The demand for faster data processing has been increasing and real-time streaming data processing appears to be the answer. While Apache Spark is still being used in a lot of organizations for big data processing, Apache Flink on tulemas kiire alternatiivina. In fact, paljud arvavad, et see on võimalik asendada Apache Spark, sest tema võime töödelda vooandmeid reaalajas. Of course, Žürii kas Flink võib asendada Spark on veel läbi, sest Flink on veel panna levinud testid. Aga reaalajas töötlemise ja andmete väikese latentsusega on kaks tema põhilised omadused. At the same time, see tuleb arvestada, et Apache Spark ilmselt ei lähe kasuks, sest selle partii töötlemise võimalusi on endiselt asjakohased.
Case Streaming Andmetöötlus
Kõigi sisuliselt partii põhinev töötlemine, tundub olevat tugev juhul reaalajas streaming andmetöötlus. Streaming andmetöötlus võimaldab luua ja sisesta andmeladu kiiresti. Striiminguserver protsessor, mis on madala andmed latency annab täiendava ülevaate andmeid kiiresti. So, sul on rohkem aega, et teada saada, mis toimub. Lisaks kiiremini töötlemine, on olemas ka teine oluline eelis: sul on rohkem aega, et kujundada sobiv vastus sündmused. For example, puhul anomaaliate avastamiseks, madalam latentsus ja kiiremaks avastamiseks võimaldab teil kindlaks parim vastus, mis on võtmeks kahjustamise vältimiseks juhtudel, näiteks pettuse rünnakud turvalisele veebisaidile või tööstusseadmete kahju. So, saate vältida olulist vähenemist.
Mis on Apache Flink?
Apache Flink on suur andmete töötlemise vahend ja on teada, et töödelda suuri andmeid kiiresti madala andmeid latentsus ja kõrge rikketaluvuse hajussüsteeme suuremahuliste. Selle määratlemine omadus on võime töödelda streaming andmeid reaalajas.
Apache Flink alustas akadeemilise avatud lähtekoodiga projekt ja toona, oli ta tuntud kui Stratosphere'i. Later, sai osa Apache Software Foundation inkubaatoris. Selleks, et vältida konflikti nime teise projekti, nime muudeti Flink. Nimi Flink on asjakohane, sest see tähendab vilgas. Isegi logo valitud, orav on asjakohane, sest orav esindab vooruste agility, nobedus ja kiirus.
Kuna see lisati Apache Software Foundation, see oli pigem kiiret tõusu kui suur andmetöötlus vahend ja sees 8 months, ta alustas lüüa tähelepanu laiemale publikule. Inimeste kasvav huvi Flink kajastus osalejate arvu mitmes kohtumisi 2015. Mitu inimest osales koosolekul Flink juures Strata konverents Londoni kohtumisel mais 2015 ja Hadoop tippkohtumisel San Jose juunis, 2015. Rohkem kui 60 inimest osales Bay Area Apache Flink kokkusaamine võõrustajaks MAPR peakorter San Jose augustis, 2015.
Allolev pilt annab lambda arhitektuur Flink.
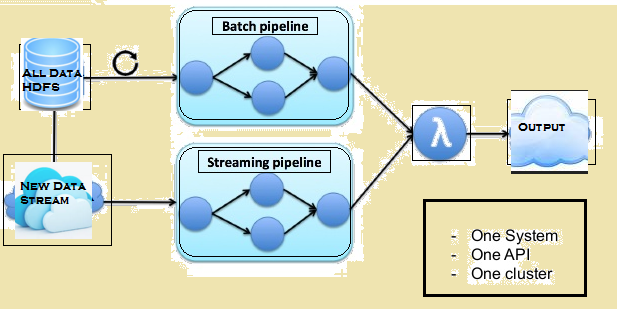
Lambda arhitektuur Flink
Võrdlus Spark ja Flink
Kuigi seal on mõned sarnasused Spark ja Flink, näiteks, nende rakendusliideste ja komponendid, sarnasusi ei loe palju, kui tegemist on andmete töötlemine. Allpool on võrdlus Flink ja Spark.
Andmetöötlus
Spark töötleb andmeid kogumitena samas Flink töötleb streaming andmeid reaalajas. Spark töötleb tükkideks andmeid, tuntakse RDDs samas Flink saab töödelda rida pärast rida andmeid reaalajas. So, samas minimaalse andmete latency on alati seal Spark, see ei ole nii koos Flink.
Kordused
Spark toetab andmete korduste partiidena kuid Flink saab algupäraselt kinnitada, et andmeid kasutades oma streaming arhitektuuri. Allolev pilt näitab, kuidas korduv töötlemine toimub.
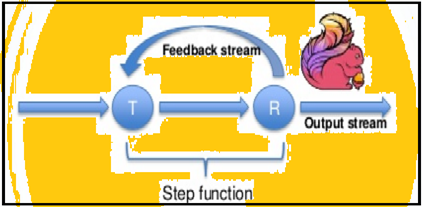
Iteratiivinen töötlemine
Mälu haldamine
Flink saab automaatselt kohandada erinevad andmekogud, kuid Spark tuleb optimeerida ja kohandada oma töökohta käsitsi individuaalsed andmekogud. Samuti Spark teeb käsitsi eraldamine ja vahemällu. So, oodata mõningane viivitus töötlemine.
andmevoo
Flink suudab pakkuda vahetulemused oma andmete töötlemiseks, kui on vaja. Kuigi Spark järgmiselt menetluslik programmeerimine süsteemi, Flink järgmiselt jagatud andmevoo lähenemist. So, alati vahetulemused on vaja, eetrisse muutujad on jagati eelnevalt arvutatud tulemused kaudu kõigile töötaja sõlmede.
andmete visualiseerimine
Flink annab veebiliidese esitada ja täita kõik tööd. Mõlemad Spark ja Flink on integreeritud Apache Zeppelin ja esitama andmeid ravimi allaneelamisel, andmete analüüs, avastus, koostöö ja visualiseerimine. Apache Zeppelin annab ka mitut keelt backend, mis võimaldab teil esitada ja täita Flink programmid.
Töötlusaeg
Järgnevates lõikudes annab võimaluse võrrelda kulus Flink ja Spark erinevaid töökohti.
Et õiglane võrdlus, nii Flink ja Spark anti samade vahendite näol masina spetsifikatsioonid ja sõlme koosseisudes.

sõlme konfiguratsiooni
Nagu pildil eespool, Pildi tähistatud punasega näitab masin spetsifikatsioonide Flink protsessor, samas kui üks selle kõrval näitab, et säde protsessor.
Nagu pildil eespool, ala tähistatud punasega näitab sõlme konfiguratsioon Flink protsessor ja Spark protsessor.
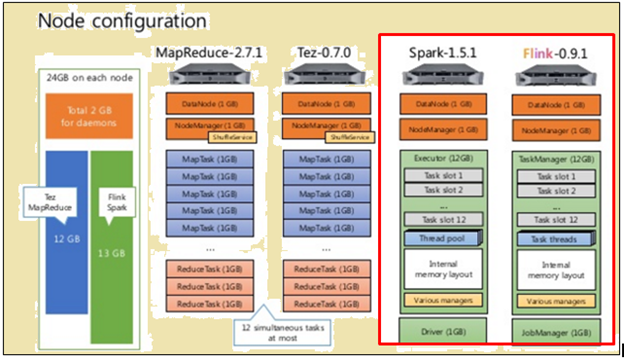
Spark protsessor
Flink töödeldud kiiremini, sest tema konveierrežiimis täitmise. Andmete töötlemiseks, Spark võttis 2171 sekundit samas Flink võttis 1490 sekundit.
Kui TeraSort erinevate andmete suurused viidi läbi, Järgnevalt olid tulemused:
- eest 10 GB kuupäev, Flink süütamise 157 sekundit võrreldes Sparki 387 sekundit.
- eest 160 GB kuupäev, Flink süütamise 3127 sekundit võrreldes Sparki 4927 sekundit.
Partii-põhine või vooandmeid - mis protsessi parem?
Mõlemad protsessid on plussid ja sobivad erinevatele olukordadele. Kuigi paljud väidavad, et partii põhinevad vahendid lähevad välja kasuks, see ei juhtu niipea. Selleks, et mõista oma suhtelisi eeliseid, vaata järgmist võrdlust:
| Streaming | Koguste |
| Andmed või sisendite saabuvad vormis arvestust kindlas järjekorras. | Andmed või sisendite jagunevad partiide arvu järgi arvestust või aeg. |
| Output nõutakse niipea kui on võimalik, kuid mitte varem kui aeg, mis on vajalik, et kontrollida järjestuse. | Sisendid on antud nõuete alusel, kuid teatud partiide arv säilitatakse. |
| Output ei vaja muuta pärast on kirjutatud. | Uus riik ja üksikasjad kõik read väljund on salvestatud. |
| Teha ka partii andmete töötlemise | Ei suuda teha partii andmete töötlemise |
Seal on individuaalsed olukordi, kus nii Flink ja Pakktöötlus on kasulikud. Võtke kasutamise puhul arvutustehnika jooksva kuu müügitulemused päevase intervalliga. Selle tegevuse, Vaja on arvutada välja iga päev müüki kokku ja siis teha kumulatiivne summa. Ühes kasutamise puhul niimoodi, streaming andmete töötlemine ei tohi nõuda. Partii töötlemine võib hoolitseda üksikuid müüginumbrid põhineb kuupäevade ja seejärel lisage need. Sel juhul, isegi kui on mõned andmed latency, mis võib alati koosneb hiljem, kui et latentse andmed lisatakse hiljem partiide.
Seal on samamoodi kasutada juhtudel, mis nõuavad streaming töötlemine. Võtke kasutamise puhul arvutatakse jooksva kuus korda iga külastaja veebisaidil veedab. Kui veebileht, külastuste arv võib ajakohastada, iga tund, minut tark või isegi iga päev. Aga probleem on sel juhul määratletakse seanss. See võib olla raske määratleda algus ja lõpp seanss. Also, see on raske arvutada või tuvastada tegevusetuse perioode. So, sel juhul, ei saa olla mõistlikku piire määratlemiseks istungid või isegi tegevusetuse perioode. Olukordades, nagu need, streaming andmete töötlemise reaalajas on vajalik.
Summary
Kuigi Spark on palju eeliseid, kui tegu on partii töötlemise ja see on veel palju kasutada juhul näeb, tundub, et Flink on kiiresti muutumas kaubandusliku veojõu. Asjaolu, et Flink teha ka partii töötlemise tundub olevat suur asi enda kasuks. Of course, see tuleb arvestada, et partii töötlemise võimalusi Flink ei pruugi olla samas liigas nagu Spark. So, Spark on veel mõnda aega.