Tổng quan:
Hadoop là một nền tảng đó là gần như đồng nghĩa với Big Data. Nó là cơ bản một khuôn khổ nguồn mở, cho phép lưu trữ và xử lý của nhóm các bộ dữ liệu trên quy mô lớn. chủ yếu, kiến trúc Hadoop được biết đến bao gồm bốn mô-đun lớn, đó là HDFS (Hadoop Distributed Fvới System), Hadoop Common, sỢI và MapReduce. Mỗi một trong những mô-đun được thiết lập để thực hiện các nhiệm vụ cụ thể nào đó, mà đến với nhau như một toàn bộ để đáp ứng yêu cầu xử lý dữ liệu. Một trong những khía cạnh quan trọng để thành công sản xuất là kiến trúc Hadoop. Kiến trúc này cung cấp một số tính năng quan trọng mà có trách nhiệm phổ biến của nó qua các khuôn khổ khác như của bây giờ. However, cũng có một vài điều khác để xem xét cho thực hiện thành công Hadoop. Điều này có nghĩa là, nó không chỉ là về việc có một hệ thống lưu trữ thích hợp của hồ sơ hoặc 24×7 chạy các ứng dụng, mà còn làm thế nào nó tích hợp với kiến trúc tổng thể và các công cụ của một doanh nghiệp.
Bài viết này chủ yếu sẽ thảo luận về kiến trúc Hadoop chi tiết cùng với những lợi thế từng module Mời. Chúng tôi cũng sẽ bao gồm các vấn đề thành công sản xuất.
Sau đây là một Hadoop sơ đồ kiến trúc đơn giản cho 2.0 các phiên bản
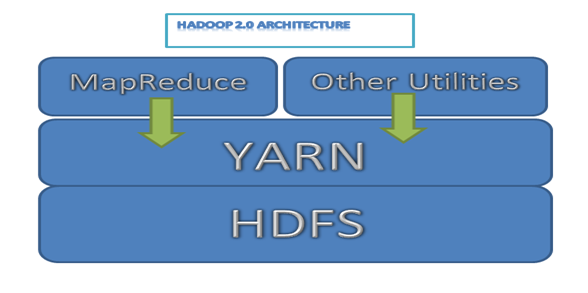
Hadoop 2.0 architecture
Image 1: Hadoop 2.0 architecture
HDFS Kiến trúc
Như đã đề cập, Hadoop HDFS chắc chắn là một trong những thành phần quan trọng của toàn bộ khung. Đó là mô-đun được giao nhiệm vụ cung cấp đáng tin cậy, Hệ thống lưu trữ vĩnh viễn và được phân phối trên một số nút có mặt trong một cụm Hadoop.
Now, một cụm thường bao gồm một số nút được liên kết với nhau để tạo thành một hệ thống tập tin hoàn chỉnh. Tất cả các dữ liệu cần phải được lưu trữ là lúc đầu bị phá vỡ thành nhiều mẩu nhỏ được gọi là khối. Các khối này sau đó được phân phối và lưu trữ trên một số nút của cluster. Đây là cách thức mà các tập tin hệ thống Hadoop được xây dựng và nó có những lợi thế nhất định là tốt.
Chúng ta hãy có một cái nhìn tại các tính năng khác của HDFS.
Scalable
Do sự hiện diện của kiến trúc hệ thống tập tin phân phối, Bản đồ Hadoop và làm giảm chức năng hoạt động như một làn gió. Các chức năng này có thể dễ dàng thực hiện trên các tập con nhỏ của dữ liệu gốc, qua đó cung cấp khả năng mở rộng rất lớn. Đây cũng là một lợi thế cho các doanh nghiệp, như họ chỉ có thể thêm các máy chủ tuyến tính, khi dữ liệu của họ có vẻ phát triển.
Linh hoạt
Một khía cạnh khác rất thuận lợi của HDFS là bản chất linh hoạt cao của nó về lưu trữ dữ liệu. Là mã nguồn mở, Hadoop có thể dễ dàng chạy trên phần cứng hàng hóa, trong đó tiết kiệm chi phí rất nhiều. Also, hệ thống tập tin Hadoop có thể lưu trữ bất kỳ loại dữ liệu, cho dù nó được cấu trúc, không có cấu trúc, định dạng hoặc thậm chí mã hóa.
Hadoop thậm chí làm cho nó có thể cho dữ liệu phi cấu trúc có giá trị cho một tổ chức trong suốt một quá trình ra quyết định, cái gì đó đã được thực tế chưa từng có trước.
đáng tin cậy
Các hệ thống tập tin Hadoop là lỗi khoan dung, có nghĩa là các dữ liệu được lưu trữ trong HDFS được nhân rộng đến mức tối thiểu hai địa điểm khác. Thus, trong trường hợp có một sự sụp đổ của một hệ thống hoặc hai, luôn luôn có một hệ thống thứ ba sẽ có một bản sao của tất cả các dữ liệu của bạn. sau đó hệ thống có thể phân bổ khối lượng công việc cho vị trí này và tất cả mọi thứ có thể làm việc bình thường.
Tập I / O
Hiệu quả của bất kỳ hệ thống tập tin phụ thuộc vào cách nó thực hiện các I / O hoạt động. trong HDFS, dữ liệu được thêm vào bằng cách tạo ra một tập tin mới và ghi dữ liệu có. Sau đây, các tập tin được đóng lại và các dữ liệu ghi không thể xóa hoặc sửa đổi nữa. Nhưng dữ liệu mới có thể được nối bằng cách tái mở các tập tin. Vì vậy, các nền tảng cơ bản của HDFS là "Single viết và nhiều đọc’ mô hình.
khối Vị trí
trong HDFS, một tập tin là một sự kết hợp của nhiều khối. Để thêm một khối mới, NameNode gán một id khối duy nhất và thêm nó vào tập tin. Sau này các khối mới cũng được nhân rộng ở nhiều DataNodes.
HDFS Chính sách vị trí khối được cấu hình, để người dùng có thể thử nghiệm với các lựa chọn thay thế khác nhau để có được những giải pháp tối ưu. Theo mặc định, HDFS Chính sách vị trí khối cố gắng giảm thiểu các chi phí ghi và tối đa hóa hiệu suất đọc, sẵn có và độ tin cậy. Để thực hiện điều này, khi một khối mới được thêm vào một tập tin, các bản sao đầu tiên được đặt trên cùng một nút nơi các nhà văn có mặt. Sau đây, bản sao thứ 2 và thứ 3 là vị trí trên hai nút khác nhau trong một rack riêng. Bây giờ phần còn lại của các bản sao được đặt ngẫu nhiên. Nhưng hạn chế là, một nút không thể giữ nhiều bản sao và một rack không thể giữ hơn hai bản sao.
Sau hình ảnh cho thấy một trường hợp điển hình của các vị trí bản sao trong một môi trường giá (như đã mô tả ở phần trên)
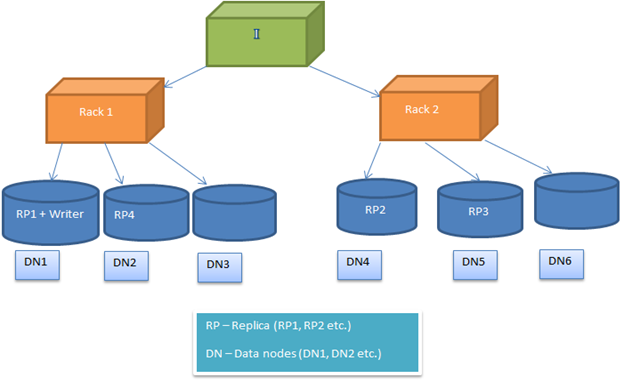
vị trí bản sao
Image2: Hiển thị vị trí bản sao trong một môi trường hai giá
Hadoop Common / Hadoop lõi
Hadoop phổ biến bao gồm các thiết lập chung của các tiện ích để hỗ trợ kiến trúc Hadoop. Đây là những cơ bản API cơ sở để giúp các module khác giao tiếp với nhau. Nó cũng được coi là một phần quan trọng của kiến trúc Hadoop như HDFS, MapReduce và sợi. Nó cung cấp một trừu tượng trên đầu trang của các tính năng cốt lõi nằm bên dưới như hệ thống tập tin, Hệ điều hành, vv.
Cơ sở hạ tầng sợi
sỢI, hoặc là 'vàvà Mộtnother Resource Negotiator ', là mô-đun trong Hadoop mà là chịu trách nhiệm về việc quản lý các tài nguyên tính toán. As such, nó cấp CPU hoặc bộ nhớ, dựa trên các nhiệm vụ mà là ở bàn tay. Now, Sợi chủ yếu được tạo thành từ hai phần chính - Quản lý tài nguyên và quản lý Node.
- Quản lý tài nguyên
Resource Manager, mà cũng được gọi là bậc thầy, có một sự hiện diện duy nhất trong một cluster và chạy một số dịch vụ. Nó theo dõi nơi các công nhân đang nằm và cũng quản lý các tài nguyên Scheduler, mà gán tài nguyên.
- Node Manager
Quản lý Node sẽ xảy ra là nhân viên của cơ sở hạ tầng và có thể có nhiều người trong số họ trong một cụm Hadoop. Mỗi của các nhà quản lý Node cung cấp nguồn lực cho các cụm. Sức chứa của các nguồn tài nguyên được đo ở dạng trí nhớ và vcores (phần lõi CPU). Resource Manager sử dụng tài nguyên từ trình quản lý Node, khi cần thiết để chạy một nhiệm vụ.
Hadoop sợi có một số khía cạnh rất thuận lợi mà làm cho nó một phần quan trọng của kiến trúc. Những đã được phác thảo chi tiết.
Thuê nhiều kiểu
Một trong những lợi thế lớn nhất Hadoop sợi là nó hỗ trợ quản lý tài nguyên động. Mặc dù chia sẻ các nguồn lực của cùng một cụm, nó có khả năng chạy nhiều động cơ và khối lượng công việc. And, giống như HDFS, Sợi cũng là khả năng mở rộng, cung cấp khả năng lập kế hoạch lớn, không có vấn đề gì các khối lượng công việc có thể.
Mạnh mẽ
Hadoop sợi cung cấp mạnh mẽ, mà cho phép bạn mở dữ liệu của bạn với một loạt các công cụ và công nghệ có thể giúp bạn có được tốt nhất của xử lý dữ liệu. hệ sinh thái của nó là thiết lập tốt để đáp ứng nhu cầu của các nhà phát triển khác nhau và cũng có tổ chức quy mô nhỏ và lớn.
thực tế, Hadoop hiện nay đi kèm với một số dự án nổi tiếng như Hive, MapReduce, Zookeeper, HBase, HCatalog, và nhiều hơn nữa. Also, như thị trường cho Hadoop tiếp tục mở rộng, công cụ mới được thêm vào số này mỗi ngày.
Sau đây là một sơ đồ kiến trúc sợi điển hình.
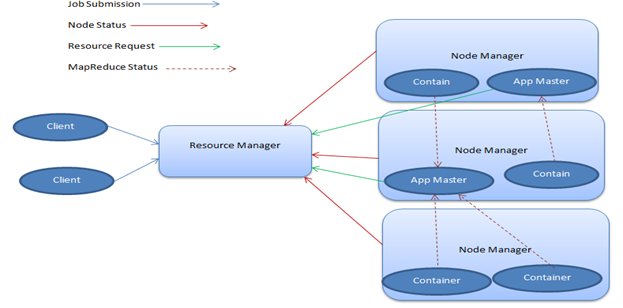
sơ đồ SỢI Kiến trúc
Image3: sơ đồ SỢI Kiến trúc
Khung MapReduce
MapReduce được cho là trung tâm của hệ thống Hadoop. Đó là khuôn khổ chương trình mà cho phép bằng văn bản của các ứng dụng xử lý song song của nhiều bộ dữ liệu có sẵn trên hàng trăm hoặc hàng ngàn máy chủ một số trong một cụm Hadoop.
Ý tưởng cơ bản đằng sau làm việc của nó là việc lập bản đồ và làm giảm các nhiệm vụ. Các bản đồ chức năng chịu trách nhiệm cho việc lọc và phân loại dữ liệu, trong khi Giảm chức năng thực hiện các hoạt động tóm tắt nhất định. MapReduce quá đến với phần công bằng của các khía cạnh quan trọng rằng viện trợ trong việc đạt được thành công sản xuất, đó là
Flexibility
MapReduce có thể xử lý dữ liệu của tất cả các loại, cho dù nó được cấu trúc, bán cấu trúc hoặc không có cấu trúc. Đây là một trong những khía cạnh quan trọng mà làm cho nó trở thành một phần quan trọng của toàn bộ kiến trúc Hadoop.
Khả năng tiếp cận
Một loạt các ngôn ngữ được hỗ trợ bởi MapReduce, trong đó cho phép các nhà phát triển để làm việc thoải mái. thực tế, MapReduce cung cấp hỗ trợ cho Java, Python và C , và cũng cho các ngôn ngữ cấp cao như Apache Pig và Hive.
Scalability
Là một phần không thể thiếu của kiến trúc Hadoop, MapReduce đã được thiết kế hoàn hảo trong một cách mà nó phù hợp với các cấp khả năng mở rộng lớn được cung cấp bởi HDFS. Điều này đảm bảo xử lý dữ liệu không giới hạn, tất cả dưới một nền tảng hoàn chỉnh.
Làm thế nào các thành phần Hadoop đảm bảo thành công sản xuất?
Trong một môi trường sản xuất, khả năng mở rộng là một trong những tiêu chí chính để kinh doanh thành công. Bởi vì, nếu ứng dụng không thể quy mô (mà chạy trên HDFS) trong giờ cao điểm, sau đó nó sẽ không thể để hỗ trợ số lượng ngày càng tăng của khách hàng. Kết quả là các doanh nghiệp sẽ bị mất tiền. So, từ quan điểm kiến trúc của xem nó là rất quan trọng để có khả năng lưu trữ và xử lý khả năng mở rộng, mà Hadoop có thể cung cấp với hệ thống tập tin phân tán của nó (HDFS).
Các HDFS khác có tính năng như tính linh hoạt để hỗ trợ bất kỳ loại dữ liệu; sự đáng tin cậy (lỗi khoan dung) trong trường hợp của một sự sụp đổ hệ thống cũng cho biết thêm giá trị cho một môi trường sản xuất. File I / O và khối vị trí cũng rất quan trọng vì nó hỗ trợ quản lý dữ liệu rất hiệu quả trong một môi trường clustered. Vì vậy, chúng ta có thể kết luận rằng sự thành công sản xuất của bất kỳ ứng dụng Hadoop majorly phụ thuộc vào kiến trúc HDFS tự.
Trong một cluster điển hình của 4000 nodes, chúng ta có thể có xung quanh 65 triệu tập tin và 80 triệu khối. Mỗi khối là có 3 bản sao, vì vậy mỗi nút sẽ có 60,000 khối. Đây là một trường hợp điển hình tại quản lý dữ liệu của Yahoo. Vì vậy, nó sẽ cho một ý tưởng về giá vé nhóm môi trường và lưu trữ dữ liệu.
kiến trúc sợi cung cấp một quản lý tài nguyên hiệu quả đó là giới thiệu trong Hadoop 2.0 architecture. Nó đảm bảo quản lý tài nguyên thích hợp trong môi trường sản xuất.
Ngoài các thành phần, lập trình MapReduce giúp trong xử lý song song dữ liệu trong một môi trường phân phối. Vì vậy, một xử lý nhanh hơn là đạt được trong hệ thống sản xuất để hỗ trợ nhu cầu thế giới thực.
Kết luận
Nó cũng được biết rằng Big Dữ liệu được thiết lập để thống trị các lần sắp tới trong xử lý dữ liệu, và với các hệ sinh thái Hadoop nó được phát triển mạnh hiện nay, nó cũng được dự kiến sẽ là người đi tiên phong trong miền. Hầu như tất cả các công cụ dựa trên dữ liệu được thực hiện theo cách của họ với Hadoop, để đối phó với những thách thức sẽ phải đối mặt trong tương lai gần. kiến trúc Hadoop được xây dựng để quản lý những khối lượng lớn dữ liệu trong một môi trường phân phối. Mỗi và mọi thành phần của nền tảng Hadoop được thực hiện để xử lý các loại cụ thể các chức năng. So, như một toàn thể nó đảm bảo sự thành công sản xuất của bất kỳ ứng dụng bigdata. Nhưng chúng ta cũng cần phải nhớ rằng các công nghệ liên quan bigdata cũng đóng một vai trò quan trọng trong việc triển khai ứng dụng và thành công trong các tình huống thực tế đời sống.