Агляд: З такім вялікай колькасцю рамак развіцця вакол, гэта становіцца важным, што мы павінны мець магчымасць пашыраць наша прыкладанне ў любы дадзены момант часу. Машына метады, як кластарызацыя і катэгарызацыі навучання сталі папулярнымі ў гэтым кантэксце. Apache Mahout з'яўляецца асновай, якая дапамагае нам дасягнуць маштабаванасці.
In this document, Я буду казаць пра Apache Mahout і яго значэнне.
Увядзенне: Apache Mahout з'яўляецца праектам з адкрытым кодам ад Apache Software Foundation або ASF, які нясе асноўную мэту стварэння алгарытму машыннага навучання. Прадстаўлены групай распрацоўшчыкаў з праекта Apache Lucene, Apache Mahout мае на мэце -
- Стварэнне і падтрымка грамады карыстальнікаў або ўдзельнікаў такім чынам, каб доступ да зыходнага кода для рамак не абмяжоўваецца невялікай групай распрацоўшчыкаў.
- Фокус на практычныя праблемы, а не нябачных або недаказаных пытанняў.
- Забяспечыць адпаведную дакументацыю.
Асаблівасці Apache Mahout:
Apache Mahout пастаўляецца з наборам функцый і функцыянальных магчымасцяў, асабліва калі мы гаворым пра кластарызацыя і коллаборативной фільтрацыі. Найбольш важныя функцыі пералічаныя як пад -
- Густ коллаборативной фільтрацыі - густ з'яўляецца праектам з адкрытым кодам для сумеснай фільтрацыі. Гэта частка каркаса Mahout якая забяспечвае алгарытмы машыннага навучання, накіраваных на пашырэнне нашых праграмаў. Густ выкарыстоўваецца для асабістых рэкамендацый. У гэтыя дні, калі мы адкрываем сайт, мы знаходзім мноства рэкамендацый, звязаных з вэб-сайта, якія мы праглядаюць. На прыведзеным ніжэй малюнку паказана схема архітэктуры густу -
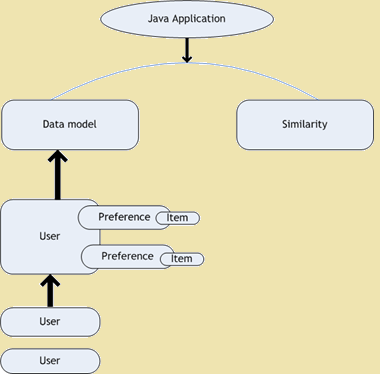
Густ Дыяграма архітэктуры
Figure 1: Густ Дыяграма архітэктуры
- Карта скарачэння уключаных рэалізацый - Некалькі карта з падтрымкай кластарныя памяншаюць рэалізацыі падтрымліваюцца ў Mahout. Гэта ўключае ў сябе K-сярэдняе, невыразны, балдахін
- Размеркаваная Байеса і Навье Бясплатны Байеса Навье - Apache махаут мае рэалізацыю для абодвух Байеса і Навье Бясплатны Байеса. Для прастаты Байеса Навье называюцца таксама Байеса і бясплатныя называюцца таксама CBayes. Байеса выкарыстоўваюцца ў тэкставай класіфікацыі у той час як CBayes з'яўляюцца працягам Байеса, якія выкарыстоўваюцца ў выпадку "Datasets".
- Ён падтрымлівае Matrix і іншыя звязаныя з вектарнай бібліятэкі.
Налада Apache Mahout:
Налада Apache Mahout вельмі просты і можа ажыццяўляцца ў наступных кроках -
- Step 1 - Для таго, каб налады Apache Mahout, мы павінны мець устаноўлены наступныя кампаненты -
- JDK 1.6 or higher
- мурашка 1.7 or higher
- спецыяліст 2.9 або вышэй - У выпадку, калі мы хочам пабудаваць з зыходнага кода
- Step 2 - Распакуйце файл, sample.zip і скапіяваць змесціва ў якую-небудзь тэчку сказаць: "Апач-Mahout-прыклады".
- Step 3 - Ідзіце ў тэчку - "Апач-Mahout-прыклады" і запусціце наступную каманду -
- мурашка ўсталяваць
Апошні крок загружае файлы з Вікіпедыі і кампілюе код.
рэкамендацыя Рухавік:
Рэкамендацыя рухавіка з'яўляецца падклас інфармацыйнай сістэмы фільтрацыі, якая можа прадказаць, рэйтынг або перавагi карыстальніка могуць даць элементу. Mahout дае прылады і метады, якія з'яўляюцца карыснымі для стварэння рэкамендацыйных рухавікоў з выкарыстаннем "смак" бібліятэку. Выкарыстоўваючы бібліятэку густу мы можам пабудаваць хуткі і гнуткі механізм Collaborative Filtering. Густ складаецца з наступных пяці асноўных кампанентаў, якія працуюць з карыстальнікамі, прадметы і перавагі -
- Мадэль дадзеных - Гэта выкарыстоўваецца ў якасці сістэмы захоўвання для карыстальнікаў, элементы, а таксама перавагі.
- Падабенства карыстальніка - Гэта інтэрфейс, які выкарыстоўваецца для вызначэння падабенства паміж двума карыстальнікамі.
- Пункт Падабенства - Інтэрфейс, які выкарыстоўваецца для вызначэння падабенства паміж двума элементамі.
- Recommender - Інтэрфейс, які выкарыстоўваецца для выпрацоўкі рэкамендацый.
- Раён карыстальніка - Інтэрфейс, які выкарыстоўваецца для вылічэнні і вылічыць навакольле карыстальнікаў той жа катэгорыі, якія могуць быць выкарыстаны рекомендателей.
З дапамогай гэтых кампанентаў і іх рэалізацыі, мы можам пабудаваць складаную сістэму рэкамендацый. Гэтая рэкамендацыя рухавік можа быць выкарыстаны як у рэальным часе рэкамендацый і ў аўтаномным рэжыме рэкамендацый. Сапраўдныя рэкамендацыі часе могуць апрацоўваць карыстальнікаў да некалькіх тысяч у той час як аўтаномныя рэкамендацыі могуць звяртацца карыстальнікі ў значна большай кол.
кластарызацыя:
Mahout падтрымлівае мноства механізмаў кластарызацыі. Гэтыя алгарытмы напісаны на карце паменшыць. Кожны з гэтых алгарытмаў мае свой уласны набор мэтаў і крытэрыяў. Гэтыя важныя з іх пералічаныя як пад -
- навес - Гэта самы хуткі алгарытм кластарызацыі выкарыстоўваецца для стварэння пачатковых насення для іншых алгарытмаў кластарызацыі.
- Да – Значыць або Fuzzy да – азначае - Гэты алгарытм стварае K кластараў, заснаваныя на адлегласці пунктаў ад цэнтра папярэдняй ітэрацыі.
- Сярэдняе значэнне - Shift - Гэты алгарытм не патрабуе якіх-небудзь папярэдняй інфармацыі аб колькасці кластараў. Гэта можа прывесці да адвольны кластар, які можа быць павялічаны або паменшаны ў адпаведнасці з нашай патрэбы.
- Дирихле - Гэты алгарытм стварае кластары шляхам аб'яднання аднаго або некалькіх кластарных мадэляў. Такім чынам, мы атрымліваем перавага, каб выбраць найлепшы адзін з некалькіх кластараў.
З прыведзеных вышэй чатырох алгарытмаў пералічаных, найбольш часта выкарыстоўваным з'яўляецца K - азначае алгарытм. Будзь гэта любы алгарытм кластарызацыі, мы павінны прытрымлівацца наступныя крокі -
- падрыхтуйце ўваход. If required, пераўтварыць тэкст у лікавае паданне.
- Выканаць алгарытм па вашаму выбару, выкарыстоўваючы любы з гатовых праграм Hadoop даступныя ў Mahout.
- Правільна ацаніць вынікі.
- Перабор гэтыя крокі, калі патрабуецца.
змест катэгарызацыі:
Apache Mahout падтрымлівае наступныя два падыходу да класіфікацыі або класіфікаваць змесціва. Яны галоўным чынам заснаваныя на байесовской статыстыкі -
- Першы падыход прама наперад Map зніжаюць уключаны класіфікатар Байеса Навье. Класіфікатары гэтай катэгорыі, як вядома, хутка і дакладна, нягледзячы на здагадка аб тым, што дадзеныя цалкам незалежныя. Гэтыя класіфікатары ламаюцца, калі памер дадзеных ідзе ўверх або дадзеныя становяцца ўзаемазалежнымі. Байесовский класіфікатар Навье ўяўляе сабой працэс, які складаецца з двух частак, якая трымае след асаблівасцяў або проста словы, якія звязаныя з дакументам. Гэты крок вядомы як навучанне, якое таксама стварае мадэль, гледзячы на прыклады ўжо класіфікаваных ўтрымання. другі крок, вядомы як класіфікацыі, выкарыстоўвае мадэль, якая ствараецца ў працэсе навучання і змест новага, нябачны дакумент. такім чынам, для таго, каб запусціць класіфікатар Mahout ў, мы ў першую чаргу неабходна для навучання мадэлі, а затым выкарыстоўваць гэтую мадэль для класіфікацыі новага кантэнту.
- другі падыход, які таксама вядомы як узаемадапаўняльныя Наіўнае Байеса, спрабуе выправіць некаторыя з пытанняў, з наіўнай байесовской падыход і да гэтага часу захоўвае прастату і хуткасць, прапанаваную Байеса Навье.
Запуск Байеса класіфікатар Навье:
Байеса класіфікатар Навье патрабуе выканання наступных мэтаў Ant для выканання -
- мурашка падрыхтоўкі дактарантаў - Гэта падрыхтоўвае набор дакументаў, якія неабходныя для навучання.
- мурашка падрыхтоўкі выпрабаванняў дакументы - Гэта падрыхтоўвае набор дакументаў, якія неабходныя для тэставання.
- мурашка цягнік - Пасля таго як дадзеныя навучання і тэсты ўстаноўлены, нам трэба запусціць клас TrainClassifier выкарыстоўваючы мэта - "ANT цягнік".
- мурашка тэст - Пасля таго, як названыя вышэй мэты выконваюцца паспяхова, мы павінны выканаць гэтую мэту, якая прымае ўваходныя выбаркі дакументаў і спрабуе класіфікаваць іх на аснове мадэлі, якая была створана падчас трэніроўкі.
Summary: У гэтым артыкуле мы ўбачылі, што Apache Mahout шырока выкарыстоўваецца для класіфікацыі тэксту з выкарыстаннем алгарытмаў машыннага навучання. Тэхналогія ўсё яшчэ расце, і могуць быць выкарыстаны для розных тыпаў распрацоўкі прыкладанняў. Падагульнім наша абмеркаванне ў выглядзе наступных куль -
- Apache Mahout з'яўляецца праектам з адкрытым кодам ад Apache прадстаўлены групай распрацоўшчыкаў з праекта Apache Lucene. Асноўная мэта гэтага праекта заключаецца ў стварэнні алгарытму, які можа чытаць машынны мова.
- Apache Mahout мае наступныя важныя асаблівасці -
- Густ коллаборативной фільтрацыі.
- MapReduce ўключана рэалізацыя.
- Рэалізацыя для абодвух Distributed Байеса і Навье Бясплатны Байеса Навье.
- Падтрымлівае матрыцы і іншыя звязаныя вектар на аснове бібліятэк.