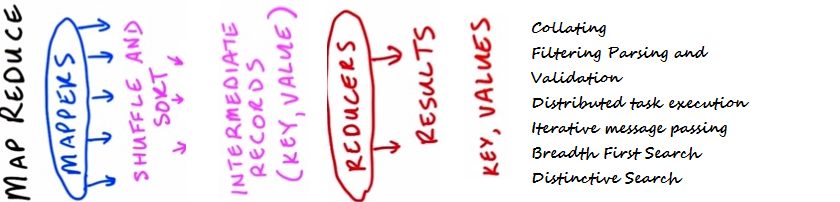
MapReduce design patterns
Overview: Design pattern is now a common term used in almost all fields of software development. Patterns are nothing but some proven and tested design techniques used to solve business problems. MapReduce is a new technology domain and it also has its own design patterns to solve data computation issues.
In this article, I will talk about different design patterns used in MapReduce framework.
Introduction: Map Reduce is used to process data which resides on a number of computers. It provides clear and distinctive boundaries between what we can and what we cannot. This makes the number of options we need to consider, lesser. At the same time, we can figure out how to solve a problem with constraints. Design patterns have been tested for many problems from time to time and have shown the right level of abstraction.
MapReduce design patterns occupy the same role in a smaller space of problems and solutions. They provide a general framework to solve our data computation related issues, without concentrating on the problem domain. MapReduce design patterns also provide a common language for teams working together on MapReduce applications.
MapReduce Design Pattern: Now let us discuss different design approaches one by one in the following section.
Calculating:
Problem Statement – Let us consider that we have a stack of documents where each document contains a set of terms. Now we have a requirement to calculate the number of occurrences of each term in the document.
Solution – In the following code snippet we have a Mapper that simply records ‘1’ for each term it encounters. The reducer here traverses throughout the list of such ones, sums them up and produces the result.
Listing 1: Computing Code – 1
[Code]
class Mapper
method Map(docid id, doc d)
for all term t in doc d do
Emit(term t, count 1)
class Reducer
method Reduce(term t, counts [c1, c2,…])
cnt = 0
for all count c in [c1, c2,…] do
cnt = cnt + c
Emit(term t, count cnt)
[/Code]
Though Simple, but the above code has an obvious disadvantage that a high amount of dummy counters are emitted by the Mapper. Now we can reduce this by summing the counters for each document.
Listing 2: Computing Code – 2
[Code]
class Mapper
method Map(docid id, doc d)
HArray = new AssociativeArray
for all term t in doc d do
HArray{t} = HArray{t} + 1
for all term t in HArray do
Emit(term t, count HArray{t})
[/Code]
Now, in order to accumulate the counters for all the documents lets have the combiners –
Listing 3: Computing Code – 3
[Code]
class Mapper
method Map(docid id, doc d)
for all term ter in doc d do
Emit(term ter, count 1)
class Combiner
method Combine(term ter, [c1, c2,…])
sum = 0
for all count cnt in [c1, c2,…] do
sum = sum + cnt
Emit(term t, count sum)
class Reducer
method Reduce(term t, counts [c1, c2,…])
totalCnt = 0
for all count cnt in [c1, c2,…] do
totalCnt = totalCnt + cnt
Emit(term t, count totalCnt)
[/Code]
Collating:
Problem Statement –
We have a set of items and some function of some items. Now it is required to save all the items that have the same value of function or perform some other computation which requires all such items to be processed in a group.
Solution –
We have the solution where the mapper computes the given function for each item and returns the value of the function as a key and the item as its value. The role of the reducer is to fetch all the grouped items and process them or save them.
Filtering (Grep), Parsing and Validation:
Problem Statement –
Let us consider we have a set of records and the requirement is to collect all the records that meet some condition or transform these records into some other representation formats. The second part of the problem includes tasks such as – text parsing and extraction of the values.
Solution –
Solution to this problem is quite straight forward – we have a mapper which takes one record at a time and returns the items which meet the criteria.
Distributed Task Execution:
Problem Statement –
Let us consider we have a large computational problem which can be divided into multiple parts and results from all of these parts needs to be combined in order to obtain the final result.
Solution –
Solution to this problem is to split the specifications into a set of specification which are stored as input data for the mappers. Each of these mappers takes one specification at a time as input data and processes them and produces the results. The job of the reducer is to combine all of these results and produces the final result.
Iterative Message Passing:
Problem Statement –
Let us consider we have a network of entities and there exists some relationship amongst them. We are required to calculate the state of each entity based on the property of other entity in the neighborhood. This state can be used to represent a distance to other nodes which is an indication that there is a neighbor having certain properties and characteristics.
Solution –
We have a network which stores a set of nodes and each node contains the information of a list of adjacent node IDs. Conceptually, the MapReduce jobs are performed in iterative way and at each iteration the node sends messages to its neighbors. And then each neighbor updates its state on the basis of the message that is received. These iterations are terminated by some condition e.g. fixed maximal number of iterations. From the technical point of view, the Mapper returns the messages for each node using the ID of the adjacent node as a key. As a result, all of these messages are grouped by the incoming node and hence the reducer is able to recalculate the state and rewrites the node with the new state.
Listing 4: Iterative messaging passing
[Code]
class Mapper
method Map(id nId, object NObj)
Emit(id nId, object NObj)
for all id mId in NObj.OutgoingRelations do
Emit(id mId, message getMessage(NObj))
class Reducer
method Reduce(id m, [s1, s2,…])
M = null
messages = []
for all s in [s1, s2,…] do
if IsObject(s) then
M = s
else // s is a message
messages.add(s)
M.State = calculateState(messages)
Emit(id m, item M)
[/Code]
Breadth First Search (This is a case study):
Problem Statement –
Let us consider we have a graph and it is required to calculate the distance from one source node to all other nodes present in the graph. This is also called the number of hops.
Solution –
The solution can be, first the source node emits 0 to all its neighbors. Then the neighbors propagate this counter after incrementing it by 1 for each hop.
Distinctive Values:
Problem Statement –
Let us consider we have a set of records that contain fields M and N. The requirement is to count the total number of unique values of field M for each subset of the same Group N.
Solution –
The solution to this problem can be addressed in two stages. In the first stage, the mapper produces dummy counters for each pair of M and N. Then the reducer counts the total number of occurrences for each pair. The objective of this phase is to maintain uniqueness of M values. In the second phase, pairs are grouped by N and the total numbers of items are calculated for each group.
Summary: In this article we have discussed different design approaches which are commonly used to solve data computation issues. MapReduce design patterns are continuously evolving, so we will see more design approaches in near future. Let us summarize our discussion in following bullets –
- Map reduce is used to process data which resides on a host of computers.
- Design patterns are being used to solve problems.
- Some commonly used MapReduce design patterns are listed under –
- Calculating – Counting and Summing
- Collating
- Filtering Parsing and Validation
- Distributed task execution
- Iterative message passing
- Breadth First Search
- Distinctive Search