Visión global: Con tantos cadros de desenvolvemento arredor, tórnase importante que debe ser capaz de intensificar a nosa candidatura en calquera punto do tempo. Máquina de técnicas como a agrupación e categorización de aprendizaxe tornáronse populares neste contexto. Apache mahout é unha estrutura que nos axuda a acadar escalabilidade.
In this document, Vou falar Apache mahout ea súa importancia.
Introdución: Apache mahout é un proxecto de código aberto da Apache Software Foundation, ou ASF, que ten o obxectivo principal de crear algoritmo de aprendizaxe de máquina. Introducida por un grupo de desenvolvedores do proxecto Apache Lucene, Apache mahout ten como obxectivo -
- Construír e apoiar unha comunidade de usuarios ou contribuíntes que o acceso ao código fonte para o cadro non se limita a un pequeno grupo de programadores.
- Foco sobre os problemas prácticos, ao contrario de cuestións invisibles ou non comprobadas.
- Presentar documentación axeitada.
Características do Apache mahout:
Apache mahout ven con unha variedade de recursos e funcións especialmente cando falamos de clustering e filtrado colaborativo. As características máis importantes son listados como a continuación -
- Gústame filtrado colaborativo - gusto é un proxecto de código aberto para filtrado colaborativo. É a parte do cadro mahout que ofrece algoritmos de aprendizaxe de máquina para intensificar a nosa aplicacións. Taste é usado para recomendacións persoais. Estes días cando abrir unha páxina web, atopamos unha abundancia de recomendacións relacionadas co sitio web que estamos a ver. A figura seguinte mostra o diagrama de arquitectura do Gústame -
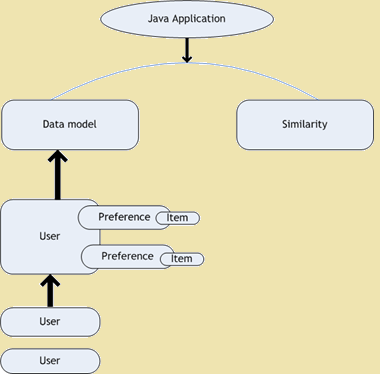
Probe Arquitectura diagrama
Figure 1: Probe Arquitectura diagrama
- Mapa reducir implementacións habilitadas - Varios Map Reduce implementacións en cluster activado dispoñible no mahout. Isto inclúe K-medio, felpudo, dossel
- Distribuído Navie Bayes e cortesía Navie Bayes - Apache mahout ten a implantación tanto para Navie Bayes e cortesía Bayes. Para simplificar Bayes Navie son referidos como Bayes e cortesía son referidos como CBayes. Bayes son utilizados na clasificación de texto mentres os CBayes son extensión de Bayes, que son utilizados en caso de "conxuntos de datos '.
- Soporta Matrix e outras bibliotecas vector relacionados.
Configurar Apache mahout:
Configurar Apache mahout é moi sinxelo e se pode realizar nas seguintes etapas -
- Step 1 - Co fin de configurar Apache mahout, debemos ter o seguinte instalado -
- JDK 1.6 or higher
- formiga 1.7 or higher
- Maven 2.9 ou superior - No caso, queremos construír a partir do código fonte
- Step 2 - Descompactá o arquivo, sample.zip e copiar o contido dalgún cartafol dicir "apache-mahout-exemplos".
- Step 3 - Vaia dentro do cartafol - "apache-mahout-exemplos" e execute o seguinte -
- Ant install
O último paso baixo os ficheiros de Wikipedia e compila o código.
Recommendation Engine:
mecanismo de recomendación é unha subclase de sistemas de filtrado de información que pode prever o rating ou preferencias de usuario pode dar a un elemento. Mahout ofrece ferramentas e técnicas que son útiles para construír mecanismos de recomendación usando a biblioteca 'Taste. Usando biblioteca Gústame podemos construír un mecanismo de filtrado rápido e flexible Collaborative. Taste consiste nos seguintes cinco compoñentes principais que traballan con usuarios, elementos e preferencias -
- Modelo de Datos - Esta é usada como un sistema de almacenamento para os usuarios, elementos e tamén as preferencias.
- Similaridade usuario - Esta é unha interface usada para definir a semellanza entre dous usuarios.
- Elemento de similaridade - Unha interface que se usa para definir a semellanza entre dous elementos.
- recommender - Unha interface que se usa para fornecer recomendacións.
- Barrio do usuario - Unha interface que se usa para calcular e calcular un barrio de usuarios de mesma categoría, que poden ser utilizados polo Recommenders.
Usando estes compoñentes e as súas implementacións, podemos construír un sistema de recomendación complexo. Este mecanismo de recomendación pódese usar en ambas as recomendacións en tempo real e recomendacións offline. recomendacións en tempo real pode xestionar usuarios de ata algúns miles, mentres que as recomendacións offline pode xestionar usuarios conta moito maior.
clustering:
Mahout soporta moitos mecanismos de agrupamento. Estes algoritmos son escritos en mapa reducir. Cada un destes algoritmos ten o seu propio conxunto de obxectivos e criterios. Os máis importantes son listados como a continuación -
- Canopy - Este é o algoritmo máis rápido agrupación usado para crear sementes iniciais para outros algoritmos de agrupación.
- k – Medios ou fuzzy k – significa - Este algoritmo crea k grupos con base na distancia dos elementos desde o centro da iteración anterior.
- Quere dicir - Quenda - Este algoritmo non require ningunha información previa sobre o número de clusters. Isto pode producir un conxunto arbitrario que pode ser aumentado ou diminuída segundo a nosa necesidade.
- Dirichlet - Este algoritmo crea aglomerados través da combinación de un ou máis modelos de fragmentación. Así, temos unha vantaxe para seleccionar o mellor posible a partir dun número de clusters.
Dos anteriores de catro algoritmos lista, o máis comunmente utilizado é o K - means. Sexa calquera algoritmo de agrupación, debemos seguir estes pasos -
- Preparar a entrada. If required, converter o texto en representación numérica.
- Executar o algoritmo da súa elección, mediante calquera dos programas preparados Hadoop dispoñible en mahout.
- Correctamente avaliar os resultados.
- Iterado estes pasos, se é necesario.
clasificando contido:
Apache mahout soporta as dúas seguintes enfoques para categorizar ou clasificar o contido. Estes están baseados principalmente na estatística Bayesiana -
- A primeira visión é o mapa para adiante reducen habilitado Navie Bayes clasificador. Clasificadores desta categoría son coñecidos por ser rápido e preciso, a pesar de ter a suposición de que os datos son completamente independentes. Estes clasificadores romper cando o tamaño dos datos vai arriba de datos se fai interdependentes. Navie Bayes clasificador é un proceso en dúas partes, que mantén unha franxa de recursos ou simplemente palabras que asociadas a un documento. Esta etapa é coñecida como formación, que tamén crea un modelo buscando exemplos de contidos xa clasificados. O segundo paso, coñecido como clasificación, usa o modelo que é creado durante a formación e os contidos dunha nova, documento invisible. aquí, a fin de realizar clasificador do mahout, necesitamos primeiro adestrar o modelo e, a continuación, usar o modelo para clasificar contido.
- A segunda visión, que tamén é coñecido como Complementaria Naive Bayes, intenta corrixir algúns dos problemas coa visión de Naive Bayes e aínda mantén a sinxeleza e velocidade ofrecida por Navie Bayes.
Executando Navie Bayes clasificador:
O Navie Bayes clasificador require a execución das seguintes obxectivos de formiga, a fin de realizar -
- Ant prepare-docs - Iso prepara o conxunto de documentos que son necesarios para a formación.
- Ant prepare-test-docs - Iso prepara o conxunto de documentos que son necesarios para a proba.
- tren formiga - Unha vez que os datos de adestramento e probas constan, necesitamos realizar a clase TrainClassifier usando o obxectivo - "tren ant".
- Ant test - Unha vez que os obxectivos arriba sexan executados satisfactoriamente, necesitamos realizar esta meta que leva os documentos de entrada da mostra e tenta clasificalos los con base no modelo que se creou durante o adestramento.
Summary: Neste artigo, vimos que Apache mahout é amplamente utilizado para a clasificación de texto mediante algoritmos de aprendizaxe de máquina. A tecnoloxía aínda está a aumentar e pode ser usado para diferentes tipos de desenvolvemento de aplicación. Imos resumir nosa discusión en forma de seguir balas -
- Apache mahout é un proxecto de código aberto de Apache introducida por un grupo de desenvolvedores do proxecto Apache Lucene. Obxectivo principal deste proxecto é crear algoritmo que pode ler linguaxe de máquina.
- Apache mahout ten as seguintes características importantes -
- Gústame filtrado colaborativo.
- MapReduce habilitado implementacións.
- Implantación tanto para Distributed Navie Bayes e cortesía Navie Bayes.
- Soporta matriz e outras bibliotecas en base relacionada vector.