概觀: 周圍這麼多的開發框架, 我們應該能夠在任何給定時間點,以擴大我們的應用程序就變得很重要. 學習機一樣的聚類和分類技術,在這方面已經成為流行. 阿帕奇Mahout的是一個框架,幫助我們實現可擴展性.
In this document, 我將談論的Apache Mahout中和它的重要性.
介紹: 阿帕奇Mahout的是Apache軟件基金會或ASF的一個開源項目有創造機器學習算法的主要目標. 由來自Apache Lucene項目開發組的介紹, 阿帕奇Mahout的有,目的是 -
- 建立和支持用戶或貢獻者社區,使訪問源代碼的框架並不局限於一小部分開發商.
- 著眼於實際問題, 而不是看不見或未經證實的問題.
- 提供適當的文件.
阿帕奇亨利馬烏的特點:
阿帕奇亨利馬烏自帶的特性和功能的陣列特別是當我們談論集群和協同過濾. 最重要的特性被列為下 -
- 品嚐協同過濾 - 味道 是協同過濾的一個開源項目. 這是Mahout的框架,它提供了機器學習算法,以擴大我們的應用程序的一部分. 味道是用於個人的建議. 當我們打開一個網站,這些天來,我們發現大量的相關網站的建議,我們正在瀏覽. 下圖顯示了味的架構圖 -
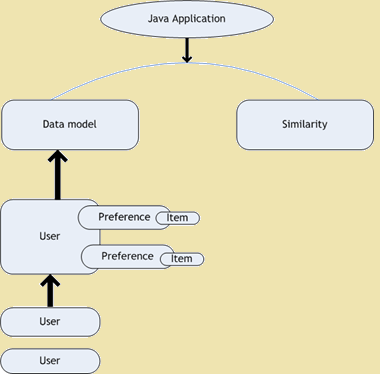
品嚐架構圖
Figure 1: 品嚐架構圖
- 地圖啟用降低實現 - 幾個地圖啟用減少聚集實現,在支持亨利馬烏. 這包括 K均值, 模糊, 華蓋
- 分佈式貝葉斯Navie和免費Navie貝葉斯 - 阿帕奇象夫有兩個Navie貝葉斯和貝葉斯免費實施. 為簡單起見Navie貝葉斯作為貝葉斯和免費簡稱被稱為CBayes. 貝葉斯在文本分類使用,而CBayes是貝葉斯的擴展,它在“數據集”的情況下使用.
- 它支持矩陣等相關載體庫.
設置Apache Mahout的:
設置Apache亨利馬烏是非常簡單,並且可以在下面的步驟來進行 -
- Step 1 - 為了配置Apache Mahout中, 我們應該有以下安裝 -
- JDK 1.6 or higher
- 螞蟻 1.7 or higher
- Maven的 2.9 或更高 - 如果我們想從源代碼來構建
- Step 2 - 解壓縮文件, sample.zip和複製的內容在某些文件夾中說:“Apache的象夫 - 示例”.
- Step 3 - 進入裡面的文件夾 - “Apache的象夫-例子”,並運行下面的 -
- 螞蟻安裝
最後一步下載維基百科的文件和編譯代碼.
推薦引擎:
推薦引擎是信息過濾系統的一個子類,可以預測評級或偏好的用戶可以給一個項目. 亨利馬烏提供工具的,哪些是有利於建立一個使用'味道'庫推薦引擎技術. 使用味道庫,我們可以建立一個快速,靈活的協同過濾引擎. 味道是由它與用戶攜手以下五個主要組件, 項目和喜好 -
- 數據模型 - 這被用作用戶的存儲系統, 項目還喜好.
- 用戶相似性 - 這是用來定義兩個用戶之間的相似性的接口.
- 項目相似 - 這是用來定義兩個項目之間的相似性的接口.
- 推薦人 - 這是用來提供建議的接口.
- 用戶鄰居 - 這是用來計算和計算可以由條引薦使用相同類別的用戶的鄰域的接口.
使用這些組件和它們的實現, 我們可以建立一個複雜的推薦系統. 這個推薦引擎可以同時實時的建議和離線建議使用. 實時建議可處理用戶達幾千,而離線建議可以在更高的計數處理用戶.
集群:
Mahout的支持許多集群機制. 這些算法都寫在地圖降低. 每一種算法都有自己的目標和標準. 其中重要的被列為下 -
- 冠層 - 這是用於創建其他聚類算法初始種子最快速聚類算法.
- ķ – 手段或模糊ķ – 意味著 - 這個算法將基於物品從先前迭代的中心的距離k個簇.
- 意思是 - 轉變 - 這個算法不需要關於簇的數目的任何先驗信息. 這可能會產生可被增加或減少按照我們需要的任意簇.
- 狄氏 - 這個算法通過組合一個或多個群集模型創建集群. 因此,我們得到一個優勢,選擇從多個簇的可能的最佳1.
出了上述四種算法上市, 最常用的是第k - means算法. 無論是任何聚類算法, 我們必須按照下列步驟 -
- 準備輸入. If required, 轉換成文本數字表示.
- 通過使用任何Hadoop的準備方案在Mahout中可用的執行你所選擇的算法.
- 正確評估結果.
- 如果需要的話重複這些步驟.
內容分類:
阿帕奇亨利馬烏支持以下兩種方法進行分類或分類內容. 這主要是基於貝葉斯統計 -
- 第一種方法是直截了當的Map Reduce啟用Navie貝葉斯分類器. 這一類的分類器被稱為是快速和準確的,儘管有該數據是完全獨立的假設. 這些分類分解時的數據的大小上升或數據成為相互依存的. Navie貝葉斯分類器是一個兩部分的方法,該方法保持的,其與文檔相關聯的特徵或僅僅字的軌道. 此步驟被稱為訓練也通過觀察已分類的內容的示例創建模型. 第二步驟, 即分類, 使用該培訓期間創建的模型和新的內容, 看不見的文件. 於是, 為了運行亨利馬烏的分類, 我們首先需要訓練模型,然後使用該模型對新內容進行分類.
- 第二種方法, 其也被稱為互補樸素貝葉斯, 試圖糾正一些與樸素貝葉斯方法的問題,並仍然保持由Navie貝葉斯提供的簡單和速度.
運行Navie貝葉斯分類:
該Navie貝葉斯分類要求,以執行執行以下Ant目標 -
- 螞蟻準備,文檔 - 這個準備所需要的培訓組文件.
- 螞蟻準備測試,文檔 - 此準備所需要測試的一組文件.
- 螞蟻列車 - 一旦訓練和測試數據設置, 我們需要用目標來運行TrainClassifier類 - “蟻列車”.
- 螞蟻測試 - 一旦上述目標被成功執行, 我們需要運行這個目標,是以樣本輸入文件,並嘗試基於在訓練時建立的模型對它們進行分類.
Summary: 在這篇文章中,我們已經看到,阿帕奇亨利馬烏被廣泛用於文本分類利用機器學習算法. 的技術仍在增長,並且可以用於不同類型的應用程序開發. 讓我們總結一下我們在下面的項目符號的形式討論 -
- 阿帕奇Mahout的是Apache的一個開源項目由一組開發人員從Apache Lucene項目介紹. 該項目的主要目標是創建算法,可以讀取機器語言.
- 阿帕奇亨利馬烏具有以下重要特徵 -
- 品嚐協同過濾.
- MapReduce的啟用實現.
- 實施為分佈式貝葉斯Navie和免費Navie貝葉斯.
- 支持矩陣等相關載體基礎庫.