Oversigt: Med så mange udviklingsprojekter rammer omkring, bliver det vigtigt, at vi bør være i stand til at skalere op vores ansøgning på ethvert givet tidspunkt. Machine learning teknikker som clustering og kategorisering er blevet populære i denne sammenhæng. Apache Mahout er en ramme, som hjælper os med at opnå skalerbarhed.
In this document, Jeg vil tale om Apache Mahout og dens betydning.
Indledning: Apache Mahout er et open source-projekt fra Apache Software Foundation eller ASF, som har det primære mål at skabe machine learning algoritme. Indført af en gruppe af udviklere fra Apache Lucene projektet, Apache Mahout har til formål at -
- Byg og støtte et fællesskab af brugere eller bidragydere, således at adgangen til kildekoden for rammerne er ikke begrænset til en lille gruppe af udviklere.
- Fokus på de praktiske problemer, snarere end usete eller udokumenterede spørgsmål.
- Sørg for passende dokumentation.
Funktioner af Apache Mahout:
Apache Mahout kommer med en række funktioner og funktionaliteter, især når vi taler om Clustering og Collaborative Filtering. De vigtigste funktioner er anført som under -
- Smag Collaborative Filtering - Smag er et open source-projekt til kollaborativ filtrering. Det er den del af Mahout ramme, som giver machine learning algoritmer til at skalere op vores applikationer. Smag bruges til personlige anbefalinger. Disse dage, hvor vi åbner en hjemmeside, vi finde masser af anbefalinger relateret til hjemmesiden, som vi læser. Nedenstående figur viser arkitektur diagram of Taste -
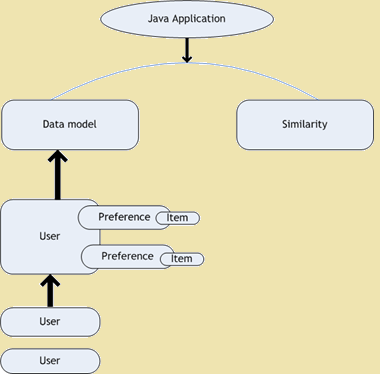
Smag Arkitektur diagram
Figure 1: Smag Arkitektur diagram
- Kort reducere aktiverede implementeringer - Adskillige kort reducere aktiverede klynger implementeringer er understøttet i Mahout. Dette omfatter K-middelværdi, fuzzy, Baldakin
- Distribueret Navie Bayes og gratis Navie Bayes - Apache mahout har gennemførelsen for både Navie Bayes og gratis Bayes. For enkelhed Navie Bayes omtales som Bayes og gratis betegnes som CBayes. Bayes anvendes i teksten klassifikation mens CBayes er forlængelse af Bayes som anvendes i tilfælde af 'Datasets'.
- Det understøtter Matrix og andre relaterede vektor biblioteker.
Opsætning af Apache Mahout:
Opsætning Apache Mahout er meget enkel og kan udføres i de følgende trin -
- Step 1 - For at sætte Apache Mahout, vi bør have følgende installeret -
- JDK 1.6 or higher
- Myre 1.7 or higher
- Maven 2.9 eller højere - Hvis vi ønsker at bygge fra kildekoden
- Step 2 - Pak filen, sample.zip og kopiere indholdet i nogle mappe sige "apache-mahout-eksempler".
- Step 3 - Gå ind i mappen - "apache-mahout-eksempler", og køre følgende -
- ant installere
Det sidste trin henter de Wikipedia-filer og kompilerer koden.
Anbefaling Engine:
Anbefaling motor er en underklasse af information filtrering system, der kan forudsige rating eller præferencer brugeren kan give til et element. Mahout indeholder værktøjer og teknikker, som er nyttige til at bygge anbefaling motorer ved hjælp af "Smag" bibliotek. Brug Smag bibliotek vi kan bygge en hurtig og fleksibel Collaborative Filtering motor. Smag består af følgende fem primære komponenter, der arbejder med brugere, elementer og præferencer -
- Data Model - Dette bruges som et opbevaringssystem til brugerne, elementer og også præferencer.
- Bruger lighed - Dette er en grænseflade anvendes til at definere ligheden mellem to brugere.
- Item lighed - En grænseflade, der bruges til at definere ligheden mellem to varer.
- recommender - En grænseflade, som bruges til at give anbefalinger.
- Bruger Neighborhood - En grænseflade, der anvendes til at beregne og beregne et kvarter af brugere af samme kategori, der kan anvendes ved anbefalernes.
Ved hjælp af disse komponenter og deres implementeringer, vi kan bygge et komplekst anbefaling-system. Denne anbefaling motor kan bruges i både realtid anbefalinger og offline anbefalinger. Rigtige tid anbefalinger kan håndtere brugere op til nogle få tusinde, mens offline anbefalingerne kan håndtere brugere i langt højere antal.
clustering:
Mahout understøtter mange klyngedannelse mekanismer. Disse algoritmer er skrevet på kortet reducere. Hver af disse algoritmer har deres eget sæt af mål og kriterier. De vigtigste er anført som under -
- Canopy - Dette er den mest hurtigt clustering algoritme, der anvendes til at skabe indledende frø til andre klyngedannelse algoritmer.
- k – Midler eller Fuzzy k – betyder - Denne algoritme skaber k klynger baseret på afstanden af emnerne fra centrum af den foregående iteration.
- Mean - Shift - Denne algoritme kræver ikke nogen forudgående oplysninger om antallet af klynger. Dette kan give en vilkårlig klynge, der kan øges eller mindskes som pr vores behov.
- Dirichlet - Denne algoritme skaber klynger ved at kombinere en eller flere klynge modeller. Således får vi en fordel at vælge den bedst mulige en fra en række klynger.
Ud af de ovennævnte fire algoritmer opført, de mest almindeligt anvendte er den k - betyder algoritme. Det være sig enhver clustering algoritme, Vi skal følge disse trin -
- Forbered input. If required, konvertere teksten til numerisk repræsentation.
- Udfør algoritmen efter eget valg ved at bruge nogen af de Hadoop klar programmer tilgængelige i Mahout.
- Korrekt evaluere resultaterne.
- Gentage disse trin, hvis det kræves.
Content Kategorisering:
Apache Mahout understøtter følgende to metoder til at kategorisere eller klassificere indholdet. Disse er hovedsageligt baseret på Bayesianske statistik -
- Den første strategi er ligetil Kort reducere aktiveret Navie Bayes klassificeringen. Klassifikatorer af denne kategori er kendt for at være hurtig og præcis trods den antagelse, at data er fuldstændig uafhængig. Disse klassificører nedbryde, når størrelsen af de data går op eller data bliver indbyrdes afhængige. Navie Bayes klassificeringen er en todelt proces, der holder styr på de funktioner eller blot ord, som er forbundet med et dokument. Dette trin er kendt som uddannelse, som også skaber en model ved at se på eksempler på allerede klassificeret indhold. Det andet skridt, kendt som klassifikation, bruger den model, som er skabt i løbet af uddannelsen, og indholdet af en ny, uset dokument. Derfor, for at køre Mahout s klassificeringen, vi først nødt til at træne modellen og derefter bruge modellen til at klassificere nyt indhold.
- Den anden fremgangsmåde, som også er kendt som komplementære Naive Bayes, forsøger at rette op på nogle af de problemer med Naiv Bayes tilgang og stadig fastholder den enkelhed og hastighed, der tilbydes af Navie Bayes.
Kørsel af Navie Bayes Classifier:
Den Navie Bayes Classifier kræver udføre følgende ant mål for at udføre -
- ant forberede-docs - Dette forbereder det af det dokument, som er nødvendige for træning.
- ant forberede-test-docs - Dette forbereder det af det dokument, som er nødvendige til afprøvning.
- ant tog - Når uddannelse og tests data er indstillet, vi nødt til at køre TrainClassifier klasse ved hjælp af målet - "ant tog".
- ant test - Når de ovennævnte mål udføres med succes, vi nødt til at køre dette mål, der tager prøven input dokumenter og forsøger at klassificere dem baseret på den model, der blev oprettet under træning.
Summary: I denne artikel har vi set, at Apache Mahout almindeligt bruges til tekst klassificering ved hjælp af machine learning algoritmer. Teknologien vokser stadig og kan bruges til forskellige typer af programudvikling. Lad os opsummere vores diskussion i form af følgende kugler -
- Apache Mahout er et open source-projekt fra Apache indført af en gruppe af udviklere fra Apache Lucene projektet. Primære mål med dette projekt er at skabe algoritme, der kan læse maskine sprog.
- Apache Mahout har følgende vigtige funktioner -
- Smag Collaborative Filtering.
- MapReduce aktiveret implementeringer.
- Implementering både Distributed Navie Bayes og gratis Navie Bayes.
- Understøtter matrix og andre relaterede vektor baserede biblioteker.