The demand for faster data processing has been increasing and real-time streaming data processing appears to be the answer. While Apache Spark is still being used in a lot of organizations for big data processing, Apache Flink har kommer op hurtigt som et alternativ. In fact, mange mener, at det har potentiale til at erstatte Apache Spark grund af dets evne til at behandle streaming data realtid. Of course, juryen om Flink kan erstatte Spark er stadig ude, fordi Flink er endnu ikke sat udbredte tests. Men real-time behandling og lav data latency er to af dens kendetegn. At the same time, dette skal overvejes at Apache Spark formentlig ikke vil gå i unåde, fordi dens batch databehandling vil være stadig relevant.
Taske til streaming Data Processing
For alle fordelene ved batch-baseret behandling, der synes at være en stærk sag for real-time streaming databehandling. Streaming databehandling gør det muligt at oprette og indlæse en datawarehouse hurtigt. En streaming processor, der har lav data latency giver mere indsigt på data hurtigt. So, du har mere tid til at finde ud af, hvad der foregår. Ud over hurtigere behandling, Der er også en anden væsentlig fordel: du har mere tid til at designe en passende reaktion på begivenheder. For example, i tilfælde af anomalisøgning, lavere latency og hurtigere afsløring gør det muligt at identificere det bedste svar, som er nøglen til at forebygge skader i tilfælde som svigagtige angreb på et sikkert websted eller industriel skade udstyr. So, du kan forhindre betydelige tab.
Hvad er Apache Flink?
Apache Flink er en stor databehandling værktøj og det er kendt at behandle store data hurtigt med lav data latenstid og høj fejltolerance på distribuerede systemer i stor skala. Det afgørende træk er dens evne til at behandle streaming data i realtid.
Apache Flink startede som en akademisk open source projekt, og dengang, det var kendt som Stratosphere. Later, det blev en del af Apache Software Foundation incubator. For at undgå konflikter i navn med et andet projekt, navnet blev ændret til Flink. Navnet Flink er hensigtsmæssig, fordi det betyder adræt. Selv logoet valgt, et egern er passende, fordi et egern repræsenterer dyder agility, nimbleness og hastighed.
Da det blev sat til Apache Software Foundation, det havde en temmelig hurtig stigning som en stor databehandling værktøj og inden 8 months, Det var begyndt at fange opmærksomheden fra et bredere publikum. Folkets stigende interesse i Flink blev afspejlet i antallet af deltagere i en række møder i 2015. Et antal mennesker deltog i mødet om Flink på Strata konference i London i maj 2015 og topmødet Hadoop i San Jose i juni, 2015. Mere end 60 mennesker deltog i Bay Area Apache Flink mødes-up vært på MapR hovedkvarter i San Jose i august, 2015.
Billedet nedenfor giver Lambda arkitektur Flink.
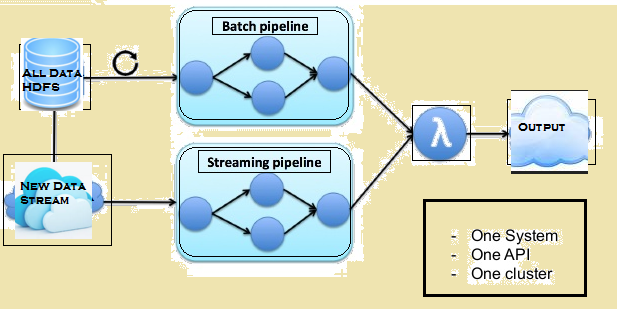
Lambda arkitektur Flink
Sammenligning mellem Spark og Flink
Selvom der er et par ligheder mellem Spark og Flink, for eksempel, deres API'er og komponenter, lighederne ikke sagen meget, når det kommer til databehandling. Nedenfor er en sammenligning mellem Flink og Spark.
Databehandling
Spark behandler data i batch-mode, mens Flink behandler streaming data i realtid. Spark behandler bidder af data, kendt som RDD mens Flink kan behandle rækker efter rækker af data i realtid. So, mens et minimum data latenstid er altid med Spark, det er ikke så med Flink.
gentagelser
Spark understøtter data iterationer i partier, men Flink kan indbygget gentage sine data ved at bruge sin streaming arkitektur. Billedet nedenfor viser, hvordan iterativ forarbejdningen finder sted.
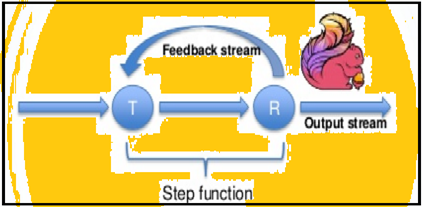
iterativ behandling
Memory Management
Flink kan automatisk tilpasse sig forskellige datasæt, men Spark skal optimere og justere sine job manuelt til individuelle datasæt. Også Spark gør manuel partitionering og caching. So, forventer en vis forsinkelse i behandlingen.
data Flow
Flink er i stand til at levere foreløbige resultater på sin databehandling når det er påkrævet. Mens Spark følger en proceduremæssig programmeringssystem, Flink følger en fordelt datastrøm tilgang. So, når mellemliggende resultater er påkrævet, broadcast variabler anvendes til at distribuere de forudberegnede resultater igennem til alle arbejdstager noder.
datavisualisering
Flink giver et webinterface til at indsende og udføre alle job. Både Spark og Flink er integreret med Apache Zeppelin og levere data indtagelse, data analytics, opdagelse, samarbejde og visualisering. Apache Zeppelin giver også en multi-sprog backend der giver dig mulighed for at indsende og udføre Flink programmer.
Behandlingstid
Afsnittene nedenfor giver en sammenligning mellem den tid, Flink og Spark i forskellige jobs.
For at gøre en rimelig sammenligning, både Flink og Spark fik de samme ressourcer i form af maskinens specifikationer og node konfigurationer.

Node konfiguration
Som det fremgår af billedet ovenfor, the image highlighted in red indicates the machine specifications for a Flink processor while the one beside it shows that of a Spark processor.
Som det fremgår af billedet ovenfor, the area highlighted in red indicates the node configuration for a Flink processor and a Spark processor.
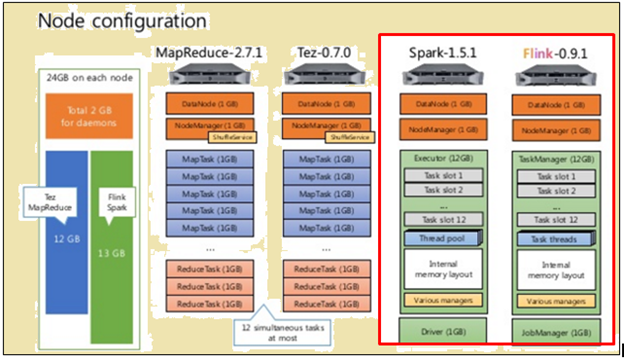
Spark processor
Flink processed faster because of its pipelined execution. To process data, Spark took 2171 seconds while Flink took 1490 seconds.
When TeraSort with various data sizes were performed, following were the results:
- For 10 GB data, Flink took 157 seconds compared to Spark’s 387 seconds.
- For 160 GB data, Flink took 3127 seconds compared to Spark’s 4927 seconds.
Batch-based or Streaming Data — which process is better?
Both processes have advantages and are suited for different situations. Though many are claiming that batch-based tools are going out of favor, it is not going to happen anytime soon. To understand their relative advantages, se følgende sammenligning:
| Streaming | batching |
| Data eller input ankommer i form af poster i en specifik sekvens. | Data eller input er opdelt i partier baseret på antallet af optegnelser eller tid. |
| Output er påkrævet så hurtigt som muligt, men ikke før end den tid, der er nødvendig for at kontrollere sekvensen. | Indgange er givet på grundlag af krav, men et vist antal partier bevares. |
| Output behøver ikke at blive ændret efter det er skrevet. | En ny stat og oplysninger om alle rækkerne af output registreres. |
| Kan også gøre batch behandling af data | Er ikke i stand til at gøre batch behandling af data |
Der er individuelle situationer, hvor både Flink og Batchbehandling er nyttige. Tag brugen tilfælde af computing rullende månedlige salg på daglige intervaller. I denne aktivitet, what is needed is to compute the daily sales total and then make a cumulative sum. In a use case like this, streaming processing of data may not be required. Batch processing of data can take care of the individual batches of sales figures based on dates and then add them. In this case, even if there is some data latency, which can always be made up later when that latent data is added to later batches.
There are similarly use cases which require streaming processing. Take the use case of calculating the rolling monthly time each visitor spends on a website. In case of a website, the number of visits may be updated, hourly, minute-wise or even daily. But the problem in this case is defining the session. It may be difficult to define the starting and ending of a session. Also, det er vanskeligt at beregne eller identificere perioder med inaktivitet. So, i dette tilfælde, Der kan være nogen rimelig grænser for at definere sessioner eller endda perioder med inaktivitet. I situationer som disse, streaming databehandling på tidstro basis er nødvendig.
Summary
Selvom Spark har en masse fordele, når det kommer til behandling batch data og det stadig har en masse use cases Det henvender sig til, fremgår det, at Flink er hurtigt vinder kommerciel trækkraft. Det faktum, at Flink også kan gøre batch-behandling synes at være en stor ting i sin favør. Of course, dette behov skal behandles, at batch databehandling af Flink ikke kan være i samme liga som for Spark. So, Spark har stadig lidt tid.