Superrigardo:
Hadoop estas platformo kiu estas preskaŭ sinonima kun Granda Datumo. Ĝi estas resume malferma fonta kadro kiu permesas la tenadon kaj pretiganta de clustered datumo-aroj grandskale. Unuavice, La Hadoop arkitekturo estas konata konsisti de kvar gravaj kapsuloj, Kiu estas HDFS (HAdoop DIstributed FIle SYstem), Hadoop Ofta, ŜPINITAĴO Kaj MapReduce. Ĉiu unu el ĉi tiuj kapsuloj estas fiksita elfari certajn specifajn taskojn, Kiu venas kune ĝenerale renkonti datumojn pretiganta postulojn. Unu el la kernaj flankoj al produktada sukceso estas la Hadoop arkitekturo. Ĉi tiu arkitekturo proponas plurajn kernajn ĉefaĵojn kiu estas priresponda por ĝia populareco super aliaj kadroj kiel de nun. Tamen, Estas ankaŭ kelkaj aliaj aferoj konsideri por la sukcesa efektivigo de Hadoop. Tio ĉi signifas, Ĝi ne estas preskaŭ havanta konvenan tenadan sistemon de rekordoj aŭ la 24×7 Kuranta de aplikoj, Sed ankaŭ kiel ĝi integrigas kun la entuta arkitekturo kaj iloj de entrepreno.
Ĉi tiu artikolo plejparte diskutos la Hadoop arkitekturo en detalo kune kun la avantaĝoj ĉiuj kapsulaj proponoj. Ni ankaŭ kovros produktadan sukceson aferoj.
Sekvanta estas simpla Hadoop arkitektura skemo por 2.0 Versioj
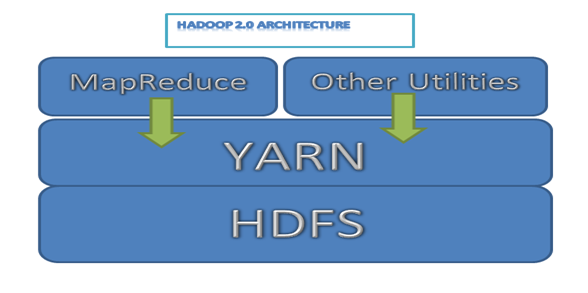
Hadoop 2.0 Arkitekturo
Bildo 1: Hadoop 2.0 Arkitekturo
HDFSa Arkitekturo
Kiel menciita jam, Hadoop HDFS certe estas unu el la kernaj eroj de la tuta kadro. Ĝi estas la kapsulo kiu estas tasked kun provizanta fidindan, Konstanta kaj distribuita tenadan sistemon trans pluraj nodoj kiu estas donaco en Hadoop grapolo.
Nun, Grapolo kutime konsistas de pluraj nodoj kiu estas ligita kune formi unu kompletan dosieran sistemon. Ĉiuj de la datumo kiu devas esti entenita estas ĉe unue rompita en pluraj malgrandaj blokoj sciita kiel blokoj. Ĉi tiuj blokoj estas tiam distribuita kaj entenita trans pluraj nodoj de la grapolo. Tio ĉi estas la maniero en kiu la Hadoop dosiera sistemo estas konstruita kaj ĝi havas certajn avantaĝojn ankaŭ.
Lasi nin havas rigardi la aliaj ĉefaĵoj de HDFS.
Scalable
Pro la ĉeesto de distribuita dosieran sistemon arkitekturo, la mapo de Hadoop kaj redukti funkcian laboron kiel brizo. Ĉi tiuj funkcioj povas esti facile efektivigita sur malgrandaj subgrupoj de la originala datumo, Tiel proponanta treegan scalability. Tio ĉi estas ankaŭ plia avantaĝo por komercoj, Kiel ili nur povas aldoni servilojn linearly, Kiam ilia datumo ŝajnas kreski.
Fleksebla
Alia tre avantaĝa flanko de HDFS estas ĝia tre fleksebla naturo en terminoj de tenado de datumo. Estanta malferma fonto, Hadoop facile povas kurita sur komercaĵa ladaĵejo, Kiu savas kostojn tremendously. Ankaŭ, La Hadoop dosiera sistemo povas enteni ajnan specon de datumo, Ĉu ĝi estas strukturita, Unstructured, Formatted aŭ eĉ kodita.
Hadoop eĉ faras ĝin ebla por unstructured datumo esti valora al organizo dum decido faranta procezon, io kiu estis preskaŭ unheard de antaŭe.
Fidinda
La Hadoop dosiera sistemo estas misfaro tolerant, Kiu signifas ke la datumo entenita en HDFS estas reproduktita al minimuma du aliaj lokoj. Tiel, En kazo estas disfalo de sistemo aŭ du, Estas ĉiam tria sistemo kiu havos kopion de ĉiuj via datumo. La sistemo tiam povas asigni workloads al ĉi tiu loko kaj ĉio povas labori normale.
Registri I/O
La efikeco de ajna dosiera sistemo dependas al kiel ĝi elfaras la I/O operaciojn. En HDFS, Datumoj estas aldonita de kreanta novan dosieron kaj skribi la datumon tie. Post kiam tio ĉi, La dosiero estas fermita kaj la skriba datumo ne povas esti forigita aŭ modifis anymore. Sed nova datumo povas esti almetita de re-malfermanta la dosieron. Do la baza fundamento de HDFS estas ‘Ununura skribi kaj oblo legita’ Modelo.
Bloka Allokigo
En HDFS, Dosiero estas kombinaĵo de multoblaj blokoj. Por aldonanta novan blokon, NameNode asignas unikan blokan identigaĵon kaj aldoni ĝin al la dosiero. Post kiam tio ĉi la nova bloko estas ankaŭ reproduktita en multobla DataNodes.
HDFSa bloko allokiga politiko estas agordebla, Do la uzantoj povas eksperimenti kun malsamaj alternativoj akiri optimumigita solvojn. De nerepago, HDFSa bloko allokiga politiko provoj minimumigi la skribi kostita kaj maksimumigi la legita elfaron, havebleco kaj fidindeco. Efektivigi tion ĉi, Kiam nova bloko estas aldonita dosieron, La unua kopio estas lokita sur la sama nodo kie la verkisto estas donaco. Post kiam tio ĉi, La 2a kaj 3a kopio estas poziciigita sur du malsamaj nodoj en aparta rako. Nun la ripozo de la kopioj estas lokita hazarde. Sed la restrikto estas tio, Unu nodo ne povas teni pli da ol unu kopio kaj unu rako ne povas teni pli da ol du kopioj.
Sekvanta bildon montras tipan kazon de kopiaj allokigoj en raka medio (Kiel priskribita en la supra sekcio)
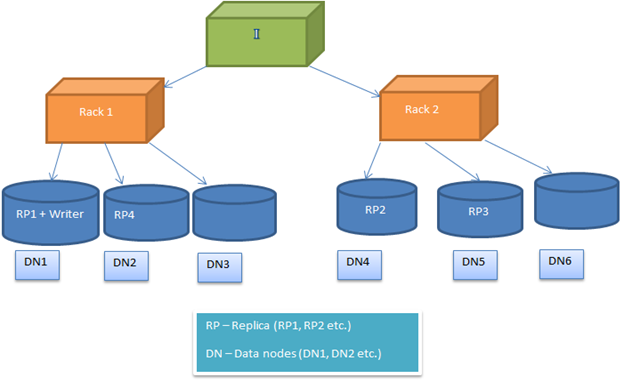
Kopia allokigo
Image2: Rezulta kopio allokigo en du raka medio
Hadoop Ofta/Hadoop Kerno
Hadoop ofta konsistas de la ofta aro de iloj subteni Hadoop arkitekturo. Ĉi tiuj estas resume bazi APIs helpi aliajn kapsulojn komunikas kun ĉiu alia. Ĝi estas ankaŭ konsiderita kiel grava parto de Hadoop arkitekturo kiel HDFS, MapReduce kaj ŜPINITAĴO. Ĝi provizas abstraction supre de la fundamentaj kernaj ĉefaĵoj kiel dosiera sistemo, OS ktp.
ŜPINITAĴA Infrastrukturo
ŜPINITAĴO, Aŭ ‘YEt ANother REsource NEgotiator', Estas la kapsulo en Hadoop kiu estas priresponda por la administrado de computational rimedoj. Kiel tia, Ĝi asignas CPUs aŭ memoron, Bazita sur la tasko kiu estas mane. Nun, ŜPINITAĴO estas unuavice farita supre de du majoro forlasas – la Rimedan Manaĝeron kaj la Nodan Manaĝeron.
- Rimeda Manaĝero
La Rimeda Manaĝero, Kiu estas ankaŭ plu-gvidita al kiel la mastro, Havas ununuran ĉeeston en grapolo kaj kuras plurajn servojn. Ĝi tenas vojeton de kie la laboristoj estas troviĝita kaj ankaŭ administras la Rimedon Scheduler, Kiu asignas rimedojn.
- Noda Manaĝero
La Noda Manaĝero okazas esti la laboristo de la infrastrukturo kaj tie povas esti multaj de ili en Hadoop grapolo. Ĉiu de ĉi tiuj Nodaj Manaĝeraj proponaj rimedoj al la grapolo. Ĝia kapacito de rimedoj estas mezurita en la formo de memoro kaj vcores (Interŝanĝado de CPUaj kernoj). La Rimeda Manaĝero utiligas rimedojn de la Noda Manaĝero, Kiam ĝi devas kuri taskon.
Hadoop ŜPINITAĴO havas certan tre avantaĝaj flankoj kiu faras ĝin grava parto de la arkitekturo. Ĉi tiuj estis skizita en detalo.
Multi-luado
Unu el Hadoop plej grandaj avantaĝoj de ŜPINITAĴO estas ke ĝi subtenas dinamikan rimedan administradon. Malgraŭ dividanta la rimedojn de la sama grapolo, Ĝi estas kapabla kuri multoblajn motorojn kaj workloads. Kaj, Nur kiel HDFS, ŜPINITAĴO estas ankaŭ tre scalable, Kiu proponas masivan enhorariganta kapablojn, Neniu gravi kion la workload povas esti.
Robustness
Hadoop ŜPINITAĴAJ proponoj robustness, Kiu permesas vin malfermi supre vian datumon al vario de iloj kaj teknologioj kiu povas helpi vin akiri la plej bonan ekstere de datuma pretigo. Ĝia ekosistemo estas puta aranĝo renkonti la bezonojn de diversaj ellaborantoj kaj ankaŭ organizoj de malgranda kaj granda skalo.
Fakte, Hadoop nuntempe venas kun pluraj konataj projektoj kiel Hive, MapReduce, Zookeeper, HBase, HCatalog, Kaj tre pli. Ankaŭ, Kiel la merkato por Hadoop tenas vastiganta, Pli novaj iloj estas aldonita tion ĉi kalkulas ĉiun tagon.
Sekvanta estas tipa ŜPINITAĴA arkitektura skemo.
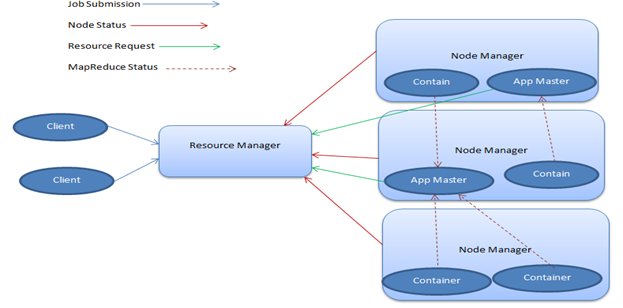
ŜPINITAĴA Arkitekturo skemo
Image3: ŜPINITAĴA Arkitekturo skemo
MapReduce Kadro
MapReduce estas dirita esti la koro de la Hadoop sistemo. Ĝi estas la programara kadro kiu permesas por la skribo de aplikoj por paralela pretigo de granda datumo-aroj havebla trans pluraj centoj aŭ miloj de serviloj en Hadoop grapolo.
La baza ideo malantaŭ ĝia laboranta estas la mapado kaj reduktanta de taskoj. La Mapa funkcio estas priresponda por la filtranta kaj ordiganta de datumo, Dum la Redukti funkcion efektivigas certajn resumajn operaciojn. MapReduce ankaŭ alvenas kun ĝia justa interŝanĝado de gravaj flankoj ke helpo en atinganta produktadan sukceson, Kiu estas
Fleksebleco
MapReduce povas pretigi datumon de ĉiuj tipoj, Ĉu ĝi estas strukturita, Semi-strukturita aŭ unstructured. Tio ĉi estas unu el la kernaj flankoj kiu faras ĝin grava parto de la tuta Hadoop arkitekturo.
Alirebleco
Larĝa gamo de lingvoj estas subtenita de MapReduce, Kiu permesas ellaborantojn labori komforte. Fakte, MapReduce provizas subtenon por Java, Python kaj C , Kaj ankaŭ por alta-nivelaj lingvoj kiel Apache Porko kaj Hive.
Scalability
Estanta havenda parto de la Hadoop arkitekturo, MapReduce estis perfekte desegnita en maniero ke ĝi egalas la masivan scalability niveloj proponita de HDFS. Tio ĉi certigas senliman datuman pretigon, Ĉiuj sub unu kompleta platformo.
Kiom Hadoop eroj certigas produktadan sukceson?
En produktada medio, Scalability estas unu el la ĉefaj kriterioj por komerca sukceso. Ĉar, Se la apliko ne povas grimpi (Kiu kuroj sur HDFS) Dum pintaj horoj, Tiam ĝi ne estos kapabla subteni kreskantan nombron de klientoj. Rezulte la komerco perdos monon. Tiel, De arkitektura punkto de vido ĝi estas tre grava havi scalable tenado kaj pretiganta kapablojn, Kiu Hadoop povas provizi kun ĝia distribuita dosieran sistemon (HDFS).
La aliaj HDFSaj ĉefaĵoj kiel fleksebleco por subtenanta ajnan tipon de datumo; Fidindeco (Misfaro tolerant) En kazo de sistema disfalo ankaŭ aldonas valoron al produktada medio. Registri I/O kaj bloka allokigo estas ankaŭ grava kiel ĝi subtenas datuman administradon tre efike en clustered medio. Do ni povas konkludi ke la produktada sukceso de ajna Hadoop apliko majorly dependas al la HDFSa arkitekturo ĝi mem.
En tipa grapolo de 4000 Nodoj, Ni povas havi proksimume 65 Miliono da dosieroj kaj 80 Miliono da blokoj. Ĉiu bloko estas havanta 3 Kopioj, Do ĉiu nodo havos 60,000 Blokoj. Tio ĉi estas tipa kazo ĉe Yahoo datuma administrado. Do ĝi donas veturoprezan ideon pri clustered medio kaj datuma tenado.
ŜPINITAĴA arkitekturo provizas efikan rimedan administradon kiu estas enkondukas en Hadoop 2.0 Arkitekturo. Ĝi certigas konvenan rimedan administradon en produktada medio.
Krom la eroj, MapReduce programaraj helpoj en paralela pretigo de datumo en distribuita medion. Do pli rapida pretigo estas atingita en produktada sistemo subteni verajn mondajn postulojn.
Konkludo
Ĝi estas bone sciita ke Granda Datumo estas fiksita superregi la okazontajn tempojn en datuma pretigo, Kaj kun la Hadoop ekosistemo ĝi estas viglanta nuntempe, Ĝi estas ankaŭ atendita esti la frontrunner en la domajno. Preskaŭ ĉiuj datumo-bazitaj iloj estas farantaj ilian vojon kun Hadoop, Por rebati la defiojn atendita esti alfrontita en la proksima estonteco. Hadoop arkitekturo estas konstruita administri ĉi tiujn grandegajn volumojn de datumo en distribuita medion. ĉiu kaj ĉiu ero de Hadoop platformo estas farita pritrakti specifajn tipojn de funkcioj. Tiel, Ĝenerale ĝi certigas produktadan sukceson de ajna bigdata apliko. Sed ni ankaŭ devas memori ke la rilata bigdata teknologioj ankaŭ ludas gravan rolon en aplika deplojo kaj ĝia sukceso en veraj vivaj scenaroj.