Oversigt: Vi er godt klar over funktionerne i Hadoop og HDFS. I dette dokument vil vi tale om HDFS føderation, som hjælper os til at forbedre et eksisterende HDFS arkitektur. Det giver en klar adskillelse mellem namespace og opbevaring dermed muliggør skalerbarhed og isolation på klyngeniveau.
Indledning: Hadoop føderation adskiller namespace lag og opbevaringslag. Det muliggør blok oplagringslaget. Det udvider også arkitekturen i en eksisterende HDFS klynge for at tillade nye implementeringer og use cases. Den nuværende HDFS arkitektur har to lag -
- navneområde - Dette lag administrerer filer, mapper og blokke. Dette lag understøtter de grundlæggende filsystemet operationer f.eks. notering af filer, oprettelse af filer, ændring af filer og sletning af filer og mapper.
- Block baggage - Dette lag består af to dele -
- Block Management Dette styrer datanodes i klyngen og giver operationer som skabelse, sletning, modifikation og søgning. Det tager sig også af replikation ledelse.
- fysisk Opbevaring Dette gemmer blokkene og giver adgang til læse eller skrive operationer.
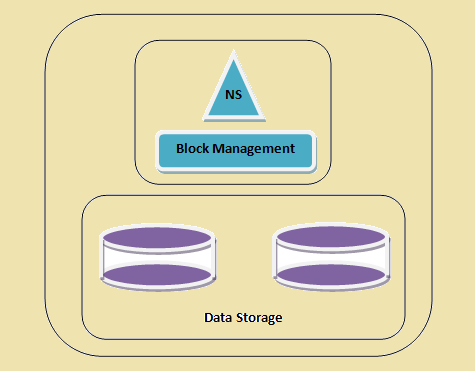
En HDFS klynge
Figure 1: En HDFS klynge
I den nuværende HDFS arkitektur, vi har kun én namespace for hele klyngen, som ledes af ét navn node. Ved hjælp af denne metode bliver det lettere at gennemføre HDFS klyngen. Denne lagdeling af arkitektur fungerer fint til mindre opsætninger, mens til større organisationer, hvor der skal tages pleje på en hurtig hastighed en enorm mængde data, f.eks. Yahoo og Facebook blev det konstateret, at denne fremgangsmåde har nogle begrænsninger, som håndteres af Hadoop forbund. Så Hadoop føderation kan defineres som den avancerede arkitektur til at overvinde de begrænsninger af nuværende HDFS implementering.
Lad os se de begrænsninger som beskrevet nedenfor -
- Tæt koblet Block Opbevaring og Namespace - I den nuværende arkitektur blokken opbevaring og Namespace er tæt koblet, hvilket gør de alternative implementeringer af navn noder udfordrende og begrænser andre tjenester til at bruge blokken opbevaring direkte.
- Namespace Skalerbarhed - Den HDFS klynge skaleres horisontalt ved at tilføje datanodes men vi kan ikke tilføje mere namespace til en eksisterende klynge vandret. Vi kan skalere navnerum lodret på en enkelt namenode. Den namenode gemmer det komplette filsystemet metadata inden sin hukommelse, der begrænser antallet af blokke, filer og mapper, der skal støttes på filsystemet, der skal rummes i hukommelsen af det indre namenode.
- Ydeevne - Det aktuelle filsystem operationerne er begrænset til gennemløb af ét navn knudepunkt, som på nuværende tidspunkt støtter 60000 samtidige opgaver. Men den nye kommende kortet reducere fra Apache vil have en støtte i mere end 100000 samtidige opgaver og vil således kræve flere noder.
- Isolering - Generelt HDFS implementeringer er tilgængelige på et multi-lejer miljø, hvor en enkelt klynge deles af flere organisationer. I denne opsætning en separat namespace er ikke muligt for en applikation eller en organisation.
HDFS Federation:
Hadoop forbund tillader skalering navnet tjeneste vandret. Det bruger flere namenodes eller navnerum der er uafhængige af hinanden. Disse er uafhængige namenodes organisationsnetværk i.e. de ikke kræver inter koordinering. Disse datanodes anvendes som fælles lagring af alle namenodes. Hver datanode er registreret med alle namenodes i klyngen. Disse datanodes sende periodiske rapporter og reagerer på de kommandoer fra navnet noder. Vi har en blok pool, som er et sæt af blokke, der tilhører en enkelt namespace. I en klynge, de datanodes gemmer blokke til alle blok puljer. Hver blok pool styres uafhængigt. Dette gør det muligt navnet plads til at generere blok id'er for nye blokke uden at informere andre navnerum. Hvis en namenode mislykkes eller anden grund, den datanode holder på servering fra andre namenodes.
Et namespace og dens blok er kollektivt kaldes navnerum Volume. Når en navnerum eller en namenode slettes den tilsvarende blok pool på datanode slettes automatisk. I processen med klynge up-gradation, hver namespace volumen opgraderes som en enhed.
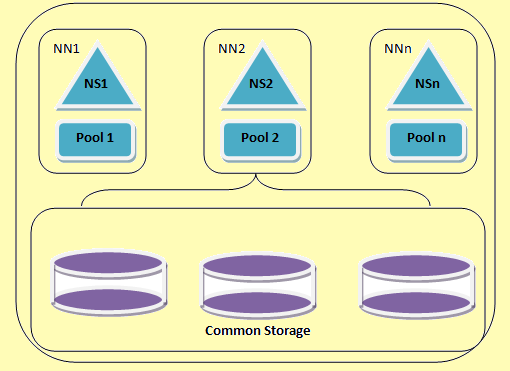
En HDFS føderation arkitektur
Figure 2: En HDFS føderation arkitektur
Fordele ved Hadoop Federation:
Hadoop føderation kommer op med nogle fordele og ulemper, der er opført som under -
- Skalerbarhed og isolation - Flere namenodes vandret skalaer op i filsystemet namespace. Dette faktisk adskiller namespace mængder for brugere og kategorier af ansøgningen og giver en absolut isolation.
- Generic opbevaring service - abstraktion Blokken niveau pool giver arkitekturen at bygge nye filsystemer på toppen af blok opbevaring. Vi kan nemt bygge nye applikationer på blokken opbevaring lag uden at bruge filsystemet grænseflade. Tilpassede kategorier af blok pulje kan også bygges som er forskellige fra standard blok pool.
- Simple Design - Namenodes og namespaces er uafhængige af hinanden. Der er næppe nogen scenarie, som kræver ændring af eksisterende navn noder. Hvert navn node er bygget til at være robust. Føderation er også bagudkompatibel. Den kan nemt integreres med de eksisterende enkelt node implementeringer, som arbejder uden konfigurationsændringer.
Konfiguration af en HDFS Federation:
Konfiguration af Hadoop Føderation er udformet på en sådan måde, at alle knudepunkter i klyngen har samme konfiguration. Konfigurationen udføres i de følgende trin -
- Step 1 - Følgende parametre skal tilsættes i eksisterende konfiguration -
- nameservices - Dette er konfigureret med en liste over kommaseparerede NameServiceIDs. Denne parameter anvendes af Datanodes fastlægge alle namenodes i klyngen.
- Step 2 - Følgende konfigurationer skal udvides med tilsvarende navn service-id'et i den fælles konfigurationsfil.
- Namenode
- Secondary NameNode
- BackupNode
En prøve konfigurationsfil til to namenodes er vist nedenfor -
Listing 1: En Prøve konfigurationsfil til to knuder
[Code]
<konfiguration>
<ejendom>
<navn>dfs.nameservices</navn>
<værdi>NS1, NS2</værdi>
</ejendom>
<ejendom>
<navn>dfs.namenode.rpc-address.ns1</navn>
<værdi>nn-host1:6600</værdi>
</ejendom>
<ejendom>
<navn>dfs.namenode.http-address.ns1</navn>
<værdi>nn-host1:8080</værdi>
</ejendom>
<ejendom>
<navn>dfs.namenode.secondaryhttp-address.ns1</navn>
<værdi>NHS-host1:8080</værdi>
</ejendom>
<ejendom>
<navn>dfs.namenode.rpc-address.ns2</navn>
<værdi>nn-host2:6600</værdi>
</ejendom>
<ejendom>
<navn>dfs.namenode.http-address.ns2</navn>
<værdi>nn-host2:8080</værdi>
</ejendom>
<ejendom>
<navn>dfs.namenode.secondaryhttp-address.ns2</navn>
<værdi>NHS-host2:8080</værdi>
</ejendom>
</konfiguration>
[/Code]
Formatering af Namenode: Lad os kommandoerne til format namenode.
- Step 1 – En enkelt navn node kan formateres ved hjælp af følgende -
$HADOOP_USER_HOME / bin / HDFS namenode -format [-klynge- <cluster_id>]
Klyngen id skal være unikt og må ikke være i modstrid med andre spændende klynge id. Hvis ikke forudsat, en unik klynge id genereres ved formatering.
- Step 2 - Yderligere namenode kan formateres ved hjælp af følgende kommando -
$HADOOP_PREFIX_HOME / bin / HDFS namenode -format -clusterId <cluster_id>
Det er her vigtigt, at den her nævnte klynge id bør være den samme i nævnte nævnt i trin 1. Hvis disse to er forskellige, den ekstra namenode vil ikke være en del af den føderale klynge.
Start og stop af klyngen: Lad os se de kommandoer til at starte og stoppe klyngen.
- Start klyngen - Klyngen kan startes ved at udføre følgende kommando -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
- Stop klyngen - Klyngen kan stoppes ved at udføre følgende kommando -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
Tilføj en ny namenode til en eksisterende klynge: Vi har allerede beskrevet, at flere navne node er kernen i Hadoop føderation. Så er det vigtigt at forstå de skridt til at tilføje nye navn noder og skalere horisontalt.
er behov for følgende trin for at tilføje nye namenodes -
- Konfigurationen parameter - nameservices skal tilføjes i konfigurationen.
- NameServiceID skal suffiks i konfigurationen
- Ny Namenode relateret til config skal lægges i konfigurationsfiler.
- Konfigurationsfilen skal udbredes til alle knuder i klyngen.
- Start det nye namenode og den sekundære namenode
- Opdater de andre datanodes at vælge den nyligt tilføjede namenode ved at køre følgende kommando -
o $HADOOP_PREFIX_HOME/bin/hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
- Ovenstående kommando skal udføres mod alle datanodes på klyngen.
Summary: HDFS forbund er indført for at overvinde de begrænsninger af tidligere HDFS implementering. Tilføjelse skalerbarhed ved namespace lag er det vigtigste element i HDFS føderation arkitektur. Men HDFS forbund er også bagudkompatibel, så enkelt namenode konfiguration vil også arbejde uden ændringer.
Lad os opsummere vores diskussion i form af følgende kugler
- HDFS føderation adskiller namenode lag og opbevaringslag.
- HDFS forbund er designet til at overvinde de begrænsninger af den enkelt node HDFS arkitektur, hvor opbevaringen kan skalere op horisontalt ikke navnerummet.
- HDFS føderation kommer op med følgende fordele -
- Isolation
- Scalability
- simple design
- HDFS konfiguration er meget enkel og er også let at administrere.