
Apache Spark і Big Data,,en,становіцца адным з найбольш важных актываў можа валодаць прадпрыемства,,en,кампаніі маюць патрэбу ў адпаведных рамках,,en,Тэхналогіі і інструменты,,en,Стромкія чаканні ад вялікіх дадзеных будуць вызначаць адносіны паміж прадпрыемствамі і дадзенымі,,en,Apache Spark забяспечвае аснову для выканання шматпланавых дзеянняў, такіх як апрацоўка,,en,запытаў і генерацыі аналітыку на высокіх хуткасцях і глядзіць у будучыню,,en,ўяўляецца верагодным, што Apache Spark будзе самай папулярнай платформай для вялікіх дадзеных,,en,Важны фактар у гэтым кантэксце з'яўляецца Apache Spark з'яўляецца адкрытым зыходным кодам, які павышае яго прывабнасць ў астатнім дарагі фірмовай тэхналогіі рынак,,en,Apache Спарк разглядаецца ў якасці канкурэнта ці пераемніка,,en,Ёсць некаторыя эксперты, якія да гэтага часу лічаць,,en
Агляд:
As big data becomes one of the most important assets an enterprise can possess, enterprises are demanding more out of the data. Enterprises expect data to provide complex and multidimensional insights at high speeds. To provide such insights, companies need appropriate framework, technologies and tools. Steep expectations from big data are going to define the relationship between enterprises and data. Apache Spark provides the framework to perform multidimensional actions such as processing, querying and generating analytics at high speeds and looking at the future, it seems likely that Apache Spark is going to be the most popular platform for big data. An important factor in this context is Apache Spark is an open source framework which increases its appeal in an otherwise expensive proprietary technology market. Apache Spark is seen as a competitor or successor to MapReduce. There are some experts who still consider Spark рамкі на сваіх пачатковых этапах, і ён можа цяпер падтрымліваць толькі пару аператыўнай аналітыкі,,en,Кантэкст для Apache Спарк,,en,Apache Спарк паўстала ў той час, калі прадпрыемствы чакаюць дадзеныя, якія яны павінны прапанаваць больш, але абмежаваныя некалькімі фактарамі,,en,Кампаніі сутыкаюцца з праблемамі на некалькі франтах, такія як неадэкватная аснова і тэхналогіі,,en,дарагая тэхналогія і недахоп кваліфікаваных кадраў,,en,Разгледзім гэтыя праблемы трохі больш цесна,,en,неадэкватныя рамкі,,en,У фреймворка не могуць апрацоўваць дадзеныя з высокай ступенню эфектыўнасці,,en,крос-платформавая сумяшчальнасць і запыты ўсе,,en,у той ці іншай ступені,,en,праблемы, звязаныя з бягучымі Фреймвоки,,en,чаканні ад дадзеных становяцца ўсё больш разнастайнымі,,en,складаны і шматгранны,,en.
Context for Apache Spark
Apache Spark has emerged at a time when the enterprises expect the data they have to offer more but are constrained by several factors. Enterprises are facing problems on several fronts such as inadequate framework and technology, expensive technology and lack of skilled personnel. Let us examine these problems a little bit more closely.
Inadequate framework
The frameworks available are unable to process data with a high degree of efficiency. Speed, cross-platform compatibility and querying are all, in varying degrees, issues with current software frameworks. With time, the expectations from data are becoming more varied, complex and multidimensional. Гэта стварае разрыў паміж чаканнямі і магчымасцямі,,en,Высокі кошт праграмнага забеспячэння,,en,Кошт прапрыетарнага праграмнага забеспячэння або структуры з'яўляюцца забароннымі і што стварае эксклюзіўны клуб, таму што сярэдняга памеру для невялікіх кампаній, не могуць набываць і абнаўляць ліцэнзіі,,en,Толькі буйныя кампаніі з глыбокімі кішэнямі можа дазволіць сабе такія выдаткі, што азначае, што невялікія кампаніі па-ранейшаму пазбаўленыя больш высокіх магчымасцяў апрацоўкі дадзеных,,en,несумяшчальнасць,,en,Даступныя мадэлі маюць праблемы сумяшчальнасці з іншымі інструментамі,,en,MapReduce працуе толькі на,,en,Калі справа даходзіць да аналітыкі платформаў,,en,Спарк забяспечвае багацце рэсурсаў,,en,ён мае,,en,бібліятэка для машыннага навучання,,en,Інтэрфейсы прыкладнога праграмавання,,en,для графа аналітыка,,en,таксама вядомы як Graphx,,en,Падтрымка SQL-запытаў на аснове,,en,струменевае і дадатку,,en
High cost of software
Costs of proprietary software or framework are prohibitive and that is creating an exclusive club because mid-sized to small companies are unable to purchase and renew the licenses. Only big companies with deep pockets can afford such expenses which means that smaller companies remain deprived of the higher data processing capabilities.
Incompatibility
The available frameworks have compatibility issues with other tools. For example, MapReduce runs only on Hadoop. Spark does not have such compatibility issues. It can run on any resource manager such as прадзівам or Mesos.
Reasons Apache Spark is the future platform for big data
When you want reasons Apache Spark is the future platform for big data, it is kind of inevitable to compare Spark with Hadoop. Hadoop is still the most favorite big data processing framework and there had better be good reasons Spark replaces Hadoop. So here are a few reasons Spark is considered the future.
Efficient handling of iterative algorithms
Spark is great at handling programming models involving iterations, interactivity that includes streaming and much more. On the other hand, MapReduce displays several inefficiencies in handling iterative algorithms. That is a big reason Apache Spark is considered a prime replacement for MapReduce.
Spark provides analytics workflows
When it comes to analytics platforms, Spark provides a wealth of resources. It has, напрыклад, library for machine learning (MLlib), Application Programming Interfaces (API-інтэрфейсы) for graph analytics, also known as GraphX, support for SQL-based querying, streaming and applications. Усе яны ўяўляюць сабой комплексную аналітычную платформу,,en,Па словах Яна Lumb Брайт Computing,,en,«Рабочыя працэсы могуць выконвацца ў пакетным рэжыме або ў рэжыме рэальнага часу з дапамогай убудаваных у інтэрактыўных падтрымкі абалонак даступныя ў Scala і,,en,Паколькі пакет заўважнай статыстыкі,,en,ўжо адзін з дадатковых праектаў,,en,Стэк аналітыка іскры з вельмі ўсёабдымны,,en,Іскра можа атрымаць доступ да любога крыніцы дадзеных Hadoop - ад,,en,і іншыя файлавыя сістэмы,,en,да баз дадзеных, як Apache,,en,і Apache,,en,Такім чынам, дадзеныя, якія адбываюцца з Hadoop могуць быць уключаны ў Спарк прыкладанняў і рабочых працэсаў «.,,en,Палепшанае кіраванне памяццю,,en,У нядаўнім даследаванні бенчмаркетынгу на ў памяці захоўвання двайковых дадзеных,,en,было выяўлена, што Спарк абагнаў Hadoop на 20x фактару,,en,Гэта таму, што Спарк прапануе,,en,Алан Lumb Светлай Computing дадае,,en. According to Ian Lumb of Bright Computing, “Workflows can be executed in a batch mode or in real time using the built-in interactive shell support available in Scala and пітон. Because the notable stats package R is already one of the supplemental projects, Spark’s analytics stack is quite comprehensive. Spark can access any Hadoop data source – from HDFS (and other file systems) to databases like Apache HBase and Apache Cassandra. Thus data originating from Hadoop can be incorporated into Spark applications and workflows.”
Better memory management
In a recent benchmarking study on in-memory storage of binary data, it was discovered that Spark outperformed Hadoop by 20x factor. This is because Spark offers the Resilient Distributed Datasets (RDDs). Alan Lumb of Bright Computing adds, «РДУ з'яўляюцца адмоваўстойлівасці,,en,паралельныя структуры дадзеных ідэальна падыходзяць для кластарных вылічэнняў у аператыўнай памяці,,en,У адпаведнасці з парадыгмай Hadoop,,en,РД можа захоўвацца і быць падзелены праз інфраструктуру вялікіх дадзеных забяспечвае, што дадзеныя аптымальна размясціць,,en,РД можна маніпуляваць, выкарыстоўваючы багаты набор аператараў. »Такім чынам, з больш эфектыўным выкарыстаннем памяці,,en,прадпрыемствы могуць разлічваць на больш рацыянальнае выкарыстанне рэсурсаў і значнай эканоміі сродкаў,,en,лепшыя вынікі,,en,У лепшым выпадку для Hadoop,,en,Іскра біць Hadoop на 20x фактар,,en,Глядзіце малюнак ніжэй,,en,гэта паказвае, што Спарк біць Hadoop, нават калі памяць недаступная, і ён павінен выкарыстоўваць свае дыскі,,en,Згодна з Спарк сайце Apache,,en,Іскра можа «Запуск праграмы да 100x хутчэй, чым Hadoop MapReduce ў памяці,,en, parallel data structures ideally suited to in-memory cluster computing. Consistent with the Hadoop paradigm, RDDs can persist and be partitioned across a Big Data infrastructure ensuring that data is optimally placed. And, of course, RDDs can be manipulated using a rich set of operators.” So with better memory utilization, enterprises can look forward to better resource management and significant cost savings.
Better results
In a best-case scenario for Hadoop, Spark beat Hadoop by a 20x factor. See the image below, it shows that Spark beat Hadoop even when memory is unavailable and it has to use its disks.
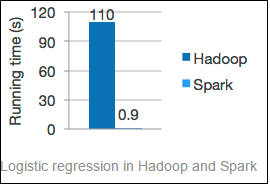
Спарк і параўнанне Hadoop,,en,techalpine.com/why-apache-spark-is-the-future-platform-for-big-data/spark-and-hadoop-comparison,,en
According to the Spark Apache website, Spark can “Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. Свечка мае пашыраны механізм выканання DAG, які падтрымлівае цыклічны струмень дадзеных і ў памяці вылічэнняў «.,,en,усеагульнасць,,en,Іскра можа аб'яднаць струменевае,,en,SQL,,en,і складаныя аналітычныя,,en,Гэта можа прывесці стэк бібліятэк, якія ўключаюць у сябе SQL,,en,Graphx,,en,MLlib для машыннага навучання і DataFrames,,en,і Спарк Streaming,,en,Вы можаце аб'яднаць усе гэтыя бібліятэкі лёгка ў адным дадатку,,en,Іскра можа працаваць усюды,,en,Іскра можа працаваць на Mesos,,en,аўтаномны,,en,або ў воблаку,,en,Ён таксама можа атрымаць доступ да разнастайных крыніц дадзеных, пералік якіх уключае ў сябе Касандра,,en,і S3,,en,значнае паглынанне,,en,Іскра можа паставіць наяўныя рэсурсы для больш эфектыўнага выкарыстання,,en,яркае вылічэнні,,en,якая прадастаўляе праграмныя рашэнні для разгортвання і кіравання вялікімі кластарамі дадзеных і ГПЦ і OpenStack ў цэнтры апрацоўкі дадзеных і ў воблаку,,en,адзначае,,en,«Іскра,,en,быў выпушчаны ў сярэдзіне снежня,,en,камітаў былі зробленыя,,en
Generality
Spark can combine streaming, SQL, and complex analytics. It can power a stack of libraries that include SQL, GraphX, MLlib for machine learning and DataFrames, and Spark Streaming. You can combine all these libraries seamlessly within the same application.
Spark can run everywhere
Spark can run on Mesos, standalone, Hadoop, or in the cloud. It can also access diverse data sources the list of which includes Cassandra, HDFS, HBase, and S3.
Significant uptake
Spark can put available resources to better use. Bright computing, which provides software solutions for deploying and managing big data clusters and HPC and OpenStack in the data center and in the cloud, observes, “Spark 1.2.0 was released in mid-December 2014. Over 1,000 commits were made by the 172 Распрацоўшчыкі якія спрыяюць гэтай версіі - гэта больш чым у 3 раз лік распрацоўшчыкаў, якія ўнеслі свой уклад у папярэднюю версію,,en,Спарк 1.1.1. »Дасягненні іскры ляжаць у тым, што яна можа ўключаць у сябе цэлую супольнасць распрацоўнікаў праграмнага забеспячэння ў садзейнічанні,,en,У той час як ёсць шмат пазітыўных эмоцый аб Спарк,,en,яна па-ранейшаму павінна быць разгорнута на прадпрыемствах і выпадкі выкарыстання павінны быць правераны,,en,тэарэтычна,,en,асаблівасці і магчымасці ўражваюць, і ён абяцае даставіць шмат,,en,techalpine.com/why-apache-spark-is-the-future-platform-for-big-data,,en, Spark 1.1.1.” Spark’s achievements lie in the fact that it can involve the whole community of software developers into contributing.
Summary
While there are a lot of positive vibes about Spark, it still needs to be deployed across enterprises and the use cases need to be tested. Theoretically, the features and capabilities are impressive and it promises to deliver a lot.