Overview: In this article I will discuss about HDFS, which is the underlying file system of Apache Hadoop framework. Hadoop Distributed File System (HDFS) is a distributed storage space that spans across thousands of commodity hardware. This file system provides fault tolerance, efficient throughput, streaming data access and reliability. The architecture of HDFS is suitable for storing large volume of data and its quick processing. HDFS is a part of Apache eco-system.
Introduction:
Apache Hadoop is a software framework provided by the open source community. This is helpful in storing and processing of data-sets of large scale on clusters of commodity hardware. Hadoop is licensed under the Apache License 2.0.
The Apache Hadoop framework consists of the following modules:
- Hadoop Common – The common module contains libraries and utilities which are required by other modules of Hadoop.
- Hadoop Distributed File System (HDFS) – This is the distributed file-system which stores data on the commodity machines. This also provides a very high aggregate bandwidth across the cluster.
- Hadoop YARN – This is the resource-management platform which is responsible for managing compute resources over the clusters and using them for scheduling of users’ applications.
- Hadoop MapReduce – This is the programming model used for large scale data processing.
All the modules in Hadoop are designed with a fundamental assumption that hardware failures (it can be a single machine or entire rack) are obvious and thus should be automatically handled in software application by the Hadoop framework. Apache Hadoop’s HDFS components are originally derived from Google‘s MapReduce and Google File System (GFS) respectively.
Hadoop Distributed File System (HDFS):
Hadoop Distributed File System or HDFS is a primary distributed storage used by the Hadoop applications. An HDFS cluster primarily consists of a NameNode and the DataNode. The NameNode manages the file system metadata and DataNodes are used to store the actual data.
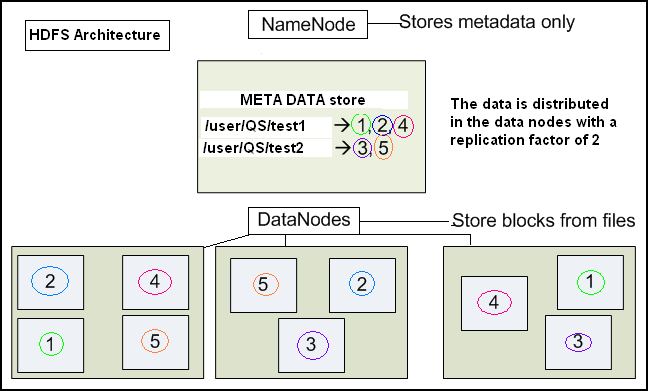
HDFS Architecture
Picture 1: HDFS Architecture
The HDFS architecture diagram explains the basic interactions among NameNode, the DataNodes, and the clients. The client’s component calls the NameNode for file metadata or file modifications. The client then performs the actual file I/O operation directly with the DataNodes.
Salient Features of HDFS: The following are some of the salient features that could be of interest to many users –
- Hadoop, including HDFS, is a perfect match for distributed storage and distributed processing using low cost commodity hardware. Hadoop is scalable, fault tolerant and very simple to expand. MapReduce, which is well known for its simplicity and applicability in case of large set of distributed applications.
- HDFS is highly configurable. The default configuration setup is good enough for most of the applications. In general, the default configuration needs to be tuned only for very large clusters.
- Hadoop is written based on Java platform and is supported on almost all major platforms.
- Hadoop supports shell and shell-like commands to communicate with HDFS
- The NameNode and DataNodes have their own built in web servers which make it easy to check current status of the cluster.
- New features and updates are frequently implemented in HDFS. The following list is a subset of the useful features available in HDFS:
- File permissions and authentication.
- Rack awareness: This helps to take a node’s physical location into account while scheduling tasks and allocating storage.
- Safemode: This is the administrative mainly used mode for maintenance purpose.
- fsck: This is a utility used to diagnose health of the file system, and to find missing files or blocks.
- fetchdt: This is a utility used to fetch DelegationToken and store it in a file on the local system.
- Rebalancer: This is a tool used to balance the cluster when the data is unevenly distributed among DataNodes.
- Upgrade and rollback: Once the software is upgraded, it is possible to rollback to the HDFS’ state before the upgrade in case of any unexpected problem.
- Secondary NameNode: This node performs periodic checkpoints of the namespace and helps keep the size of file containing log of HDFS modifications within certain limits at the NameNode.
- Checkpoint node: This node performs periodic checkpoints of the namespace and helps minimize the size of the log stored at the NameNode containing changes made to the HDFS. It also replaces the role/function previously filled by the Secondary NameNode. As an alternative, the NameNode allows multiple nodes as check points, as long as there are no Backup nodes available (registered) with the system.
- Backup node: This can be defined as an extension to the Checkpoint node. Along with checkpointing it is also used to receive a stream of edits from the NameNode. Thus it maintains its own in-memory copy of the namespace. It is always in sync with the active NameNode and namespace state. Only one Backup node is allowed to be registered with the NameNode at a time.
Goal of HDFS:
Hadoop has a goal to use commonly available servers in a very large cluster, where each and every server has a set of inexpensive internal disk drives. For better performance, the MapReduce API tries to assign the workloads on these servers where the data is stored which is to be processed. This is known as data locality. Because of this fact, in a Hadoop environment, it is not recommended to use a storage area network (SAN), or a network attached storage (NAS). For Hadoop deployments using a SAN or NAS, the extra network communication overhead can cause performance bottlenecks, especially in case of larger clusters.
Now lets consider a situation where we have a cluster of 1000-machine, and each of these machines have three internal disk drives. So think of the failure rate of a cluster composed of 3000 inexpensive drives + 1000 inexpensive servers! We are almost in an agreement here : The component mean time to failure (MTTF) you are going to experience in a Hadoop cluster is likely similar to the zipper on your kid’s jacket: it is bound to fail. The best part about Hadoop is that the reality of the MTTF rates associated with inexpensive hardware is actually well understood and accepted. This forms a part of the strength of Hadoop. Hadoop has built-in fault tolerance and fault-compensation capabilities. The same goes for HDFS, as the data is divided into blocks and chunks, and copies of these chunks/blocks are stored on other servers across the Hadoop cluster. To make it understand in an easy manner we can say that an individual file is actually stored as smaller blocks which are replicated across multiple servers in the entire cluster so that the access to the file is faster.
An Example: Now we will discuss a case study to understand the HDFS
Let us consider a file which contains the telephone numbers of all the residents in the United States of America. Those who have their last starting with A could be stored on server 1; people having their last name with B are on server 2, and so on. In a Hadoop environment, pieces of this phonebook will be stored distributed on the entire cluster. To reconstruct the data of the entire phonebook, your program would need access the blocks from every server in the cluster. To achieve higher availability HDFS replicates smaller pieces of data onto two additional servers by default. One can talk about redundancy here but the argument to support redundancy is to avoid the failure condition and provide a fault tolerance solution. This redundancy can be increased or decreased on a per-file basis or for the whole environment. This redundancy offers multiple benefits; the most obvious one is the data being highly available. In addition to this, the data redundancy allows the Hadoop cluster to break work up into smaller chunks and run those smaller jobs on all the servers in the cluster for better scalability. Finally, as an end user we get the benefit of data locality, which is critical while working with large data sets.
Conclusion: So we have seen that HDFS is one of the major components in Apache Hadoop eco-system. The file system is the underlying storage structure which is very powerful compared to the local file system. So all the big data applications use the HDFS for their data storage
Let us conclude our discussion with the following bullets:
- Apache Hadoop HDFS is a framework provided by the open source community used to store large set of data in clusters
- Hadoop framework consists of the following four modules :
- Hadoop Common
- Hadoop Distributed file system or HDFS
- Hadoop Yarn
- Hadoop Map reduce
- One HDFS cluster contains a NameNode and a DataNode.
- The goal of HDFS is to use the low cost servers on a very large cluster.
Hope you have enjoyed the article and understood the basic concepts of HDFS. Keep reading.