Povpraševanje za hitrejšo obdelavo podatkov, se povečuje in se zdi, da je odgovor v realnem času obdelave pretakanje podatkov. Medtem ko je Apache Spark še vedno uporabljajo v veliko organizacij za velike obdelavo podatkov, Apache Flink je prihajajo hitro kot alternativa. In fact, mnogi mislijo, da ima potencial za zamenjavo Apache Spark zaradi svoje sposobnosti za obdelavo pretakanje podatkov v realnem času. Of course, Žirija o tem, ali lahko Flink nadomestiti Spark je še vedno, ker Flink je še, da je treba dati na razširjenih preskusov. Toda za obdelavo v realnem času in z nizkimi podatki latence sta dva od njegovih značilnosti, ki opredeljujejo. At the same time, to je treba upoštevati, da bo Apache Spark verjetno ne gredo v nemilost, ker bo svoje zmogljivosti za predelavo serije je še vedno aktualna.
Case za pretočni obdelavo podatkov
Za vse prednosti, ki temeljijo na batch obdelave, se zdi, da je veliko razlogov za realnem času obdelave podatkov streaming. Pretakanje obdelave podatkov omogoča, da vzpostavi in hitro nalaganje podatkovno skladišče. Pretakanje procesor, ki ima nizko podatkovno latenco daje večji vpogled v podatke hitro. So, imate več časa, da bi ugotovili, kaj se dogaja. Poleg hitrejši obdelavi, obstaja tudi druga pomembna korist: boste imeli več časa za oblikovanje ustreznega odziva na dogodke. For example, v primeru odkritja nepravilnosti, nižje latence in hitrejše odkrivanje omogoča identifikacijo najboljši odziv, ki je ključnega pomena za preprečitev škode v primerih, kot goljufive napadi na varno spletno stran ali industrijske poškodbe opreme. So, lahko prepreči znatno izgubo.
Kaj je Apache Flink?
Apache Flink je velik orodje za obdelavo podatkov in je znano, da obdela veliko podatkov hitro z nizko latenco podatkov in visoko toleranco napak na porazdeljenih sistemih v velikem obsegu. Njena značilno, je njegova sposobnost za obdelavo podatkov, pretakanje v realnem času.
Apache Flink je začelo kot akademski odprtokodni projekt in takrat, je bil znan kot stratosferi. Later, je postala del inkubatorja Apache Software Foundation. Da bi se izognili konfliktu v imenu z drugim projektom, ime je bilo spremenjeno v Flink. Ime Flink je primerna zato, ker to pomeni, okretna. Tudi izbrani logotip, veverica je primerno, ker je veverica predstavlja vrline agility, nimbleness in hitrost.
Ker je bil dodan Apache Software Foundation, je imela precej hiter dvig kot velik orodje za obdelavo podatkov in v 8 mesecev, ga je začel zajemanje pozornost širšega občinstva. Ljudska narašča zanimanje Flink se je odrazilo v številu udeležencev na številnih srečanjih v 2015. Število ljudi, ki se je udeležil sestanka na Flink na konferenci Strata v Londonu maja 2015 in vrh Hadoop v San Jose v juniju, 2015. Več kot 60 ljudi se je udeležilo Bay Area Apache Flink meet-up gostuje na sedežu MapR v San Jose v avgustu, 2015.
Na spodnji sliki daje Lambda arhitekturo Flink.
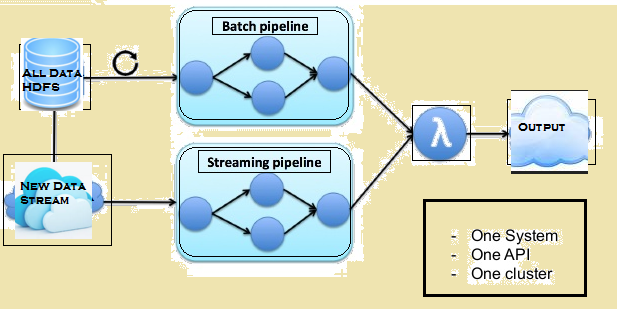
Lambda arhitektura Flink
Primerjava med Spark in Flink
Čeprav obstaja nekaj podobnosti med Spark in Flink, for example, njihove API in komponente, podobnosti ne zadeva veliko, ko gre za obdelavo podatkov. V nadaljevanju je primerjava med Flink in Spark.
Obdelava podatkov
Spark obdeluje podatke v svežnjih, medtem ko Flink obdeluje podatke pretakanje v realnem času. Spark predeluje količino podatkov, znan kot RDDs medtem ko Flink obdelati vrstice po vrstic podatkov v realnem času. So, medtem ko je minimalna podatki latence je vedno tam z Spark, to ni tako z Flink.
ponovitve
Spark podpira podatkovne ponovitev v serijah, vendar Flink lahko izvorno Ponovil svoje podatke z uporabo svojega streaming arhitekturo. Spodnja slika prikazuje, kako ponavljajoč predelava poteka.
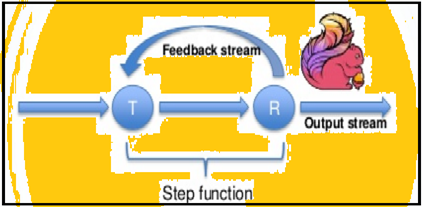
ponavljajoči se obdelava
upravljanje pomnilnika
Flink lahko samodejno prilagodijo različnih podatkovnih bazah, ampak Spark je treba optimizirati in ročno prilagodi svoje delovnih mest na posameznih podatkovnih bazah. Tudi Spark pa ročno delitev in predpomnjenje. So, pričakujemo nekaj zamude pri obdelavi.
Data Flow
Flink je sposoben zagotoviti vmesne rezultate glede obdelave njegovih podatkov kadarkoli zahteva. Medtem ko Spark sledi procesno programski sistem, Flink sledi pristopu porazdeljeno pretoka podatkov. So, kadarkoli vmesni rezultati so potrebni, oddaja spremenljivke se uporabljajo za distribucijo vnaprej izračuna rezultate do vseh vozliščih delavca.
Vizualizacija podatkov
Flink zagotavlja spletni vmesnik za predložitev in izvedbo vseh delovnih mest. Oba Spark in Flink so povezani z Apache Zeppelin in zagotavljanje podatkov zaužitje, podatki analytics, odkritje, sodelovanje in vizualizacija. Apache Zeppelin zagotavlja tudi multi-language baza, ki vam omogoča, da predložijo in izvajanje programov Flink.
predelava čas
V spodnjih odstavkih zagotoviti primerjavo med časom, ki ga Flink sprejeti in Spark na različnih delovnih mestih.
Da bi pošteno primerjavo, tako Flink in Spark so imeli iste vire v obliki specifikacij strojnih in konfiguracijah vozlišč.

konfiguracija Node
Kot je prikazano na sliki zgoraj, slika označeni z rdečo, navaja specifikacije stroj za procesor Flink, medtem ko tisti, poleg nje je razvidno, da procesorja Spark.
Kot je prikazano na sliki zgoraj, območje, označeni z rdečo prikazuje konfiguracijo vozlišče za procesor Flink in procesor Spark.
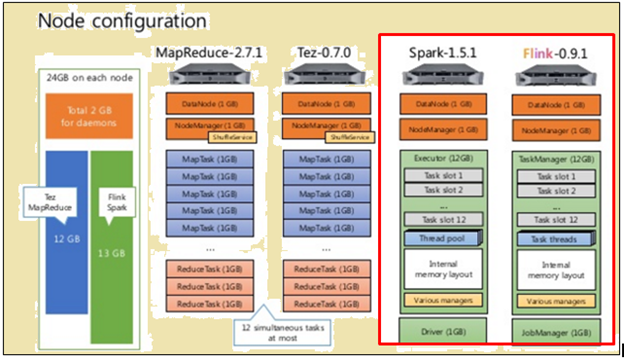
Spark procesor
Flink obdelujejo hitreje zaradi svoje cevovodni izvedbe. Za obdelavo podatkov, Spark je 2171 sekund, medtem ko Flink vzel 1490 sekund.
Ko smo opravili TeraSort z različnimi velikostmi podatkovnih, Naslednje so rezultati:
- za 10 datum GB, Flink žganjem 157 sekund v primerjavi z Spark 387 sekund.
- za 160 datum GB, Flink žganjem 3127 sekund v primerjavi z Spark 4927 sekund.
Temelji na serije ali Streaming podatkov - pri čemer postopek je boljši?
Oba procesa imata svoje prednosti in so primerni za različne situacije. Čeprav mnogi trdijo, da temeljijo na paketnih orodij gredo v nemilost, da se ne bo kmalu zgodilo. Da bi razumeli svoje relativne prednosti, glej naslednjo primerjavo:
| Streaming | betonarne |
| Podatki ali vložkov pridejo v obliki zapisov v določenem zaporedju. | Podatki ali vhodi so razdeljeni v serijah na podlagi števila zapisov ali časa. |
| Izhod je potrebno takoj, ko je mogoče, vendar ne prej kot v času, ki je potreben, da se preveri zaporedje. | Vhodi so podane na podlagi zahtev, ampak določeno število serij hranijo. |
| Izhod ni treba spremeniti, ko je zapisano. | Nova država in podatki o vseh vrstah proizvodnje so zabeležili. |
| Lahko storite tudi paketno obdelavo podatkov | Tega ne more storiti paketno obdelavo podatkov |
Obstajajo posamezne situacije, v kateri so tako Flink in predelava serije koristno. Vzemimo za primer uporabe računalniških tekoče mesečne prodaje na dnevnih presledkih. V tej dejavnosti, tisto, kar je potrebno, je za izračun dnevne prodaje skupaj in nato kumulativno vsoto. V primeru uporabe, kot je ta, se ne sme zahtevati obdelava pretakanje podatkov. paketno obdelavo podatkov lahko poskrbeli posameznih serij podatki o prodaji na podlagi datuma in jih nato dodamo. V tem primeru, čeprav obstaja podatki latenco, ki jih je vedno mogoče kasneje, ko je dodal, da latentna podatki kasnejših serij.
Tam so prav tako primeri uporabe, ki zahtevajo obdelavo pretakanje. Vzemimo za primer uporabe izračuna tekoči mesečni časa vsak obiskovalec preživi na spletni strani. V primeru spletne strani, število obiskov se lahko posodobijo, vsako uro, minute-pametno ali celo vsak dan. Ampak problem je v tem primeru opredeljuje sejo. Morda je težko opredeliti začetka in konca seje. Also, je težko izračunati ali prepoznavanje obdobja nedelovanja. So, v tem primeru, ne more biti nobene razumne meje za opredelitev sej ali celo obdobja nedelovanja. V primerih, kot ti, je potrebno pretakanje obdelava podatkov v realnem času.
Summary
Čeprav ima Spark veliko prednosti, ko gre za obdelavo podatkov serij in ima še veliko primerov uporabe pa skrbi za, se zdi, da je Flink hitro pridobiti komercialno oprijem. Zdi se, da je veliko stvari v njen prid dejstvo, da lahko Flink storite tudi paketno obdelavo. Of course, to je treba obračunati, da zmogljivosti za predelavo serije pri Flink ne sme biti v isti ligi kot je Spark. So, Spark ima še nekaj časa,.