Η ζήτηση για ταχύτερη επεξεργασία των δεδομένων έχει αυξηθεί και σε πραγματικό χρόνο επεξεργασίας ροής δεδομένων φαίνεται να είναι η απάντηση. Ενώ Apache Spark εξακολουθεί να χρησιμοποιείται σε πολλές οργανώσεις για μεγάλες επεξεργασία δεδομένων, Apache Flink έχει να ανεβαίνει γρήγορα ως εναλλακτική λύση. In fact, πολλοί πιστεύουν ότι έχει τη δυνατότητα να αντικαταστήσει Apache Spark λόγω της ικανότητάς της να επεξεργάζεται δεδομένα συνεχούς ροής σε πραγματικό χρόνο. Of course, Η κριτική επιτροπή για το αν Flink μπορεί να αντικαταστήσει το Spark είναι ακόμα έξω, διότι Flink δεν έχει ακόμα τεθεί σε εκτεταμένες δοκιμές. Αλλά επεξεργασία σε πραγματικό χρόνο και χαμηλό latency δεδομένα είναι δύο από τα χαρακτηριστικά καθοριστικό της. At the same time, αυτό πρέπει να ληφθεί υπόψη ότι Apache Spark μάλλον δεν θα πάει σε δυσμένεια λόγω των δυνατοτήτων της επεξεργασίας της παρτίδας θα εξακολουθούν να ισχύουν.
Θήκη για επεξεργασία δεδομένων ροής
Για όλα τα πλεονεκτήματα της επεξεργασίας της παρτίδας με βάση, φαίνεται να είναι ένα ισχυρό επιχείρημα για επεξεργασία σε πραγματικό χρόνο τα δεδομένα συνεχούς ροής υπάρχει. Συνεχούς ροής επεξεργασίας δεδομένων καθιστά δυνατή τη δημιουργία και να φορτώσετε μια αποθήκη δεδομένων γρήγορα. Ένας επεξεργαστής streaming που έχει χαμηλό latency δεδομένων δίνει περισσότερες πληροφορίες σχετικά με τα δεδομένα γρήγορα. So, έχετε περισσότερο χρόνο για να μάθετε τι συμβαίνει. Εκτός από την ταχύτερη επεξεργασία, υπάρχει και ένα άλλο σημαντικό όφελος: έχετε περισσότερο χρόνο για να σχεδιάσουν μια κατάλληλη απάντηση στα γεγονότα. For example, στην περίπτωση της ανωμαλίας ανίχνευσης, χαμηλότερο latency και ταχύτερη ανίχνευση σας δίνει τη δυνατότητα να προσδιορίσει την καλύτερη απάντηση που είναι το κλειδί για την πρόληψη των ζημιών σε περιπτώσεις όπως η δόλια επιθέσεις σε έναν ασφαλή δικτυακό τόπο ή βιομηχανική βλάβη του εξοπλισμού. So, μπορείτε να αποτρέψετε την απώλεια σημαντικών.
Τι είναι το Apache Flink?
Apache Flink είναι ένα μεγάλο εργαλείο για την επεξεργασία των δεδομένων και είναι γνωστό για την επεξεργασία μεγάλων δεδομένων με χαμηλό latency δεδομένων και υψηλή ανοχή σε σφάλματα σε κατανεμημένα συστήματα σε μεγάλη κλίμακα. καθοριστικό χαρακτηριστικό του είναι η ικανότητά του να επεξεργάζεται τα δεδομένα συνεχούς ροής σε πραγματικό χρόνο.
Apache Flink ξεκίνησε ως ένα ακαδημαϊκό έργο ανοικτού πηγαίου κώδικα και τότε, ήταν γνωστό ως Stratosphere. Later, έγινε ένα μέρος της θερμοκοιτίδας Apache Software Foundation. Για να αποφευχθεί η σύγκρουση με το όνομα με άλλο έργο, το όνομα άλλαξε σε Flink. Το όνομα Flink είναι κατάλληλη, διότι σημαίνει ευκίνητη. Ακόμη και το λογότυπο έχει επιλεγεί, ένας σκίουρος είναι κατάλληλο επειδή ένας σκίουρος αντιπροσωπεύει τις αρετές της ευελιξίας, σβελτάδα και την ταχύτητα.
Δεδομένου ότι προστέθηκε στο Ίδρυμα Λογισμικού Apache, είχε μια μάλλον γρήγορη άνοδο ως ένα μεγάλο εργαλείο επεξεργασίας δεδομένων και εντός 8 months, είχε αρχίσει να συλλάβει την προσοχή του σε ένα ευρύτερο κοινό. αυξανόμενο ενδιαφέρον των ανθρώπων σε Flink αντανακλάται στον αριθμό των συμμετεχόντων σε μια σειρά από συναντήσεις σε 2015. Ένας αριθμός των ατόμων που συμμετείχαν στη σύσκεψη της Flink κατά τη Διάσκεψη Στράτα στο Λονδίνο τον Μάιο 2015 και η Σύνοδος Κορυφής Hadoop στο Σαν Χοσέ, τον Ιούνιο, 2015. Περισσότερο από 60 άνθρωποι παρακολούθησαν το Bay Area Apache Flink πληρούν-up που φιλοξενείται στην έδρα MapR στο Σαν Χοσέ τον Αύγουστο, 2015.
Η παρακάτω εικόνα δίνει την αρχιτεκτονική Lambda της Flink.
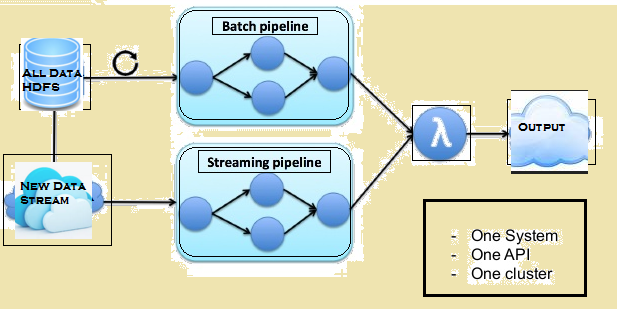
Lambda αρχιτεκτονική Flink
Σύγκριση μεταξύ Spark και Flink
Αν και υπάρχουν μερικές ομοιότητες μεταξύ Spark και Flink, για παράδειγμα, APIs και τα συστατικά τους, οι ομοιότητες δεν πειράζει πολύ όταν πρόκειται για την επεξεργασία δεδομένων. Δεδομένου παρακάτω είναι μια σύγκριση μεταξύ Flink και Spark.
Επεξεργασία δεδομένων
Spark επεξεργάζεται δεδομένα σε batch mode, ενώ Flink επεξεργάζεται δεδομένα συνεχούς ροής σε πραγματικό χρόνο. Spark επεξεργάζεται κομμάτια των δεδομένων, γνωστή ως RDDs ενώ Flink μπορεί να επεξεργαστεί σειρές από γραμμές δεδομένων σε πραγματικό χρόνο. So, ενώ η ελάχιστη καθυστέρηση τα δεδομένα είναι πάντα εκεί με Spark, δεν είναι έτσι με Flink.
επαναλήψεις
Spark υποστηρίζει επαναλήψεις δεδομένων σε παρτίδες, αλλά Flink μπορεί εγγενώς επαναλάβει τα στοιχεία της χρησιμοποιώντας συνεχούς ροής αρχιτεκτονική του. Η παρακάτω εικόνα δείχνει πώς επαναληπτική επεξεργασία πραγματοποιείται.
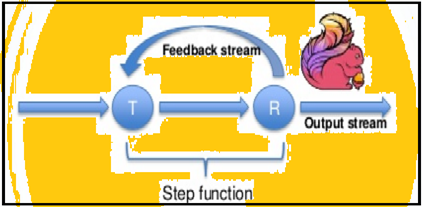
επαναληπτική επεξεργασία
Διαχείριση μνήμης
Flink μπορεί να προσαρμοστεί αυτόματα σε ποικίλα σύνολα δεδομένων, αλλά Spark χρειάζεται να βελτιστοποιήσουν και να προσαρμόσει τις θέσεις εργασίας τους με το χέρι σε επιμέρους σύνολα δεδομένων. Επίσης Spark κάνει διαμέριση με το χέρι και προσωρινή αποθήκευση. So, περιμένετε κάποια καθυστέρηση στην επεξεργασία.
Ροή δεδομένων
Flink είναι σε θέση να παρέχει ενδιάμεσα αποτελέσματα σχετικά με την επεξεργασία των δεδομένων του, όποτε ζητηθεί. Ενώ Spark ακολουθεί ένα διαδικαστικό σύστημα προγραμματισμού, Flink ακολουθεί μια προσέγγιση ροής δεδομένων που διανέμονται. So, όποτε ενδιάμεσα αποτελέσματα είναι υποχρεωτικά, Οι μεταβλητές μετάδοσης χρησιμοποιούνται για τη διανομή των προ-υπολογισμένα αποτελέσματα μέσα σε όλους τους κόμβους των εργαζομένων.
Οπτικοποίηση δεδομένων
Flink παρέχει ένα web interface για να υποβάλει και να εκτελέσει όλες τις εργασίες. Τόσο Spark και Flink ενσωματώνονται με Apache Zeppelin και να παρέχει την κατάποση δεδομένων, analytics δεδομένων, ανακάλυψη, συνεργασία και οπτικοποίηση. Apache Zeppelin παρέχει επίσης μια πολύγλωσση backend που σας επιτρέπει να υποβάλετε και να εκτελέσει προγράμματα Flink.
Χρόνος επεξεργασίας
Οι παρακάτω παράγραφοι παρέχουν μια σύγκριση μεταξύ του χρόνου που λαμβάνονται από Flink και Spark σε διαφορετικές θέσεις εργασίας.
Για να κάνετε μια δίκαιη σύγκριση, τόσο Flink και Spark δόθηκαν τους ίδιους πόρους, με τη μορφή των προδιαγραφών του μηχανήματος και διαμορφώσεις κόμβων.

διαμόρφωση κόμβου
Όπως φαίνεται στην παραπάνω εικόνα, η εικόνα επισημαίνονται με κόκκινο χρώμα υποδεικνύει τις προδιαγραφές του μηχανήματος για έναν επεξεργαστή Flink ενώ το ένα δίπλα δείχνει ότι από έναν επεξεργαστή Spark.
Όπως φαίνεται στην παραπάνω εικόνα, η περιοχή επισημαίνονται με κόκκινο χρώμα υποδεικνύει τη διαμόρφωση κόμβου για έναν επεξεργαστή Flink και έναν επεξεργαστή Spark.
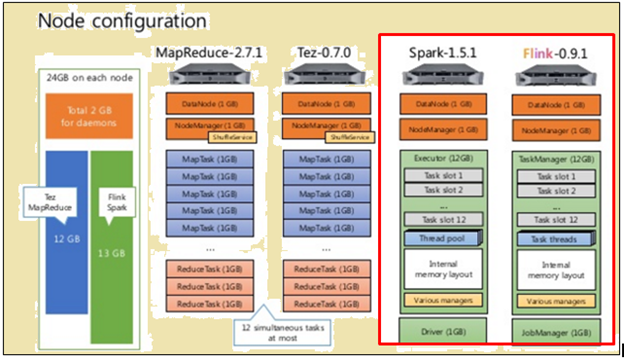
επεξεργαστή Spark
Flink επεξεργασία πιο γρήγορα λόγω της διοχέτευσης της εκτέλεσής του. Για την επεξεργασία των δεδομένων, Spark πήρε 2171 δευτερόλεπτα ενώ Flink πήρε 1490 δευτερόλεπτα.
Όταν διεξήχθησαν TeraSort με διάφορα μεγέθη δεδομένα, Ήσαν τα αποτελέσματα:
- Για 10 ημερομηνία GB, Flink ψήσιμο 157 δευτερόλεπτα σε σύγκριση με του Spark 387 δευτερόλεπτα.
- Για 160 ημερομηνία GB, Flink ψήσιμο 3127 δευτερόλεπτα σε σύγκριση με του Spark 4927 δευτερόλεπτα.
Batch-based ή ροής δεδομένων - η οποία μέθοδος είναι καλύτερη?
Και οι δύο διαδικασίες έχουν πλεονεκτήματα και είναι κατάλληλα για διαφορετικές καταστάσεις. Αν και πολλοί ισχυρίζονται ότι παρτίδα-based εργαλεία θα δυσμένεια, δεν πρόκειται να συμβεί σύντομα. Για να καταλάβουμε τα συγκριτικά πλεονεκτήματα τους, δείτε το παρακάτω σύγκριση:
| Βίντεο | παρτίδων |
| Δεδομένα ή είσοδοι φθάνουν με τη μορφή αρχείων σε μια συγκεκριμένη αλληλουχία. | Τα δεδομένα ή τις εισροές χωρίζονται σε παρτίδες με βάση τον αριθμό των εγγραφών ή το χρόνο. |
| Έξοδος απαιτείται το συντομότερο δυνατό, αλλά όχι νωρίτερα από το χρόνο που απαιτείται για την επαλήθευση της αλληλουχίας. | Οι είσοδοι δίνονται με βάση τις απαιτήσεις αλλά ένας ορισμένος αριθμός παρτίδων διατηρούνται. |
| Εξόδου δεν χρειάζεται να τροποποιηθούν μετά γράφεται. | Μια νέα κατάσταση και τα στοιχεία όλων των σειρών της παραγωγής καταγράφονται. |
| Μπορεί επίσης να κάνουμε μαζική επεξεργασία των δεδομένων | Δεν είναι σε θέση να κάνει την επεξεργασία παρτίδα των δεδομένων |
Υπάρχουν μεμονωμένες περιπτώσεις στις οποίες τόσο Flink και επεξεργασία παρτίδας είναι χρήσιμα. Πάρτε την περίπτωση χρήσης των υπολογιστών μηνιαία κυλιόμενη πωλήσεις σε ημερήσια διαστήματα. Σε αυτή τη δραστηριότητα, αυτό που χρειάζεται είναι να υπολογιστεί το συνολικό ημερήσιες πωλήσεις και στη συνέχεια να κάνουν ένα άθροισμα. Σε περίπτωση χρήσης όπως αυτό, μπορεί να μην απαιτείται επεξεργασία ροή των δεδομένων. Μαζική επεξεργασία των δεδομένων μπορεί να αναλάβει τη φροντίδα των επιμέρους παρτίδων στοιχεία για τις πωλήσεις βάσει της ημερομηνίας και, στη συνέχεια, προσθέστε τα. Σε αυτήν την περίπτωση, ακόμη και αν υπάρχει κάποια λανθάνουσα δεδομένα, το οποίο μπορεί πάντα να γίνει αργότερα, όταν η λανθάνουσα δεδομένα προστίθενται αργότερα παρτίδες.
Υπάρχουν χρησιμοποιούν ομοίως τις περιπτώσεις που απαιτούν την επεξεργασία ροής. Πάρτε την περίπτωση χρήσης υπολογισμού του τροχαίου μηνιαία ώρα κάθε επισκέπτης δαπανά σε μια ιστοσελίδα. Σε περίπτωση μιας ιστοσελίδας, ο αριθμός των επισκέψεων μπορεί να ενημερώνεται, ωριαίος, λεπτών-σοφός ή ακόμα και καθημερινά. Αλλά το πρόβλημα σε αυτή την περίπτωση είναι ο καθορισμός της συνόδου. Μπορεί να είναι δύσκολο να προσδιοριστεί η έναρξη και λήξη της συνόδου. Also, είναι δύσκολο να υπολογιστεί ή να προσδιορίσει τις περιόδους αδράνειας. So, σε αυτήν την περίπτωση, δεν μπορεί να υπάρξει λογική όρια για τον καθορισμό συνεδρίες ή ακόμα και περιόδους αδράνειας. Σε καταστάσεις σαν αυτές, ροής επεξεργασίας δεδομένων σε πραγματικό χρόνο απαιτείται.
Summary
Αν Spark έχει πολλά πλεονεκτήματα, όταν πρόκειται για την επεξεργασία των δεδομένων παρτίδα και εξακολουθεί να έχει πολλές περιπτώσεις χρήσης που εξυπηρετεί, φαίνεται ότι Flink κερδίζει γρήγορα την εμπορική έλξη. Το γεγονός ότι Flink μπορεί επίσης να κάνει την επεξεργασία παρτίδα φαίνεται να είναι ένα τεράστιο πράγμα υπέρ του. Of course, Αυτές πρέπει να λογίζονται ότι οι δυνατότητες επεξεργασίας της παρτίδας του Flink μπορεί να μην είναι στην ίδια κατηγορία με εκείνη του Spark. So, Spark εξακολουθεί να έχει κάποιο χρόνο.