ความต้องการสำหรับการประมวลผลข้อมูลได้เร็วขึ้นได้เพิ่มขึ้นและเวลาจริงการประมวลผลข้อมูลสตรีมมิ่งที่ดูเหมือนจะเป็นคำตอบ. ในขณะที่ Apache Spark ยังคงถูกนำมาใช้ในจำนวนมากขององค์กรสำหรับการประมวลผลข้อมูลขนาดใหญ่, Apache Flink ได้รับมาขึ้นอย่างรวดเร็วเป็นทางเลือก. In fact, หลายคนคิดว่ามันมีศักยภาพที่จะเปลี่ยน Apache Spark เพราะความสามารถในการประมวลผลข้อมูลสตรีมมิ่งเวลาจริง. Of course, คณะลูกขุนว่า Flink สามารถแทนที่ Spark ยังคงออกเพราะ Flink ก็ยังไม่ได้นำไปทดสอบอย่างกว้างขวาง. แต่การประมวลผลแบบ real-time และแฝงข้อมูลต่ำเป็นสองกำหนดลักษณะของมัน. At the same time, นี้จะต้องได้รับการพิจารณาว่า Apache Spark อาจจะไม่ออกจากความโปรดปรานไปเพราะความสามารถในการประมวลผลชุดของมันจะเป็นยังมีความเกี่ยวข้อง.
กรณีสำหรับสตรีมมิ่งการประมวลผลข้อมูล
สำหรับประโยชน์ทั้งหมดของการประมวลผลชุดตาม, มีปรากฏเป็นกรณีที่แข็งแกร่งสำหรับเวลาจริงการประมวลผลข้อมูลสตรีมมิ่ง. สตรีมมิ่งการประมวลผลข้อมูลที่ทำให้มันเป็นไปได้ในการตั้งค่าและโหลดคลังข้อมูลได้อย่างรวดเร็ว. หน่วยประมวลผลสตรีมมิ่งที่มีข้อมูลแฝงต่ำให้ข้อมูลเชิงลึกเพิ่มเติมเกี่ยวกับข้อมูลได้อย่างรวดเร็ว. So, คุณมีเวลามากขึ้นที่จะหาสิ่งที่เกิดขึ้น. นอกเหนือไปจากการประมวลผลได้เร็วขึ้น, นอกจากนี้ยังมีประโยชน์อีกอย่างมีนัยสำคัญ: คุณมีเวลามากขึ้นในการออกแบบตอบสนองที่เหมาะสมกับเหตุการณ์. For example, ในกรณีของการตรวจสอบความผิดปกติ, แฝงต่ำและการตรวจสอบได้เร็วขึ้นช่วยให้คุณสามารถระบุการตอบสนองที่ดีที่สุดซึ่งเป็นกุญแจสำคัญเพื่อป้องกันความเสียหายในกรณีเช่นการโจมตีหลอกลวงบนเว็บไซต์ที่ปลอดภัยหรือความเสียหายอุปกรณ์อุตสาหกรรม. So, คุณสามารถป้องกันการสูญเสียอย่างมาก.
Apache Flink คืออะไร?
Apache Flink เป็นเครื่องมือที่มีการประมวลผลข้อมูลขนาดใหญ่และเป็นที่รู้จักกันในการประมวลผลข้อมูลขนาดใหญ่ได้อย่างรวดเร็วด้วยข้อมูลแฝงต่ำและป้องกันความผิดพลาดสูงในระบบการกระจายในขนาดใหญ่. กำหนดคุณลักษณะของมันคือความสามารถในการประมวลผลข้อมูลสตรีมมิ่งในเวลาจริง.
Apache Flink เริ่มจากเป็นโครงการที่มาเปิดทางวิชาการและการกลับมาแล้ว, มันเป็นที่รู้จัก Stratosphere. Later, มันก็กลายเป็นส่วนหนึ่งของศูนย์บ่มเพาะซอฟต์แวร์อาปาเช่มูลนิธิ. เพื่อหลีกเลี่ยงความขัดแย้งในชื่อกับโครงการอื่น, เปลี่ยนชื่อเป็นเพื่อ Flink. ชื่อ Flink มีความเหมาะสมเพราะมันหมายถึงเปรียว. แม้โลโก้ได้รับการแต่งตั้ง, กระรอกมีความเหมาะสมเพราะกระรอกแสดงให้เห็นถึงคุณค่าของความคล่องตัว, ฉลาดและความเร็ว.
เพราะมันถูกบันทึกอยู่ในมูลนิธิซอฟต์แวร์อาปาเช่, มันมีการเพิ่มขึ้นค่อนข้างรวดเร็วเป็นเครื่องมือในการประมวลผลข้อมูลขนาดใหญ่และภายใน 8 เดือน, มันก็เริ่มที่จะดึงดูดความสนใจของผู้ชมที่กว้างขึ้น. ดอกเบี้ยที่เพิ่มขึ้นของผู้คนใน Flink ได้สะท้อนให้เห็นในจำนวนของผู้เข้าร่วมประชุมในจำนวนของการประชุมใน 2015. จำนวนคนที่เข้าร่วมประชุมใน Flink ที่ประชุมชั้นในกรุงลอนดอนในเดือนพฤษภาคม 2015 และการประชุมสุดยอด Hadoop ในซานโฮเซในเดือนมิถุนายน, 2015. มากกว่า 60 คนเข้าร่วมบริเวณอ่าว Apache Flink พบปะเจ้าภาพที่สำนักงานใหญ่ MapR ในซานโฮเซในเดือนสิงหาคม, 2015.
ภาพด้านล่างให้สถาปัตยกรรมของแลมบ์ดา Flink.
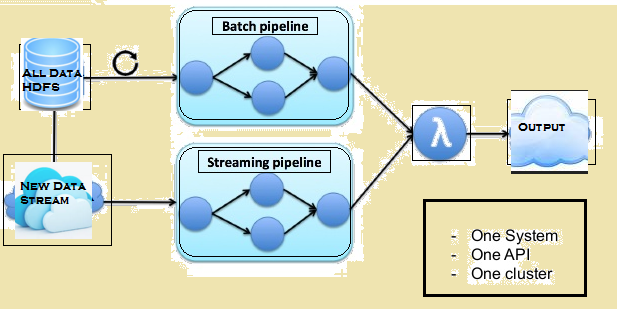
สถาปัตยกรรมของแลมบ์ดา Flink
เปรียบเทียบระหว่าง Spark และ Flink
แต่มีความคล้ายคลึงกันระหว่างไม่กี่จุดประกายและ Flink, เช่น, APIs และส่วนประกอบของพวกเขา, ความคล้ายคลึงกันไม่ได้เรื่องมากเมื่อมันมาถึงการประมวลผลข้อมูล. รับด้านล่างคือการเปรียบเทียบระหว่าง Flink และจุดประกาย.
การประมวลผล
Spark ประมวลผลข้อมูลในโหมดแบทช์ในขณะที่ Flink ประมวลผลข้อมูลสตรีมมิ่งในเวลาจริง. Spark ประมวลผลชิ้นของข้อมูล, ที่รู้จักกันในขณะที่ RDDs Flink สามารถประมวลผลแถวหลังจากแถวของข้อมูลในเวลาจริง. So, ในขณะที่แฝงข้อมูลขั้นต่ำอยู่ที่นั่นเสมอกับ Spark, มันไม่เป็นอย่างนั้น Flink.
ซ้ำ
Spark สนับสนุนการทำซ้ำข้อมูลใน batches แต่กำเนิด Flink สามารถย้ำข้อมูลโดยใช้สถาปัตยกรรมสตรีมมิ่ง. ภาพด้านล่างแสดงให้เห็นว่าการทำซ้ำการประมวลผลที่จะเกิดขึ้น.
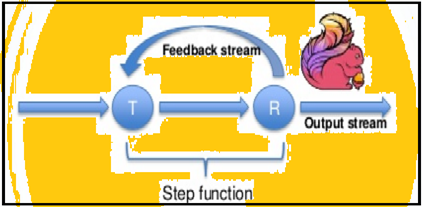
การประมวลผลซ้ำแล้วซ้ำอีก
จัดการหน่วยความจำ
Flink จะสามารถปรับให้เข้ากับชุดข้อมูลที่แตกต่างกัน แต่จุดประกายความต้องการในการเพิ่มประสิทธิภาพและปรับงานของตนเองเพื่อให้ชุดข้อมูลของแต่ละบุคคล. นอกจากนี้ยัง Spark ไม่แบ่งใช้และแคช. So, คาดหวังความล่าช้าบางในการประมวลผล.
การไหลของข้อมูล
Flink สามารถให้ผลกลางในการประมวลผลข้อมูลของตนเมื่อใดก็ตามที่จำเป็นต้องใช้. ในขณะที่จุดประกายตามระบบการเขียนโปรแกรมขั้นตอน, Flink ตามแนวทางการไหลของข้อมูลกระจาย. So, เมื่อใดก็ตามที่ผลกลางจะต้อง, ตัวแปรที่ออกอากาศจะใช้ในการแจกจ่ายผลการคำนวณก่อนผ่านไปยังทุกโหนดของผู้ปฏิบัติงาน.
การแสดงข้อมูล
Flink มีอินเตอร์เฟซเว็บเพื่อส่งและดำเนินงานทั้งหมด. ทั้งจุดประกายและ Flink มีการบูรณาการกับ Apache เหาะและให้ข้อมูลการบริโภค, การวิเคราะห์ข้อมูล, การค้นพบ, การทำงานร่วมกันและการมองเห็น. Apache เหาะยังมีแบ็กเอนด์หลายภาษาที่ช่วยให้คุณสามารถส่งและรันโปรแกรม Flink.
ระยะเวลาดำเนินการ
ย่อหน้าด้านล่างให้เปรียบเทียบระหว่างเวลาที่ถ่ายโดย Flink และจุดประกายในงานที่แตกต่างกัน.
เพื่อให้เปรียบเทียบยุติธรรม, ทั้ง Flink และ Spark ได้รับทรัพยากรเดียวกันในรูปแบบของรายละเอียดเครื่องและการกำหนดค่าโหนด.

การกำหนดค่าโหนด
ดังแสดงในภาพด้านบน, ภาพที่เน้นสีแดงบ่งบอกถึงรายละเอียดเครื่องสำหรับหน่วยประมวลผล Flink ในขณะที่หนึ่งข้างมันแสดงให้เห็นว่าในการประมวลผลจุดประกาย.
ดังแสดงในภาพด้านบน, พื้นที่เน้นด้วยสีแดงบ่งบอกถึงการกำหนดค่าโหนดสำหรับหน่วยประมวลผลและประมวลผล Flink จุดประกาย.
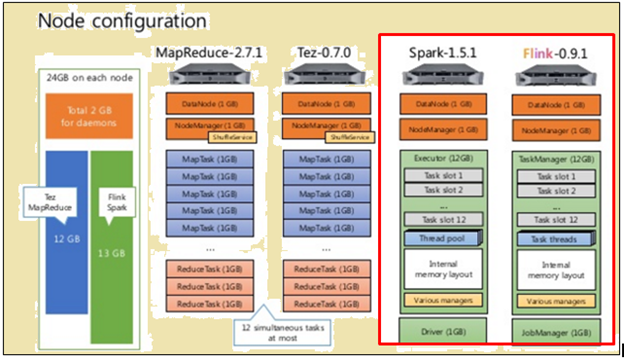
หน่วยประมวลผล Spark
Flink ประมวลผลได้เร็วขึ้นเนื่องจากการดำเนินการของไปป์ไลน์. การประมวลผลข้อมูล, Spark เอา 2171 วินาทีในขณะที่ Flink เอา 1490 วินาที.
เมื่อ Terasort ที่มีขนาดข้อมูลต่างๆได้ดำเนินการ, ต่อไปนี้เป็นผล:
- สำหรับ 10 วัน GB, Flink ยิง 157 วินาทีเมื่อเทียบกับ Spark ของ 387 วินาที.
- สำหรับ 160 วัน GB, Flink ยิง 3127 วินาทีเมื่อเทียบกับ Spark ของ 4927 วินาที.
แบทช์หรือข้อมูลสตรีมมิ่ง - ซึ่งกระบวนการจะดีกว่า?
กระบวนการทั้งสองมีข้อดีและมีความเหมาะสมสำหรับสถานการณ์ที่แตกต่างกัน. แม้หลายคนจะอ้างว่าเครื่องมือชุดตามกำลังจะออกจากของที่ระลึก, มันจะไม่เกิดขึ้นในเร็ว ๆ นี้. เพื่อให้เข้าใจถึงข้อดีของญาติ, ดูการเปรียบเทียบดังต่อไปนี้:
| ที่พริ้ว | เครื่องผสม |
| ข้อมูลหรือปัจจัยการผลิตเข้ามาในรูปแบบของระเบียนในลำดับที่เฉพาะเจาะจง. | ข้อมูลหรือปัจจัยการผลิตจะแบ่งออกเป็นสำหรับกระบวนการขึ้นอยู่กับจำนวนของระเบียนหรือเวลา. |
| การส่งออกจะต้องเร็วที่สุดเท่าที่เป็นไปได้ แต่ไม่เร็วกว่าเวลาที่จำเป็นต้องมีการตรวจสอบลำดับ. | ปัจจัยการผลิตจะได้รับตามความต้องการ แต่จำนวนที่แน่นอนของแบทช์จะถูกเก็บไว้. |
| การส่งออกไม่จำเป็นต้องได้รับการแก้ไขหลังจากที่มันถูกเขียน. | รัฐใหม่และรายละเอียดของทุกแถวของการส่งออกที่มีการบันทึกไว้. |
| ยังสามารถทำชุดการประมวลผลข้อมูล | ไม่สามารถที่จะทำการประมวลผลชุดของข้อมูล |
มีสถานการณ์ของแต่ละบุคคลซึ่งทั้งสอง Flink และการประมวลผลชุดที่มีประโยชน์. ใช้กรณีการใช้งานคอมพิวเตอร์ของยอดขายรายเดือนกลิ้งในช่วงเวลาในชีวิตประจำวัน. ในกิจกรรมนี้, สิ่งที่จำเป็นคือการคำนวณยอดขายรวมในชีวิตประจำวันแล้วทำให้ผลรวมสะสม. ในกรณีที่การใช้งานเช่นนี้, การประมวลผลสตรีมมิ่งของข้อมูลอาจไม่จำเป็นต้อง. ประมวลผลชุดของข้อมูลที่สามารถดูแลของแต่ละชุดของตัวเลขยอดขายตามวันและเพิ่มพวกเขา. ในกรณีนี้, แม้ว่าจะมีบางอย่างแฝงข้อมูล, ซึ่งจะสามารถสร้างขึ้นในภายหลังเมื่อได้ว่าข้อมูลที่ซ่อนเร้นจะถูกเพิ่มสำหรับกระบวนการในภายหลัง.
นอกจากนี้ในทำนองเดียวกันกรณีการใช้งานที่ต้องการการประมวลผลสตรีมมิ่ง. ใช้กรณีที่ใช้ในการคำนวณเวลารายเดือนกลิ้งผู้เข้าชมแต่ละใช้เวลาบนเว็บไซต์. ในกรณีของเว็บไซต์, จำนวนการเข้าชมอาจมีการปรับปรุง, ทุกๆชั่วโมง, นาทีที่ชาญฉลาดหรือแม้กระทั่งในชีวิตประจำวัน. แต่ปัญหาในกรณีนี้คือการกำหนดเซสชั่น. มันอาจจะยากที่จะกำหนดเริ่มต้นและสิ้นสุดของเซสชั่น. Also, มันเป็นเรื่องยากในการคำนวณหรือระบุช่วงเวลาที่ไม่มีการใช้งาน. So, ในกรณีนี้, จะต้องไม่มีขอบเขตที่เหมาะสมสำหรับการกำหนดประชุมหรือแม้กระทั่งช่วงเวลาที่ไม่มีการใช้งาน. ในสถานการณ์เช่นนี้, สตรีมมิ่งการประมวลผลข้อมูลบนพื้นฐานเวลาจริงเป็นสิ่งจำเป็น.
Summary
แม้ว่า Spark มีประโยชน์มากเมื่อมันมาถึงการประมวลผลข้อมูลชุดและก็ยังมีจำนวนมากของกรณีการใช้งานมันสำคัญกับนัก, ก็ปรากฏว่า Flink เป็นไปอย่างรวดเร็วดึงดูดการลากในเชิงพาณิชย์. ความจริงที่ว่า Flink ยังสามารถทำการประมวลผลชุดที่ดูเหมือนว่าจะเป็นสิ่งที่ยิ่งใหญ่ในความโปรดปรานของ. Of course, จำเป็นที่จะต้องนำมาใช้ที่ความสามารถในการประมวลผลชุดของ Flink อาจไม่อยู่ในลีกเดียวกันกับที่จุดประกาย. So, Spark ยังคงมีบางเวลา.