Агляд: Мы добра дасведчаныя аб асаблівасцях Hadoop і HDFS. У гэтым дакуменце мы будзем казаць пра федэрацыі HDFS, якая дапамагае нам умацаваць існуючую архітэктуру HDFS. Гэта забяспечвае выразны падзел паміж прасторай імёнаў і захоўвання, такім чынам, забяспечвае маштабаванасць і ізаляцыю на ўзроўні кластара.
Увядзенне: Hadoop федэрацыя падзяляе прастору імёнаў пласт і запамінальны пласт. Гэта дазваляе пласт захоўвання блока. Яна таксама пашырае архітэктуру існуючага кластара HDFS, каб новыя рэалізацыі і прыклады выкарыстання. Бягучая архітэктура HDFS мае два пласта -
- Прастору імёнаў - Гэты пласт кіруе файламі, каталогі і блокі. Гэты пласт падтрымлівае асноўныя аперацыі файлавай сістэмы e.g. спіс файлаў, стварэнне файлаў, мадыфікацыя файлаў і выдаленне файлаў і тэчак.
- Блок захоўвання - Гэты пласт складаецца з двух частак -
- кіраванне Блок Гэта кіруе DataNode, у кластары і забяспечвае такія аперацыі, як стварэнне, выдаленне, мадыфікацыя і пошук. Яно таксама клапоціцца аб кіраванні рэплікацыі.
- фізічнае сховішча Гэта захоўвае блокі і забяспечвае доступ для чытання або запісы.
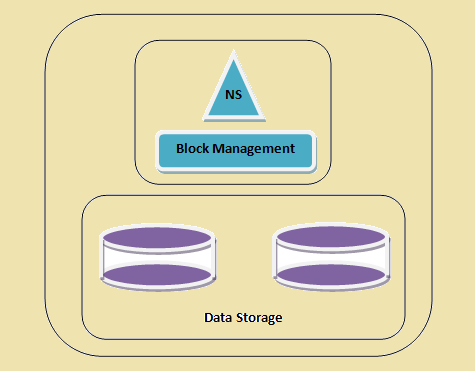
кластара HDFS
Figure 1: кластара HDFS
У бягучай архітэктуры HDFS, у нас ёсць толькі адна прастора імёнаў для ўсяго кластара, які кіруецца адным вузлом імёнаў. Выкарыстоўваючы гэты падыход становіцца лягчэй рэалізаваць кластар HDFS. Гэта напластаванне архітэктуры выдатна працуе для невялікіх установак у той час як для буйных арганізацый, дзе велізарны аб'ём дадзеных неабходна паклапаціцца пры хуткай хуткасці, e.g. Yahoo і Facebook было ўстаноўлена, што гэты падыход мае некаторыя абмежаванні, якія апрацоўваюцца федэрацыяй Hadoop. Так Hadoop федэрацыя можа быць вызначана як перадавой архітэктуры для пераадолення абмежаванняў бягучай рэалізацыі HDFS.
Давайце праверым абмежаванні, як апісана ніжэй -
- Сильносвязанной Блок захоўвання і прастора імёнаў - У бягучай архітэктуры захоўвання блока і прастора імёнаў цесна звязаныя, што робіць альтэрнатыўныя рэалізацый імёнаў вузлоў складаных і абмяжоўвае іншыя паслугі, выкарыстоўваць для захоўвання блок непасрэдна.
- Прастору імёнаў Маштабаванасць - Кластара HDFS шкалы па гарызанталі шляхам дадання DataNode, але мы не можам дадаць больш імёнаў у існуючы кластар па гарызанталі. Мы можам маштабаваць прастору імёнаў па вертыкалі на адным NameNode. NameNode захоўвае поўны метададзеных файлавай сістэмы ў межах сваёй памяці, якая абмяжоўвае колькасць блокаў, файлы і каталогі, якія будуць падтрымлівацца ў файлавай сістэме, якая павінна быць размешчаная ў памяці аднаго NameNode.
- прадукцыйнасць - Бягучыя аперацыі файлавай сістэмы абмежаваныя прапускной здольнасці аднаго вузла імя, якое ў цяперашні час апоры 60000 паралельныя задачы. Але новая карта прыходзіць ад Apache скарачэння будзе мець падтрымку больш чым 100000 паралельныя задачы і, такім чынам, спатрэбіцца некалькі вузлоў.
- ізаляцыя - У цэлым разгортванняў HDFS даступныя на асяроддзі шматкарыстальніцкіх, дзе адзін кластар сумесна некалькімі арганізацыямі. У гэтай ўстаноўцы асобнае прастору імёнаў не ўяўляецца магчымым для аднаго прыкладання або адной арганізацыі.
HDFS Федэрацыя:
Hadoop федэрацыі дазваляе маштабаваць службу імёнаў па гарызанталі. Ён выкарыстоўвае некалькі namenodes або прастор імёнаў, якія не залежаць адзін ад аднаго. Гэта незалежныя namenodes Федэратыўны i.e. яны не патрабуюць каардынацыі паміж. Гэтыя вузлы DataNode выкарыстоўваюцца ў якасці агульнага сховішча усімі namenodes. Кожны DataNode зарэгістраваны з усімі namenodes у кластары. Гэтыя вузлы DataNode перыядычна пасылаюць справаздачы і рэагуе на каманды з вузлоў імёнаў. У нас ёсць блок-пул, які ўяўляе сабой набор блокаў, якія належаць да аднаго прасторы імёнаў. У кластары, у DataNodes захоўвае блокі для ўсіх блокаў басейнаў. Кожны блок басейн кіруецца незалежна адзін ад аднаго. Гэта дазваляе прастору імёнаў для стварэння блокаў ідэнтыфікатараў для новых блокаў без інфармавання іншых прастор імёнаў. Калі NameNode трывае няўдачу па якой-небудзь прычыне, DataNode працягвае служыць з іншых namenodes.
Адна прастора імёнаў і яго блок разам называюцца Прастору імёнаў Аб'ём. Калі прастора імёнаў ці NameNode выдаляецца адпаведны блок пула на DataNode аўтаматычна выдаляецца. У працэсе кластар да градацый, кожны аб'ём прасторы імёнаў абнаўляецца як адзінае цэлае.
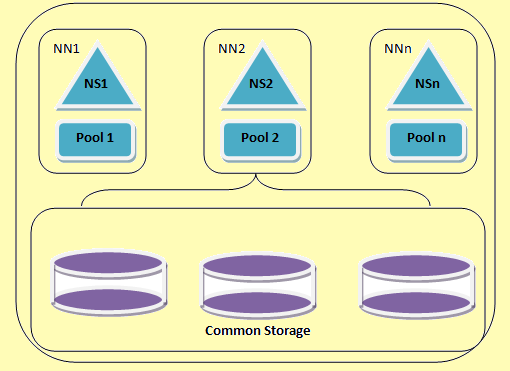
Архітэктура федэрацыі HDFS
Figure 2: Архітэктура федэрацыі HDFS
Перавагі Hadoop Федэрацыі:
Hadoop федэрацыя прыходзіць з некаторымі перавагамі і прывілеямі, якія пералічаны ў адпаведнасці з -
- Маштабаванасць і ізаляцыя - Некалькі namenodes гарызантальна маштабуецца ў прасторы імёнаў файлавай сістэмы. Гэта на самай справе падзяляе аб'ёмы прасторы імёнаў для карыстальнікаў і катэгорый прымянення і забяспечвае абсалютную ізаляцыю.
- Радавой служба захоўвання - Абстракцыі блочнага ўзроўню пула дазваляе архітэктура будаваць новыя файлавыя сістэмы на верхняй частцы блока захоўвання. Мы можам лёгка ствараць новыя прыкладанні на ўзроўні захоўвання блока без выкарыстання інтэрфейсу файлавай сістэмы. Настроеныя катэгорыі блока пула таксама могуць быць пабудаваны, якія адрозніваюцца ад блока пула па змаўчанні.
- Просты дызайн - Namenodes і прастор імёнаў не залежаць адзін ад аднаго. Існуе ці ледзь сцэнар, які патрабуе змены існуючых вузлоў імёнаў. Кожны вузел імя пабудаваны, каб быць надзейным. Федэрацыя таксама зваротную сумяшчальнасць. Ён лёгка інтэгруецца з існуючымі адзінкавымі разгортвання вузлоў, якія працуюць без якіх-небудзь змяненняў у канфігурацыі.
Налада HDFS Федэрацыі:
Канфігурацыя Hadoop Федэрацыі распрацавана такім чынам, што ўсе вузлы ў кластары маюць тую ж канфігурацыю,. Канфігурацыя ажыццяўляецца ў наступных кроках -
- Step 1 - Наступныя параметры павінны быць дададзены ў існуючай канфігурацыі -
- nameservices - Гэта наладжваецца са спісам падзеленых коскамі NameServiceIDs. Гэты параметр выкарыстоўваецца DataNodes для вызначэння ўсіх namenodes у кластары.
- Step 2 - Наступныя канфігурацыі неабходна суфіксам з адпаведным імем ідэнтыфікатар службы ў агульны канфігурацыйны файл.
- NameNode
- Secondary NameNode
- BackupNode
Прыклад файла канфігурацыі для двух namenodes паказаны ніжэй -
Listing 1: Файл канфігурацыі Прыклад для двух вузлоў
[Code]
<канфігурацыя>
<ўласнасць>
<імя>dfs.nameservices</імя>
<значэнне>ns1, NS2</значэнне>
</ўласнасць>
<ўласнасць>
<імя>dfs.namenode.rpc-address.ns1</імя>
<значэнне>дп-host1:6600</значэнне>
</ўласнасць>
<ўласнасць>
<імя>dfs.namenode.http-address.ns1</імя>
<значэнне>дп-host1:8080</значэнне>
</ўласнасць>
<ўласнасць>
<імя>dfs.namenode.secondaryhttp-address.ns1</імя>
<значэнне>НГС-host1:8080</значэнне>
</ўласнасць>
<ўласнасць>
<імя>dfs.namenode.rpc-address.ns2</імя>
<значэнне>дп-host2:6600</значэнне>
</ўласнасць>
<ўласнасць>
<імя>dfs.namenode.http-address.ns2</імя>
<значэнне>дп-host2:8080</значэнне>
</ўласнасць>
<ўласнасць>
<імя>dfs.namenode.secondaryhttp-address.ns2</імя>
<значэнне>НГС-host2:8080</значэнне>
</ўласнасць>
</канфігурацыя>
[/Code]
фарматаванне NameNode: Няхай нам каманды ў фармат NameNode.
- Step 1 – Адзін вузел імя можа быць адфарматаваны з дапамогай наступных -
$HADOOP_USER_HOME / bin / HDFS NameNode -format [-кластарны <CLUSTER_ID>]
Кластара ідэнтыфікатар павінен быць унікальным і не павінен ўступаць у супярэчнасць з любым іншым які выходзіць ідэнтыфікатара кластара. Калі не прадугледжана, унікальны кластар ID генеруецца ў момант фарматавання.
- Step 2 - Дадатковы NameNode можа быць адфарматаваны з дапамогай наступнай каманды -
$HADOOP_PREFIX_HOME / bin / HDFS NameNode -format -clusterId <CLUSTER_ID>
Тут важна, што кластар ID згаданыя тут павінны быць аднолькавымі, што згадваецца ў крок 1. Калі гэтыя два розныя, дадатковы NameNode не будзе часткай федэратыўнай кластара.
Запуск і прыпынак кластара: Давайце праверым каманды для запуску і прыпынку кластара.
- Запуск кластара - Кластар можа быць запушчаны, выканаўшы наступную каманду -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
- Спыніце кластар - Кластар можа быць спынены, выканаўшы наступную каманду -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
Дадайце новы NameNode ў існуючы кластар: Мы ўжо апісвалі, што множны імя вузла ў цэнтры Hadoop федэрацыі. Таму важна, каб зразумець, якія крокі для дадання новых вузлоў імёнаў і маштаб па гарызанталі.
Неабходныя наступныя крокі для дадання новых namenodes -
- Параметр канфігурацыі - nameservices павінна быць дададзеная ў канфігурацыі.
- NameServiceID павінен быць суфіксам у канфігурацыі
- Новы NameNode звязаныя з канфігурацыі павінны быць дададзены ў файлах канфігурацыі.
- Файл канфігурацыі павінен распаўсюджвацца на ўсе вузлы ў кластары.
- Пачаць новую NameNode і другасны NameNode
- Абновіце іншыя DataNode, каб выбраць новы даданыя NameNode, выканаўшы наступную каманду -
o $HADOOP_PREFIX_HOME/bin/hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
- Вышэй каманда павінна быць выканана супраць усіх DataNodes на кластары.
Summary: HDFS федэрацыя была ўведзена, каб пераадолець абмежаванні раней рэалізацыі HDFS. Даданне маштабаванасці на ўзроўні прасторы імёнаў з'яўляецца найбольш важнай асаблівасцю архітэктуры HDFS федэрацыі. Але HDFS федэрацыя таксама зваротную сумяшчальнасць, таму адзіная канфігурацыя NameNode таксама будзе працаваць без якіх-небудзь змяненняў.
Падагульнім наша абмеркаванне ў выглядзе наступных куль
- HDFS федэрацыя падзяляе NameNode пласт і запамінальны пласт.
- HDFS федэрацыя закліканая пераадолець абмежаванні архітэктуры адзінага вузла HDFS, дзе захоўванне можа маштабаваць гарызантальна а не прастору імёнаў.
- HDFS федэрацыя прыходзіць з наступнымі перавагамі -
- ізаляцыя
- Scalability
- просты дызайн
- канфігурацыя HDFS вельмі простая і таксама лёгка кіраваць.