Преглед: Ние сме добре запознати с особеностите на Hadoop и HDFS. В този документ, ние ще говорим за федерацията HDFS което ни помага да се подобри съществуващата HDFS архитектура. Тя осигурява ясно разграничаване между пространството от имена и съхранение по този начин дава възможност за мащабируемост и изолиране на ниво клъстер.
Въвеждане: Hadoop федерация разделя именни пространства слой и слой за съхранение. Тя дава възможност на слой на блок съхранение. Той също така разширява архитектурата на съществуваща HDFS клъстер, за да позволи на новия внедрявания и случаи на употреба. Сегашната HDFS архитектурата има два слоя -
- Именно пространство - Този слой управлява файлове, директории и блокове. Този слой поддържа операциите основни файловата система например. списък на файловете, създаване на файлове, модификация на файлове и изтриване на файлове и папки.
- Block Storage - Този слой се състои от две части -
- Управление Block Това управлява datanodes в клъстера и предвижда дейности като създаване, заличаване, модификация и търсене. Той също така се грижи за управлението на репликация.
- Физическо Storage Това записва блоковете и осигурява достъп за четене или писане на операции.
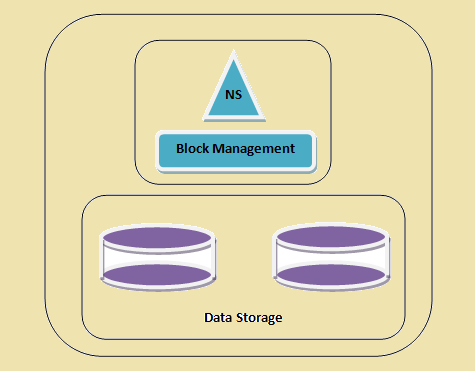
Един клъстер HDFS
Figure 1: Един клъстер HDFS
В настоящата HDFS архитектура, ние имаме само едно пространство от имена за целия клъстер, който се управлява от едно име на възел. Използването на този подход е по-лесно за изпълнение на HDFS клъстера. Това наслояване на архитектура работи добре за малки настройки, докато за по-големи организации, където трябва да се внимава с бързи скорост огромен обем от данни, например. Yahoo и Facebook беше установено, че този подход има някои ограничения, които се обработват от федерацията Hadoop. Така Hadoop федерация може да се дефинира като напреднала архитектурата да се преодолеят ограниченията на текущото изпълнение на HDFS.
Нека се провери ограниченията, както е обяснено по-долу -
- Плътно свързани Block Storage и Именно пространство - В сегашната архитектура съхранение на блок и пространството от имена са плътно свързани, което прави алтернативни приложения на име възли предизвикателни и ограничава други услуги, за да се използва за съхранение на блок директно.
- Именно пространство скалируемост - Клъстерът HDFS везни хоризонтално чрез добавяне datanodes но не можем да добавим повече пространство от имена към съществуващ клъстер хоризонтално. Ние можем да мащабирате именно пространство вертикално на една namenode. The namenode съхранява пълна метаданните на файловата система в рамките на своята памет, която ограничава броя на блокове, файлове и директории, за да бъдат поддържани на файловата система, която трябва да бъде настанен в паметта на единната namenode.
- Производителност - текущите операции на файловата система са ограничени до пропускателната способност на едно име на възел, който в момента опори 60000 едновременни задачи. Но новото идва карта намали от Apache ще има поддръжка за повече от 100000 едновременни задачи и по този начин ще се нуждаят от множество възли.
- Изолация - Като цяло внедрявания HDFS са на разположение на околната среда на мулти-наемател, където един-единствен клъстер се споделя от няколко организации. При тази настройка отделно пространство от имена не е възможно за едно приложение или една организация.
HDFS федерация:
Hadoop федерация позволява мащабиране на услугата име хоризонтално. Тя използва няколко namenodes или пространства от имена, които са независими една от друга. Това са независими namenodes обединената т.е.. те не изискват наред с координацията. Тези datanodes се използват като общо съхранение от всички namenodes. Всеки datanode е регистрирано с всички namenodes в клъстера. Тези datanodes изпращат периодични доклади и отговаря на командите от възлите на името. Имаме блок басейн, който е набор от блокове, които принадлежат към една единствена именно пространство. В един клъстер, блокове datanodes магазини за всички блокови басейни. Всеки блок басейн се управлява независимо. Това дава възможност на пространството име за генериране на блок идентификатори за нови блокове, без да уведоми други пространства от имена. Ако една namenode провали по някаква причина, на datanode продължава да обслужва от други namenodes.
Едно пространство от имена и неговата блок са колективно нарича Именно пространство том. Когато пространството от имена или namenode се изтрива съответния блок басейна в datanode автоматично се изтрива. В процеса на клъстер нагоре-градация, всеки обем пространство от имена е обновен като единица.
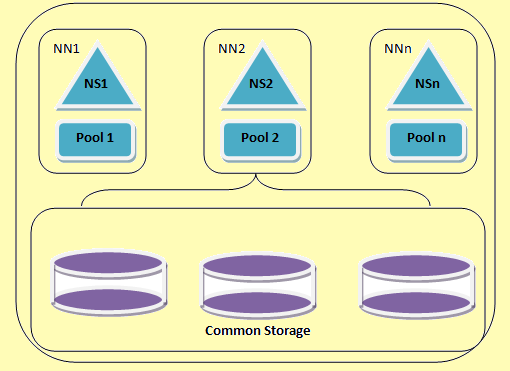
Една федерация архитектура HDFS
Figure 2: Една федерация архитектура HDFS
Предимства на Hadoop федерация:
Hadoop федерация идва с някои предимства и ползи, които са изброени като под -
- Скалируемост и изолация - Множество namenodes хоризонтално везни в пространството от имена на файловата система. Това всъщност разделя обеми именно пространство за потребителите и категории на приложение и осигурява абсолютна изолация.
- Generic услуга за съхранение - черпене на ниво блок басейн позволява архитектурата за изграждане на нови файлови системи на върха на блок съхранение. Можем лесно да се изградят нови приложения на слой на блок за съхранение, без да използвате интерфейса на файловата система. Индивидуално категории блок басейн също могат да бъдат построени, които са различни от блок басейна по подразбиране.
- Прост дизайн - Namenodes и именни пространства са независими един от друг. Едва ли има сценарий, който изисква промяна на съществуващите възли име. Всяко име на възел е построен, за да бъде здрав. Федерация също е обратно съвместим. Тя лесно се интегрира със съществуващите един възел внедрявания, които работят без каквито и да било промени в конфигурацията.
Конфигуриране на HDFS федерация:
Конфигурация на Hadoop федерация е проектирана по такъв начин, че всички възли в клъстера имат същата конфигурация. Конфигурацията се извършва в следните етапи -
- Step 1 - Следните параметри трябва да се добави в съществуващата конфигурация -
- nameservices - Това е конфигуриран със списък от разделени със запетая NameServiceIDs. Този параметър се използва от Datanodes да определи всички namenodes в клъстера.
- Step 2 - Следните конфигурации трябва да се суфикс със съответното име услуга ID в общия конфигурационен файл.
- Namenode
- Secondary NameNode
- BackupNode
А конфигурация проба файл за две namenodes е показано по-долу -
Listing 1: А конфигурация Примерен файл за два възела
[Code]
<конфигурация>
<имот>
<име>dfs.nameservices</име>
<стойност>NS1, ns2</стойност>
</имот>
<имот>
<име>dfs.namenode.rpc-address.ns1</име>
<стойност>NN-хост1:6600</стойност>
</имот>
<имот>
<име>dfs.namenode.http-address.ns1</име>
<стойност>NN-хост1:8080</стойност>
</имот>
<имот>
<име>dfs.namenode.secondaryhttp-address.ns1</име>
<стойност>NHS-хост1:8080</стойност>
</имот>
<имот>
<име>dfs.namenode.rpc-address.ns2</име>
<стойност>NN-HOST2:6600</стойност>
</имот>
<имот>
<име>dfs.namenode.http-address.ns2</име>
<стойност>NN-HOST2:8080</стойност>
</имот>
<имот>
<име>dfs.namenode.secondaryhttp-address.ns2</име>
<стойност>NHS-HOST2:8080</стойност>
</имот>
</конфигурация>
[/Code]
Форматирането на Namenode: Нека командите до формат namenode.
- Step 1 – Един единствен възел име може да се форматира като се използва следната -
$HADOOP_USER_HOME / хамбар / hdfs namenode -format [-ClusterId <cluster_id>]
Идентификационният номер на клъстер трябва да е уникален и не трябва да противоречат на всякаква друга излизане клъстер ID. Ако не е предвидено, уникален ID клъстер се генерира по време на форматиране.
- Step 2 - Допълнителна namenode може да се форматира като се използва следната команда -
$HADOOP_PREFIX_HOME / хамбар / hdfs namenode -format -clusterId <cluster_id>
Той е тук, важно, че идентификационният номер на клъстер споменато тук трябва да бъдат еднакви за които се споменава в стъпка 1. Ако тези две са различни, допълнителната namenode няма да бъде част от обединената клъстера.
Пускането и спирането на клъстера: Нека се провери командите за пускане и спиране на клъстера.
- Започнете клъстера - Клъстерът може да се стартира от изпълнението на следната команда -
$HADOOP_PREFIX_HOME / хамбар / start-dfs.sh
- Спрете клъстера - Клъстерът може да бъде спрян, като изпълнява следната команда -
$HADOOP_PREFIX_HOME / хамбар / start-dfs.sh
Добавяне на нова namenode към съществуващ клъстер: Ние вече е описано, че множествената възел име е в основата на Hadoop федерация. Така че е важно да се разбере стъпките за добавяне на нови възли име и мащабират хоризонтално.
Необходими са следните стъпки, за да добавите нови namenodes -
- конфигурационния параметър - nameservices трябва да се добави в конфигурацията.
- NameServiceID трябва да се суфикс в конфигурацията
- трябва да се добави New Namenode свързани с довереник в конфигурационните файлове.
- Конфигурационният файл трябва да бъде размножен за всички възли в клъстера.
- Започнете новия namenode и вторичния namenode
- Обнови другите datanodes да вземем новодобавения namenode като пуснете следната команда -
о $ HADOOP_PREFIX_HOME / хамбар / hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
- Тази команда трябва да бъде изпълнена от всички datanodes на клъстера.
Summary: HDFS федерация е въведено, за да се преодолеят ограниченията на по-рано изпълнение HDFS. Добавянето мащабируемост в пространството от имена слой е най-важната характеристика на HDFS федерация архитектура. Но HDFS федерация също е обратно съвместим, така конфигурацията на единния namenode също ще работи без никакви промени.
Нека обобщим нашата дискусия под формата на следните куршуми
- HDFS федерация разделя namenode слой и слой за съхранение.
- HDFS федерация има за цел да се преодолеят ограниченията на един възел HDFS архитектура, където съхранението може да мащабирате до хоризонтално не пространството от имена.
- HDFS федерация идва със следните предимства -
- изолация
- Scalability
- Обикновено Design
- HDFS конфигурация е много проста и е също така лесно да се управлява.