A demanda de procesamento de datos máis rápido está a aumentar e procesamento streaming de datos en tempo real parece ser a resposta. Mentres Apache faísca aínda está a ser usado en unha morea de organizacións de procesamento de datos grande, Apache Flink foi subindo rapidamente como unha alternativa. In fact, moitos pensan que ten o potencial de substituír Apache faísca debido á súa capacidade para procesar fluxo de datos en tempo real. Of course, o xurado sobre Flink pode substituír faísca é aínda para fóra porque Flink aínda está a ser posto para probas xeneralizados. Pero o procesamento en tempo real e de baixa latencia de datos son dúas das súas características definidoras. At the same time, iso ten que ser considerado que o Apache faísca probablemente non vai saír de favor, porque as súas capacidades de procesamento en solar será aínda relevante.
Case a Transmisión de Procesamento de Datos
For all the merits of batch-based processing, there appears to be a strong case for real-time streaming data processing. Streaming data processing makes it possible to set up and load a data warehouse quickly. A streaming processor that has low data latency gives more insights on data quickly. So, you have more time to find out what is going on. In addition to quicker processing, there is also another significant benefit: you have more time to design an appropriate response to events. For example, in the case of anomaly detection, lower latency and quicker detection enables you to identify the best response which is key to prevent damage in cases such as fraudulent attacks on a secure website or industrial equipment damage. So, you can prevent substantial loss.
What is Apache Flink?
Apache Flink is a big data processing tool and it is known to process big data quickly with low data latency and high fault tolerance on distributed systems on a large scale. Its defining feature is its ability to process streaming data in real time.
Apache Flink started off as an academic open source project and back then, it was known as Stratosphere. Later, it became a part of the Apache Software Foundation incubator. To avoid conflict in name with another project, the name was changed to Flink. The name Flink is appropriate because it means agile. Even the logo chosen, a squirrel is appropriate because a squirrel represents the virtues of agility, nimbleness and speed.
Since it was added to the Apache Software Foundation, it had a rather quick rise as a big data processing tool and within 8 months, que comezara a captar a atención dun público máis amplo. crecente interese das persoas en Flink reflectiuse no número de participantes nunha serie de reunións en 2015. Un número de persoas participaron na reunión en Flink na Conferencia Strata en Londres en maio 2015 e no Cume Hadoop en San Jose en xuño, 2015. Máis que 60 persoas participaron da Bay Area Apache Flink meet-up aloxado na sede da MapR en San Jose en agosto, 2015.
A imaxe de abaixo dá a arquitectura Lambda de Flink.
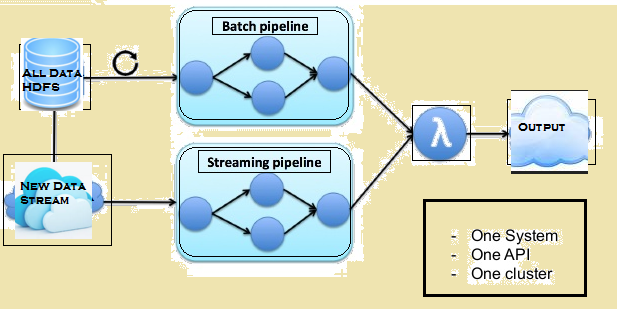
arquitectura Lambda de Flink
Comparación entre Faísca e Flink
Aínda que hai algunhas semellanzas entre Faísca e Flink, por exemplo, súas APIs e compoñentes, as semellanzas non importa moito cando se trata de procesamento de datos. Dada a continuación é unha comparación entre Flink e faísca.
informática
Faísca procesa os datos en modo de lote, mentres Flink procesa datos de transmisión en tempo real. Faísca procesa bloques de datos, coñecido como RDDS mentres Flink pode procesar liñas tras liñas de datos en tempo real. So, mentres que un mínimo de latencia de datos é sempre alí con faísca, non é así con Flink.
iteracións
Faísca soporta iteracións de datos en lotes, pero Flink pode nativamente iterado seus datos a través da súa arquitectura de streaming. A imaxe de abaixo mostra como iterativa procesamento ocorre.
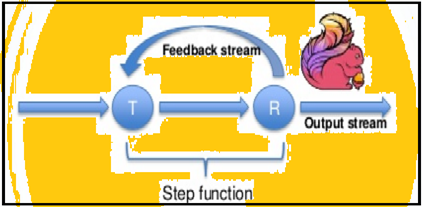
procesamento iterativo
Xestión de memoria
Flink pode adaptarse automaticamente para conxuntos de datos variados, pero faísca precisa para optimizar e axustar os seus postos de traballo manual para conxuntos de datos individuais. Tamén faísca fai o particionamento manual e caché. So, esperar algún atraso no procesamento.
Fluxo de datos
Flink é capaz de proporcionar resultados intermedios no seu proceso de datos sempre que sexa necesario. Mentres faísca segue un sistema de programación procedural, Flink segue un enfoque de fluxo de datos distribuídos. So, sempre que os resultados intermedios son necesarios, variables de transmisión son usados para distribuír os resultados pre-calculados a través de todos os nós do traballador.
Visualización de datos
Flink fornece unha interface web para presentar e executar todos os traballos. Ambos faísca e Flink están integrados co Apache Zeppelin e proporcionar inxestión de datos, análise de datos, descubrimento, colaboración e visualización. Apache Zeppelin tamén ofrece un motor multi-linguaxe que permite enviar e executar programas Flink.
Tempo de procesamento
Os parágrafos a continuación fornecen unha comparación entre o tempo gastado polo Flink e faísca en diferentes postos de traballo.
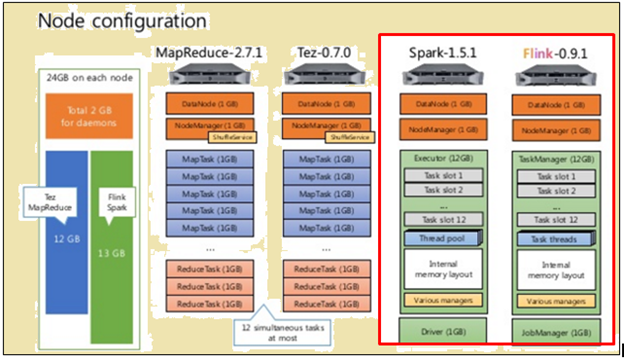
Para facer unha comparación xusta, both Flink and Spark were given the same resources in the form of machine specifications and node configurations.

Node configuration
As shown in the image above, the image highlighted in red indicates the machine specifications for a Flink processor while the one beside it shows that of a Spark processor.
As shown in the image above, the area highlighted in red indicates the node configuration for a Flink processor and a Spark processor.
Spark processor
Flink processed faster because of its pipelined execution. To process data, Spark took 2171 seconds while Flink took 1490 seconds.
When TeraSort with various data sizes were performed, following were the results:
- For 10 GB data, Flink took 157 seconds compared to Spark’s 387 seconds.
- For 160 GB data, Flink took 3127 seconds compared to Spark’s 4927 seconds.
Batch-based or Streaming Data — which process is better?
Both processes have advantages and are suited for different situations. Aínda que moitos están reivindicando que ferramentas baseadas en solar están saíndo do favor, iso non vai ocorrer axiña. Para entender as vantaxes relativas, vexa a seguinte comparación:
| transmisión | batching |
| Datos ou entradas chegan en forma de rexistros nunha secuencia específica. | Datos ou entradas son divididos en lotes de acordo co número de rexistros ou de tempo. |
| A saída é necesario logo que é posible, pero non máis cedo do que o tempo que é necesario para comprobar a secuencia. | As entradas son dadas en base a requisitos, pero un número de lotes son retidos. |
| A saída non precisan ser modificados tras ser escrita. | Un novo estado e os detalles de todas as liñas de saída son rexistradas. |
| Tamén pode facer o procesamento en lote de datos | É incapaz de facer o procesamento en solar de datos |
There are individual situations in which both Flink and Batch processing are useful. Take the use case of computing rolling monthly sales at daily intervals. In this activity, what is needed is to compute the daily sales total and then make a cumulative sum. In a use case like this, streaming processing of data may not be required. Batch processing of data can take care of the individual batches of sales figures based on dates and then add them. In this case, even if there is some data latency, which can always be made up later when that latent data is added to later batches.
There are similarly use cases which require streaming processing. Take the use case of calculating the rolling monthly time each visitor spends on a website. In case of a website, o número de visitas poden actualizados, de hora en hora, minuto-wise ou mesmo a diario. Pero o problema neste caso é que define a sesión. Pode ser difícil definir o inicio e finalización dunha sesión. Also, é difícil calcular ou identificar os períodos de inactividade. So, neste caso, non pode haber límites razoables para definición de sesións ou mesmo períodos de inactividade. En situacións como estas, procesamento de datos de transmisión nunha base en tempo real é necesaria.
Summary
Aínda faísca ten unha serie de vantaxes á hora de procesamento de datos en solar e aínda ten unha morea de casos de uso que atende a, parece que Flink está rapidamente gañando forza comercial. O feito de que Flink tamén pode facer o procesamento en solar parece ser unha cousa enorme no seu favor. Of course, esa necesidade de ser responsable de que as capacidades de procesamento en solar de Flink pode non estar na mesma liga como o de aceso. So, Faísca aínda ten tempo.