Overview: With so many development frameworks around, it becomes important that we should be able to scale up our application at any given point of time. Machine learning techniques like clustering and categorization have become popular in this context. Apache Mahout is a framework that helps us to achieve scalability.
In this document, I will talk about Apache Mahout and its importance.
Introduction: Apache Mahout is an open source project from Apache Software Foundation or ASF which has the primary goal of creating machine learning algorithm. Introduced by a group of developers from the Apache Lucene project, Apache Mahout has the aim to –
- Build and support a community of users or contributors so that access to the source code for the framework is not limited to a small group of developers.
- Focus on the practical problems, rather than unseen or unproved issues.
- Provide appropriate documentation.
Features of Apache Mahout:
Apache Mahout comes with an array of features and functionalities especially when we talk about Clustering and Collaborative Filtering. The most important features are listed as under –
- Taste Collaborative Filtering – Taste is an open source project for collaborative filtering. It is the part of the Mahout framework which provides machine learning algorithms to scale up our applications. Taste is used for personal recommendations. These days when we open a website we find plenty of recommendations related to the website that we are browsing. The following figure shows the architecture diagram of Taste –
Taste Architecture diagram
Figure 1: Taste Architecture diagram
- Map reduce enabled implementations – Several map reduce enabled clustered implementations are supported in Mahout. This includes K-mean, fuzzy, Canopy
- Distributed Navie Bayes and Complimentary Navie Bayes – Apache mahout has the implementation for both Navie Bayes and Complimentary Bayes. For simplicity Navie bayes are referred as Bayes and Complimentary are referred as CBayes. Bayes are used in text classification while the CBayes are extension of Bayes which are used in case of ‘Datasets’.
- It supports Matrix and other related vector libraries.
Setting up Apache Mahout:
Setting up Apache Mahout is very simple and can be carried out in the following steps –
- Step 1 – In order to setup Apache Mahout, we should have the following installed –
- JDK 1.6 or higher
- Ant 1.7 or higher
- Maven 2.9 or higher – In case we want to build from the source code
- Step 2 – Unzip the file, sample.zip and copy the contents in some folder say “apache-mahout-examples”.
- Step 3 – Go inside the folder – “apache-mahout-examples” and run the following –
- ant install
The last step downloads the Wikipedia files and compiles the code.
Recommendation Engine:
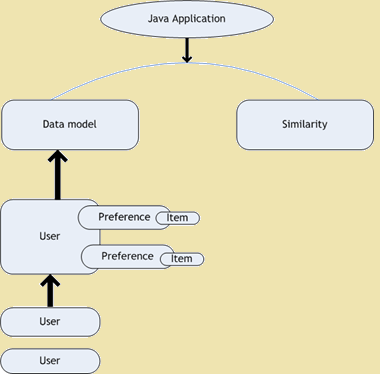
Recommendation engine is a subclass of information filtering system which can predict the rating or preferences user can give to an item. Mahout provides tools and techniques which are helpful to build recommendation engines using the ‘Taste’ library. Using Taste library we can build a fast and flexible Collaborative Filtering engine. Taste consists of the following five primary components which work with users, items and preferences –
- Data Model – This is used as a storage system for users, items and also preferences.
- User Similarity – This is an interface used to define the similarity between two users.
- Item Similarity – An interface which is used to define the similarity between two items.
- Recommender – An interface which is used to provide recommendations.
- User Neighborhood – An interface which is used to compute and calculate a neighborhood of users of same category which can be used by the Recommenders.
Using these components and their implementations, we can build a complex recommendation system. This recommendation engine can be used in both real time recommendations and offline recommendations. Real time recommendations can handle users up to few thousands while the offline recommendations can handle users in much higher count.
Clustering:
Mahout supports many clustering mechanisms. These algorithms are written in map reduce. Each of these algorithms has their own set of goals and criteria. The important ones are listed as under –
- Canopy – This is the most fast clustering algorithm used to create initial seeds for other clustering algorithms.
- k – Means or Fuzzy k – means – This algorithm creates k clusters based on the distance of the items from the centre of the previous iteration.
- Mean – Shift – This algorithm doesn’t require any prior information about the number of clusters. This can produce an arbitrary cluster which can be increased or decreased as per our need.
- Dirichlet – This algorithm creates clusters by combining one or more cluster models. Thus we get an advantage to select the best possible one from a number of clusters.
Out of the above four algorithms listed, the most commonly used is the k – means algorithm. Be it any clustering algorithm, we must follow these steps –
- Prepare the input. If required, convert the text into numeric representation.
- Execute the algorithm of your choice by using any of the Hadoop ready programs available in Mahout.
- Properly evaluate the results.
- Iterate these steps if required.
Content Categorizing:
Apache Mahout supports the following two approaches to categorize or classify the contents. These are mainly based on Bayesian statistics –
- The first approach is straight forward Map reduce enabled Navie bayes classifier. Classifiers of this category are known to be fast and accurate despite having the assumption that the data is completely independent. These classifiers break down when the size of the data goes up or data becomes interdependent. Navie bayes classifier is a two-part process which keeps a track of the features or simply words which associated with a document. This step is known as training which also creates a model by looking at examples of already classified content. The second step, known as classification, uses the model which is created during the training and the content of a new, unseen document. Hence, in order to run Mahout’s classifier, we first need to train the model and then use the model to classify new content.
- The second approach, which is also known as Complementary Naive Bayes, tries to rectify some of the issues with the Naive Bayes approach and still maintains the simplicity and speed offered by Navie Bayes.
Running the Navie Bayes Classifier:
The Navie Bayes Classifier requires executing the following ant targets in order to execute –
- ant prepare-docs – This prepares the set of documents which are required for training.
- ant prepare-test-docs – This prepares the set of documents which are required for testing.
- ant train – Once the training and tests data are set, we need to run the TrainClassifier class using the target – “ant train”.
- ant test – Once the above targets are executed successfully, we need to run this target that takes the sample input documents and tries to classify them based on the model that was created while training.
Summary: In this article we have seen that Apache Mahout is widely used for text classification by using machine learning algorithms. The technology is still growing and can be used for different types of application development. Let us summarize our discussion in the form of following bullets –
- Apache Mahout is an open source project from Apache introduced by a group of developers from the Apache Lucene project. Primary Goal of this project is to create algorithm which can read machine language.
- Apache Mahout has the following important features –
- Taste Collaborative Filtering.
- MapReduce enabled implementations.
- Implementation for both Distributed Navie Bayes and Complimentary Navie Bayes.
- Supports matrix and other related vector based libraries.