Преглед: С толкова много рамки за развитие по целия, тя става важно, че ние трябва да сме в състояние да увеличи нашето заявление във всеки даден момент от време. Машина техники като клъстери и категоризация учене са станали популярни в този контекст. Apache и дресура е рамка, която ни помага да постигнем мащабируемост.
In this document, Аз ще говоря за Apache и дресура и нейното значение.
Въвеждане: Apache и дресура е проект с отворен код от Apache Foundation софтуер или ASF която има за основна цел създаване на живот алгоритъм машина. Въведена от група разработчици от проекта на Apache Lucene, Apache и дресура има за цел да -
- Изграждане и поддържане на общност от потребители или сътрудници, така че достъп до изходния код на рамката не се ограничава до една малка група от разработчици.
- Съсредоточете се върху практическите проблеми, отколкото невидими или недоказани проблеми.
- Осигуряване на подходяща документация.
Характеристики на Apache и дресура:
Apache и дресура идва с набор от възможности и функции, особено когато говорим за групиране и Collaborative Filtering. Най-важните характеристики са посочени като под -
- Вкус Collaborative Filtering - вкус е проект с отворен код за съвместна филтриране. Това е част от рамката за дресура, който предвижда за машинно обучение алгоритми, за да увеличат нашите приложения. Вкус се използва за лични препоръки. Тези дни, когато ние се отварят уеб сайт, ние намерите много препоръки, свързани с уеб сайт, който ние в момента разглеждат. Следващата фигура показва архитектура диаграмата на Taste -
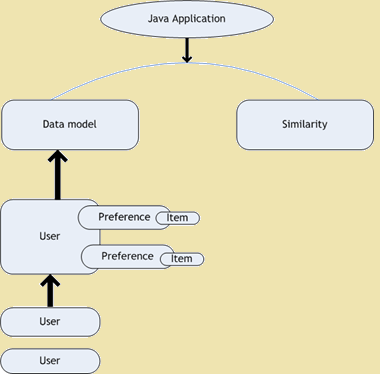
Вкус Архитектура диаграма
Figure 1: Вкус Архитектура диаграма
- Карта намали активирани приложения - Няколко карта намаляват активирани скупчени реализации се поддържат в дресура. Това включва К-средната, бухнал, навес
- Distributed Navie Bayes and Complimentary Navie Bayes – Apache дресура има прилагането на двете Navie Бейс и Безплатно Бейс. За простота Navie Бейс са посочени като Бейс и Безплатно са посочени като CBayes. Бейс се използват в текст класификация докато CBayes са разширение на Бейс, които се използват в случай на "Набори данни".
- Той поддържа Matrix и други свързани с векторни библиотеки.
Създаване на Apache и дресура:
Създаване на Apache и дресура е много проста и може да се извършва в следните етапи -
- Step 1 - За да настроите Apache и дресура, трябва да имаме приложения инсталирани -
- JDK 1.6 or higher
- Мравка 1.7 or higher
- Maven 2.9 или по-висока - В случай, че искате да се изгради от изходния код
- Step 2 - Разархивирайте файла, sample.zip и копирате съдържанието в някои папка каже "Apache-дресура-примери".
- Step 3 - Отидете в папката - "Apache-дресура-примери" и изпълнете следното -
- мравка инсталиране
Последната стъпка изтегля Уикипедия файлове и компилира кода.
Препоръка двигател:
Препоръка на двигателя е подклас на информация филтрираща система, която може да се предскаже рейтинг или предпочитания потребителя може да даде на даден елемент. Дресура предоставя инструменти и техники, които са полезни за изграждане на препоръка двигатели, използващи библиотеката "Вкус". Използването Вкус библиотека можем да се изгради бързо и гъвкаво Collaborative Filtering двигателя. Вкус се състои от следните пет основни компонента, които работят с потребители, елементи и предпочитания -
- Модел на данни - Това се използва като система за съхранение на потребителите, предмети, както и предпочитанията.
- Потребителят Прилика - Това е интерфейс, използван за определяне на сходство между двама потребители.
- Точка Прилика - Интерфейс, който се използва за определяне на сходство между две точки.
- препоръчване - Един интерфейс, който се използва за предоставяне на препоръки.
- Потребителят Neighborhood - Един интерфейс, който се използва, за да се изчисли и да се изчисли един квартал на потребителите на една и съща категория, които могат да бъдат използвани от препоръчители.
С помощта на тези компоненти и техните реализации, ние може да се изгради комплекс препоръка система. Тази препоръка на двигателя може да се използва и в двете препоръки реално време и офлайн препоръки. препоръки в реално време могат да се справят потребители до няколко хиляди, докато препоръките на офлайн могат да се справят потребители в много по-голям брой.
Групиране:
Дресура поддържа много механизми клъстерни. Тези алгоритми са написани на картата намали. Всеки един от тези алгоритми има свой собствен набор от цели и критерии. Най-важните от тях са включени в списъка под -
- Козирка - Това е най-алгоритъм бързо групиране използва за създаване на първоначалните семена за други клъстерни алгоритми.
- к – Средства или размита к – означава - Този алгоритъм създава к клъстери, базирани на разстоянието от елементите, от центъра на предходната итерация.
- Средните - Shift - Този алгоритъм не изисква никаква предварителна информация за броя на клъстерите. Това може да доведе до произволно клъстер, който може да се увеличава или намалява, както на нашата нужда.
- Дирихле - Този алгоритъм създава клъстери чрез комбиниране на един или повече модели касетъчни. По този начин ние получаваме предимство, за да изберете най-добрия възможен един от редица клъстери.
Извън посочените по-горе четири алгоритмите вписана, най-често се използва е K - означава алгоритъм. Да е всяко групиране алгоритъм, ние трябва да изпълните следните стъпки -
- Подгответе входа. If required, конвертиране на текст в цифров представителство.
- Изпълнение на алгоритъм по ваш избор, като използвате някой от готовите програми Hadoop достъпно в дресура.
- Правилно оценка на резултатите.
- Преминаване тези стъпки, ако е необходимо.
Content Окачествяването:
Apache и дресура поддържа следните два подхода за категоризиране или класифициране на съдържанието. Те се основават главно на Бейс статистика -
- Първият подход е право напред Карта намаляват активиран Navie Бейс класификатор. Класификатори на тази категория се знае, че бързо и точно, въпреки че предположението, че данните са напълно независими. Тези класификатори разграждат, когато размерът на данните върви нагоре или данни става взаимозависимо. Navie Бейс класификатор е процес от две части, която поддържа запис на характеристиките или просто думи, които са свързани с документ. Тази стъпка е известен като обучение, което също създава модел, като погледнете в примери за вече класифицирани съдържание. Втората стъпка, известен като класификация, използва моделът, който е създаден по време на обучението и съдържанието на нов, невидим документ. следователно, за да стартирате класификатор и дресура на, ние първо трябва да се обучават на модела и след това да използвате модела за класифициране на ново съдържание.
- Вторият подход, който е известен също като допълнителни Наивно Бейс, се опитва да поправи някои от въпросите, с нелекувана подхода на Бейс и все още запазва простотата и скоростта, предлагана от Navie Бейс.
Стартиране на Navie Бейс класификатор:
The Navie Бейс класификатор изисква изпълнението на следните мравка цели, за да се изпълни -
- мравка подготви-Документи - Това подготвя набор от документи, които са необходими за обучение.
- мравка подготви опити Документи - Това подготвя набор от документи, които са необходими за тестване.
- мравка влак - След като данните за обучение и анализите са посочени, ние трябва да тече клас TrainClassifier използване на целта - "мравка влака".
- мравка тест - След като горните цели са изпълнени успешно, ние трябва да се изпълнява тази цел, която отнема входни проба документи и се опитва да ги класифицира въз основа на модела, който е създаден по време на тренировка.
Summary: В тази статия ние видяхме, че Apache и дресура се използва широко за текст класифициране с използване на машина за учене алгоритми. Технологията е все още расте и може да се използва за различни видове разработка на приложения. Нека обобщим нашата дискусия под формата на следната куршуми -
- Apache и дресура е проект с отворен код от Apache, въведена с група от разработчици от проекта на Apache Lucene. Основната цел на този проект е да се създаде алгоритъм, който може да чете машинен език.
- Apache и дресура има следните важни характеристики -
- Вкус Collaborative Filtering.
- MapReduce активиран реализации.
- Изпълнение и за двете Разпределени Navie Бейс и Безплатно Navie Бейс.
- Поддържа матрица и други свързани с вектор, базирани библиотеки.