The demand for faster data processing has been increasing and real-time streaming data processing appears to be the answer. While Apache Spark is still being used in a lot of organizations for big data processing, Apache Flink a veni repede ca alternativă. In fact, mulți cred că are potențialul de a înlocui Apache Spark, datorita capacitatii sale de a procesa timp de streaming de date reale. Of course, juriul dacă Flink poate înlocui Spark este încă afară pentru că Flink este încă să fie supuse la teste pe scara larga. Dar, procesarea în timp real și latență scăzută a datelor sunt două dintre caracteristicile sale definitorii. At the same time, acest lucru trebuie să se considere că Apache Spark probabil nu va iesi din favoare, deoarece capacitățile sale de procesare a seriei va fi în continuare relevantă.
Caz pentru prelucrarea datelor Streaming
Pentru toate meritele prelucrării pe bază de lot, se pare că există un caz puternic pentru procesarea în flux a datelor în timp real. Streaming de prelucrare a datelor face posibilă crearea și încărcarea unui depozit de date rapid. Un procesor de streaming care are latență de date oferă mai multe perspective reduse pe date rapid. So, aveți mai mult timp pentru a afla ce se întâmplă. În plus față de procesare rapidă, există, de asemenea, un alt avantaj semnificativ: aveți mai mult timp pentru a proiecta un răspuns adecvat la evenimente. For example, în cazul detectării anomaliilor, latență mai mică și de detectare mai rapidă vă permite să identificați cel mai bun răspuns, care este esențială pentru a preveni deteriorarea în cazuri, cum ar fi atacurile frauduloase pe un site sigur sau deteriorarea echipamentelor industriale. So, puteți preveni o pierdere substanțială.
Ce este Apache Flink?
Apache Flink este un instrument de mare de prelucrare a datelor și este cunoscut pentru a procesa date mari rapid cu latență scăzută de date și toleranță ridicată la erori sisteme distribuite pe scară largă. Caracteristica sa definitorie este capacitatea sa de a procesa date de streaming în timp real.
Apache Flink a început ca un proiect open source academic și atunci, era cunoscut sub numele de stratosferă. Later, a devenit o parte din incubator Apache Software Foundation. Pentru a evita un conflict de nume cu un alt proiect, numele a fost schimbat la Flink. Flink Numele este adecvat, deoarece înseamnă agil. Chiar și logo-ul ales, o veveriță este adecvată, deoarece o veveriță reprezintă virtuțile agilitate, sprinteneală și viteza.
Din moment ce s-a adăugat la Apache Software Foundation, a avut o creștere destul de rapidă ca un instrument de mare de prelucrare a datelor și în cadrul 8 luni, ea a început să capteze atenția unui public mai larg. un interes tot mai mare a oamenilor în Flink sa reflectat în numărul de participanți într-un număr de reuniuni în 2015. Un număr de oameni au participat la întâlnirea de pe Flink la Conferința de la Londra, Strata mai 2015 și Summit-ul Hadoop în San Jose, în iunie, 2015. Mai mult decât 60 oameni au participat la Bay Area Apache Flink întrunirea găzduită la sediul MapR din San Jose în luna august, 2015.
Imaginea de mai jos prezintă arhitectura Lambda a Flink.
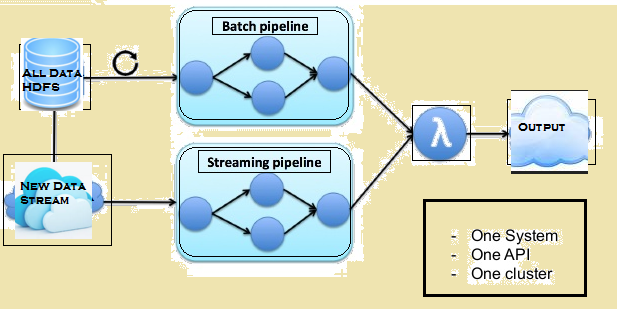
Arhitectura lambda de Flink
Comparație între Spark și Flink
Cu toate că există câteva asemănări între Spark și Flink, de exemplu, API-uri și a componentelor acestora, asemănările nu contează prea mult atunci când vine vorba de prelucrare a datelor. Având în vedere mai jos este o comparație între Flink și Spark.
Procesarea datelor
Scânteie procesează date în modul de lot în timp ce Flink procesează date de difuzare în timp real. Scânteii procesează bucăți de date, cunoscut sub numele de RDDs în timp ce Flink poate procesa rânduri după rânduri de date în timp real. So, în timp ce o latență minimă de date este întotdeauna acolo cu Spark, nu este atât cu Flink.
iterații
Scânteie sprijină iterații de date în loturi, dar Flink poate itera datele sale prin nativ folosind arhitectura de streaming. Imaginea de mai jos arată modul în care are loc prelucrarea iterativ.
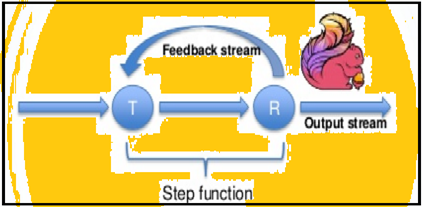
prelucrare iterativ
Managementul memoriei
Flink se poate adapta automat la seturi de date variate, dar Spark are nevoie pentru a optimiza și regla manual locurile de muncă pentru seturile de date individuale. De asemenea, Spark face partiționarea manuală și punerea în cache. So, se așteaptă o anumită întârziere în procesul de prelucrare.
Flux de date
Flink este în măsură să ofere rezultate intermediare cu privire la prelucrarea datelor sale ori de câte ori este necesar. În timp ce Spark urmeaza un sistem de programare procedural, Flink urmează o abordare distribuită a fluxului de date. So, de fiecare dată când rezultatele intermediare sunt necesare, Variabilele de difuzare sunt folosite pentru a distribui rezultatele pre-calculate prin toate nodurile lucrător.
Vizualizarea datelor
Flink oferă o interfață web să prezinte și să execute toate locurile de muncă. Atât Spark și Flink sunt integrate cu Apache Zeppelin și furnizează date ingestie, analiză de date, descoperire, colaborare și vizualizare. Apache Zeppelin oferă, de asemenea, un backend de mai multe limbi, care vă permite să trimiteți și să execute programe Flink.
timp de procesare
Paragrafele de mai jos furnizează o comparație între timpul necesar de Flink și Spark în diferite locuri de muncă.
Pentru a face o comparație echitabilă, atât Flink și Spark s-au dat aceleași resurse sub formă de specificații de mașini și configurații de nod.

configurare nod
Așa cum se arată în imaginea de mai sus, imaginea evidențiată în roșu indică specificațiile utilajului pentru un procesor Flink, în timp ce cel de lângă ea arată că dintr-un procesor Spark.
Așa cum se arată în imaginea de mai sus, zona evidențiată în roșu indică configurația nod pentru un procesor Flink și un procesor Spark.
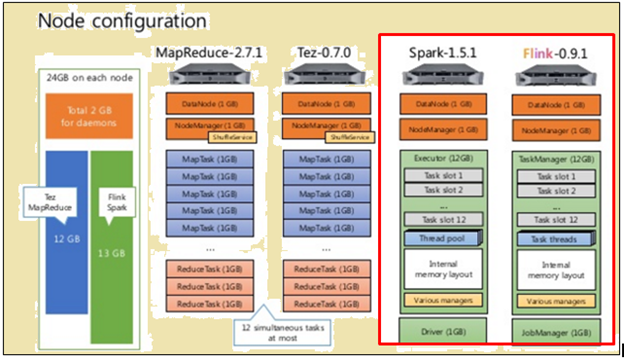
procesor scânteie
Flink procesate mai rapid datorită execuției sale pipeline. Pentru a prelucra datele, scânteie a luat 2171 secunde în timpul Flink au 1490 secunde.
Atunci când s-au efectuat TeraSort cu diverse dimensiuni de date, Următoarele au fost rezultatele:
- Pentru 10 data GB, Flink de ardere 157 secunde în comparație cu Spark 387 secunde.
- Pentru 160 data GB, Flink de ardere 3127 secunde în comparație cu Spark 4927 secunde.
-Lot sau pe bază de streaming de date - proces care este mai bine?
Ambele procese au avantaje și sunt potrivite pentru diferite situații. Cu toate că mulți pretind că instrumentele bazate pe lot sunt de gând de favoare, nu se va întâmpla prea curând. Pentru a înțelege mai avantajele lor relative, vezi următoarea comparație:
| streaming | Sarja |
| Datele sau intrările sosesc sub formă de înregistrări într-o anumită succesiune. | Datele sau intrările sunt împărțite în loturi, pe baza numărului de înregistrări sau de timp. |
| Producția este necesară cât mai curând posibil, dar nu mai devreme decât în momentul în care este necesar pentru verificarea secvenței. | Intrări sunt date pe baza unor cerințe, ci un anumit număr de loturi sunt reținute. |
| De ieșire nu trebuie să fie modificate după cum este scris. | Un nou stat și detalii cu privire la toate rândurile de ieșire sunt înregistrate. |
| Se poate face, de asemenea, lot de prelucrare a datelor | Este în imposibilitatea de a face procesarea datelor de lot |
Există situații individuale în care ambele Flink și prelucrarea pe loturi sunt utile. Să luăm cazul utilizării de calcul vânzări lunare de rulare la intervale de zi cu zi. În această activitate, ceea ce este necesar este de a calcula zilnic totalul vânzărilor și apoi face o sumă cumulativă. Într-un caz de utilizare ca aceasta, poate să nu fie necesară prelucrarea de streaming de date. lot de prelucrare a datelor poate avea grijă de loturile individuale ale cifrelor de vânzări bazate pe datele și apoi adăugați-le. În acest caz, chiar și în cazul în care există o anumită latență de date, care poate fi întotdeauna până mai târziu, atunci când datele latente se adaugă la loturi ulterioare.
Se folosesc în mod similar, cazurile care necesită procesare în flux. Să luăm cazul utilizării de calcul a timpului lunar de rulare fiecare vizitator petrece pe un site. În cazul unui site web, numărul de vizite pot fi actualizate, pe oră, Minute înțelept sau chiar de zi cu zi. Dar problema, în acest caz, este definirea sesiunii. Acesta poate fi dificil să se definească început și de sfârșit a unei sesiuni. Also, este dificil să se calculeze sau de a identifica perioadele de inactivitate. So, în acest caz, nu pot exista limite rezonabile pentru a defini sesiuni sau chiar perioade de inactivitate. În situații ca acestea, este necesară procesarea datelor de streaming pe o bază în timp real.
Summary
Cu toate că Spark are o multime de avantaje atunci când vine vorba de prelucrare a datelor de lot și are încă o mulțime de cazuri de utilizare caters la, se pare că Flink câștigă rapid de tracțiune comercială. Faptul că Flink poate face, de asemenea, de prelucrare a lot pare a fi un lucru imens în favoarea sa. Of course, acest lucru trebuie să fie contabilizate că capacitățile de procesare lot de Flink poate să nu fie în aceeași ligă ca și cea a Spark. So, Scânteie are încă ceva timp.