Nhu cầu xử lý dữ liệu nhanh hơn đã được tăng và thời gian thực chế biến luồng dữ liệu dường như là câu trả lời. Trong khi Apache Spark vẫn đang được sử dụng trong rất nhiều các tổ chức cho xử lý dữ liệu lớn, Apache Flink đã được mọc lên nhanh như một sự thay thế. thực tế, nhiều người nghĩ rằng nó có tiềm năng để thay thế Apache Spark bởi vì khả năng của nó để xử lý luồng dữ liệu theo thời gian thực. Of course, ban giám khảo về việc liệu có thể thay thế Flink Spark vẫn ra vì Flink là chưa được đưa vào thử nghiệm rộng rãi. Nhưng chế biến thời gian và độ trễ dữ liệu thấp là hai đặc tính rõ nét của nó. At the same time, điều này cần phải được xem xét rằng Apache Spark có thể sẽ không đi ra khỏi lợi vì khả năng xử lý hàng loạt của nó sẽ vẫn có liên quan.
Trường hợp cho streaming Xử lý dữ liệu
Đối với tất cả các giá trị của hàng loạt chế biến dựa trên, có vẻ như là một trường hợp mạnh mẽ để xử lý phát dữ liệu theo thời gian thực. Luồng xử lý dữ liệu làm cho nó có thể cài đặt và tải một kho dữ liệu một cách nhanh chóng. Một bộ xử lý trực tuyến mà có độ trễ dữ liệu thấp cho thêm chi tiết về dữ liệu một cách nhanh chóng. So, bạn có nhiều thời gian hơn để tìm hiểu những gì đang xảy ra. Ngoài xử lý nhanh hơn, đó cũng là một lợi ích đáng kể: bạn có nhiều thời gian để thiết kế một phản ứng thích hợp với các sự kiện. For example, trong trường hợp phát hiện bất thường, độ trễ thấp hơn và phát hiện nhanh hơn cho phép bạn xác định các phản ứng tốt nhất đó là chìa khóa để ngăn chặn thiệt hại trong trường hợp như các cuộc tấn công lừa đảo trên một trang web an toàn hoặc hư hỏng thiết bị công nghiệp. So, bạn có thể ngăn chặn sự mất mát đáng kể.
Apache Flink là gì?
Apache Flink là một công cụ xử lý dữ liệu lớn và nó được biết để xử lý dữ liệu lớn một cách nhanh chóng với độ trễ dữ liệu thấp và khả năng chịu lỗi cao trên các hệ thống phân phối trên một quy mô lớn. Tính năng xác định của nó là khả năng xử lý dữ liệu trực tuyến trong thời gian thực.
Apache Flink bắt đầu như là một dự án mã nguồn mở học tập và trở lại sau đó, nó được gọi là Stratosphere. Later, nó đã trở thành một phần của lồng ấp Apache Software Foundation. Để tránh xung đột trong tên với một dự án khác, tên đã được thay đổi để Flink. Tên Flink là thích hợp vì nó có nghĩa là nhanh nhẹn. Ngay cả biểu tượng được chọn, một con sóc là thích hợp vì một con sóc đại diện cho các nhân đức của sự nhanh nhẹn, nhanh nhẹn và tốc độ.
Kể từ khi được bổ sung vào Apache Software Foundation, nó đã có một sự gia tăng khá nhanh chóng như một công cụ xử lý dữ liệu lớn và trong vòng 8 tháng, nó đã bắt đầu để nắm bắt sự chú ý của khán giả rộng lớn hơn. tâm ngày càng tăng của người dân trong Flink đã được phản ánh trong số những người tham dự trong một số cuộc họp trong 2015. Một số người tham dự cuộc họp trên Flink tại Hội nghị Strata tại London tháng năm 2015 và Hội nghị Thượng đỉnh Hadoop ở San Jose vào tháng Sáu, 2015. Nhiều hơn 60 người tham dự Bay Area Apache Flink đáp ứng-up tổ chức tại trụ sở MapR ở San Jose vào tháng, 2015.
Những hình ảnh dưới đây cho phép các kiến trúc Lambda của Flink.
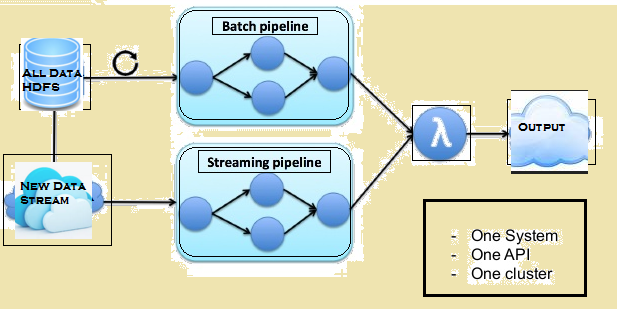
Lambda kiến trúc của Flink
So sánh giữa Spark và Flink
Mặc dù có một vài điểm tương đồng giữa Spark và Flink, ví dụ, API và các thành phần của họ, sự tương đồng không quan trọng nhiều khi nói đến xử lý dữ liệu. Đưa ra dưới đây là một so sánh giữa Flink và Spark.
Xử lí dữ liệu
Spark xử lý dữ liệu trong chế độ hàng loạt trong khi Flink xử lý luồng dữ liệu theo thời gian thực. Spark xử lý khối dữ liệu, được gọi là RDDs khi Flink có thể xử lý các hàng sau khi hàng dữ liệu trong thời gian thực. So, trong khi một độ trễ dữ liệu tối thiểu là luôn luôn ở đó với Spark, nó không phải là như vậy với Flink.
lặp đi lặp lại
Spark hỗ trợ lặp dữ liệu theo lô cũng Flink nguyên bản có thể lặp dữ liệu của mình bằng cách sử dụng kiến trúc trực tuyến của nó. Hình ảnh dưới đây cho thấy cách lặp đi lặp lại việc chế biến thực.
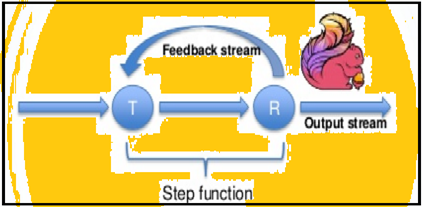
xử lý lặp đi lặp lại
Quản lý bộ nhớ
Flink có thể tự động thích ứng với bộ dữ liệu đa dạng nhưng Spark cần để tối ưu hóa và điều chỉnh công việc của mình bằng tay để bộ dữ liệu cá nhân. Cũng Spark không phân vùng bằng tay và bộ nhớ đệm. So, mong đợi một số chậm trễ trong việc xử lý.
Dòng dữ liệu
Flink có thể cung cấp kết quả trung gian về xử lý dữ liệu của mình bất cứ khi nào cần thiết. Trong khi Spark sau một hệ thống lập trình thủ tục, Flink sau một cách tiếp cận dòng chảy dữ liệu phân tán. So, bất cứ khi nào kết quả trung gian được yêu cầu, biến phát sóng được sử dụng để phân phối các kết quả tính trước cho đến tất cả các nút công nhân.
Hình ảnh dữ liệu
Flink cung cấp một giao diện web để nộp và thực hiện tất cả các công việc. Cả hai Spark và Flink được tích hợp với Apache Zeppelin và cung cấp dữ liệu tiêu hóa, phân tích dữ liệu, khám phá, phối hợp và trực quan. Apache Zeppelin cũng cung cấp một phụ trợ đa ngôn ngữ cho phép bạn gửi và thực hiện các chương trình Flink.
Thời gian xử lý
Các đoạn dưới đây cung cấp một so sánh giữa thời gian thực hiện bởi Flink và Spark trong công việc khác nhau.
Để thực hiện một so sánh công bằng, cả Flink và Spark được cho các nguồn lực như nhau trong các hình thức của thông số kỹ thuật máy tính và cấu hình nút.

cấu hình Node
Như thể hiện trong hình trên, hình ảnh đánh dấu màu đỏ chỉ ra các thông số kỹ thuật máy tính cho một bộ xử lý Flink trong khi một bên cạnh nó cho thấy rằng một bộ xử lý Spark.
Như thể hiện trong hình trên, vùng được đánh dấu màu đỏ chỉ ra cấu hình nút cho một bộ xử lý Flink và một bộ xử lý Spark.
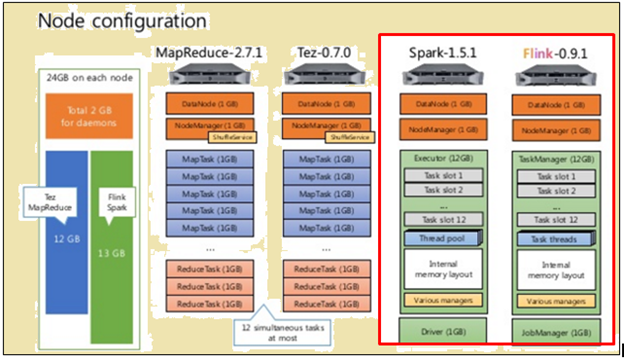
xử lý Spark
Flink xử lý nhanh hơn vì thực pipelined của nó. Để xử lý dữ liệu, Spark mất 2171 giây trong khi Flink mất 1490 giây.
Khi TeraSort với kích thước dữ liệu khác nhau đã được thực hiện, Sau đây là kết quả:
- vì 10 ngày GB, Flink bắn 157 giây so với Spark của 387 giây.
- vì 160 ngày GB, Flink bắn 3127 giây so với Spark của 4927 giây.
Batch-dựa hoặc Luồng dữ liệu - mà quá trình là tốt hơn?
Cả hai quá trình có những thuận lợi và phù hợp cho các tình huống khác nhau. Mặc dù nhiều người cho rằng công cụ hàng loạt dựa trên đang được ưa chuộng, nó sẽ không xảy ra bất cứ lúc nào sớm. Để hiểu được lợi thế tương đối của chúng, thấy sự so sánh sau đây:
| truyền | Trạm trộn |
| Dữ liệu hoặc các đầu vào đến trong các hình thức ghi trong một chuỗi cụ thể. | Dữ liệu hoặc các đầu vào được chia thành lô dựa trên số lượng hồ sơ hoặc thời gian. |
| Đầu ra là cần thiết càng sớm càng tốt nhưng không sớm hơn so với thời gian cần thiết để xác minh các chuỗi. | Đầu vào được đưa ra dựa trên các yêu cầu nhưng một số lượng nhất định các lô được giữ lại. |
| Đầu ra không cần phải được sửa đổi sau khi nó được viết. | Một nhà nước mới và các chi tiết của tất cả các hàng của các đầu ra được ghi nhận. |
| cũng có thể làm chế biến hàng loạt dữ liệu | Là không thể làm chế biến hàng loạt dữ liệu |
Có những tình huống cá nhân, trong đó cả hai Flink và xử lý hàng loạt có ích. Lấy trường hợp sử dụng các tính toán doanh số bán hàng tháng cán trong khoảng thời gian hàng ngày. Trong hoạt động này, điều cần thiết là phải tính toán tổng doanh thu hàng ngày và sau đó làm cho một số tiền tích lũy. Trong một trường hợp sử dụng như thế này, xử lý trực tuyến các dữ liệu có thể không được yêu cầu. Xử lý hàng loạt các dữ liệu có thể chăm sóc của các lô cá nhân của con số bán hàng dựa trên ngày và sau đó thêm chúng. Trong trường hợp này, thậm chí nếu có một số độ trễ dữ liệu, mà luôn luôn có thể được tạo thành sau khi dữ liệu tiềm ẩn sẽ được thêm vào các mẻ sau.
Có tương tự được sử dụng trường hợp phải xử lý phát. Lấy trường hợp sử dụng các tính toán thời gian hàng tháng cán mỗi khách truy cập vào một trang web. Trong trường hợp của một trang web, số lần truy cập có thể được cập nhật, từng giờ, phút-khôn ngoan hoặc thậm chí hàng ngày. Nhưng vấn đề trong trường hợp này được xác định phiên. Nó có thể là khó khăn để xác định điểm bắt đầu và kết thúc của một phiên. Also, rất khó để tính toán hoặc xác định các giai đoạn không hoạt động. So, trong trường hợp này, có thể là không có ranh giới hợp lý để xác định phiên hoặc thậm chí thời gian không hoạt động. Trong những tình huống như thế này, xử lý dữ liệu trực tuyến trên cơ sở thời gian thực là cần thiết.
Summary
Mặc dù Spark có rất nhiều lợi thế khi nói đến xử lý dữ liệu hàng loạt và nó vẫn có rất nhiều trường hợp sử dụng nó phục vụ cho, nó xuất hiện rằng Flink đang nhanh chóng đạt được lực kéo thương mại. Thực tế là Flink cũng có thể làm hàng loạt chế biến có vẻ là một điều rất lớn trong lợi của mình. Of course, điều này cần phải được hạch toán cho rằng khả năng xử lý hàng loạt của Flink thể không được ở cùng một giải đấu như của Spark. So, Spark vẫn có một số thời gian.