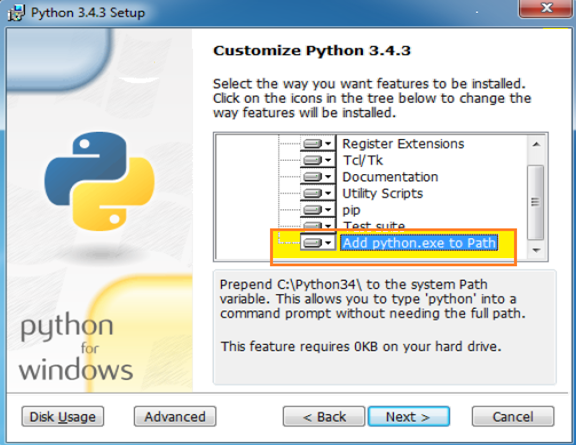
Image 1: Showing ‘Add Python.exe to path’ as checked
After installation is complete, type ‘python’ in the command prompt as shown below. It will display details about installation, version etc. It also ensures that your python installation is successful.
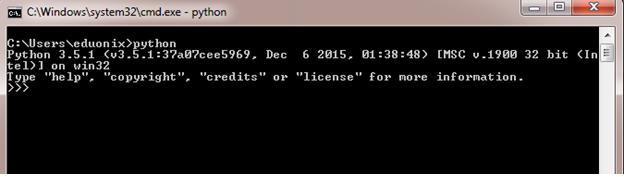
Image 2: Showing python command prompt
Now to start writing a python program developers need to install a good text editor. So notepad++ or any other good editor can be installed.
How to run python applications? Python can be used in two ways as shown below.
- Type python commands from command prompt
- Write python code in script file (.py)
In our example we will be using script file to run the application.
How to process unstructured data by using python?
We have already discussed that python is one of the favourite languages for big data processing. Big data comes from different sources, and one of the most important sources is social media like face book, twitter etc. Big data covers different types of data like unstructured, semi-structured or any other form. But the most important part it to process it and make it useful.
In our sample application we will check how twitter data (which is a big data) can be processed by using python.
Before we jump into the code, following steps needs to be performed
- Create an app by going to twitter development link (https://apps.twitter.com/). This will provide you app key, app secret, qauth_token and qauth_token_secret. All these will be required in your application to access the twitter data.
- Install Twython and simplejson. The first one is a python wrapper around Twitter API and the 2nd one is used for parsing json data.
Once this basic set up is complete, we are ready to go to check the code.
First, we need to import some relevant python packages which will be used in our programming.
Listing 1: Importing python packages
[code]
import sys
import string
import simplejson
import datetime
from twython import Twython
[/code]
In the 2nd step we are creating some variables to be used in the program
Listing2: Setting up variables
[code]
nowtm = datetime.datetime.now()
daytm=int(nowtm.day)
monthtm=int(nowtm.month)
yeartm=int(nowtm.year)
[/code]
Third step is to create variable with OAuth tokens created during app creation in Twitter development site.
Listing3: Creating authentication
[code]
t_auth = Twython(app_key=’YOUR_APP_KEY’,
oauth_token=’YOUR_OAUTH_TOKEN’,
oauth_token_secret=’YOUR_OAUTH_TOKEN_SECRET’)
[/code]
Next, assign twitter user ids into a variable as shown below and get users. After that create output file, header fields, initialize output file and write headers.
Listing4: Creating output file and write headers
[code]
uids = “4516,9815312,132133,12343233,545334,9829867,2653636,2093829,28373663”
twusers = t_auth.lookup_user(user_id = uids)
twoutfn = “twitter_user_data_%i.%i.%i.txt” % (nowtm.month, nowtm.day, nowtm.year)
usr_fields = “usr_id usr_screen_name usr_name usr_created_at usr_url”.split()
tw_outfp = open(twoutfn, “w”)
tw_outfp.write(string.join(usr_fields, “\t”) + “\n”)
[/code]
Now the last step is to run for loop and retrieve relevant values from json format and write it to a file.
Listing5: Getting values and writes it in a output file
[code]
for entry in twusers:
dic_r = {}
for tw_f in usr_fields:
dic_r[tw_f] = “”
dic_r[‘usr_id’] = entry[‘id’]
dic_r[‘usr_screen_name’] = entry[‘screen_name’]
dic_r[‘usr_name’] = entry[‘name’]
dic_r[‘usr_created_at’] = entry[‘created_at’]
dic_r[‘usr_url’] = entry[‘url’]
final_lst = []
for tw_f in usr_fields:
final_lst.append(unicode(dic_r[tw_f]).replace(“\/”, “/”))
tw_outfp.write(string.join(final_lst, “\t”).encode(“utf-8”) + “\n”)
tw_outfp.close()
[/code]
This output data from twitter is now ready for processing in a hadoop platform. These data is parsed using MapReduce program to get analytics value. The same techniques can be applied for any unstructured data.
Limitations of Python:
Although python has lot of positive sides, but it also has some set of limitations as it exists in all the languages. Let us have a brief look at those cons.
- Python does not have proper multi-processor support
- Lack of commercial support
- Does not have good pre-packaged solutions
- Lack of good documentation
- Database layer is a bit old fashioned, although work is going on in this area.
- Lack of UI development framework
Success stories:
Python is growing rapidly and its practical implementations are also encouraging. Some of the success stories are mentioned below.
- Python has been used to improve image processing from the Hubble Space Telescope
- YouTube has used it to develop its massive scalable web applications
- Google’s internal infrastructure is also powered by Python
- Companies like Sony DreamWorks, Disney uses Python for co-ordinating clusters of computers for image processing
Conclusion: Python is one of the most successful languages for big data and analytics applications. Its popularity is also growing day by day. In this piece of article, we have covered brief back ground, features and installation of the software. We have also discussed specific features which are relevant to big data applications. In spite of some limitations, python is a good choice for big data processing and analytics.
Kaushik (Author): Technical Architect by profession, having more than 20 years of experience in IT industry. Passionate about the technology world. Interested in software design, open source technologies, Big data, AI and technology consulting. Teaching and mentoring IT professionals for more than 12 years. Also, involved into online/offline training, interviewing, consulting, mentoring and coaching.
LinkedIn Profile – https://www.linkedin.com/in/kaushik-pal-36b36915