Dopyt po rýchlejšie spracovanie dát rastie a real-time spracovanie streamovanie dát sa zdá byť odpoveď. Kým Apache Spark je stále používaný v mnohých organizácií, pre veľký spracovanie dát, Apache Flink bol rýchlo blíži ako alternatíva. In fact, mnohí si myslia, že má potenciál nahradiť Apache Spark vďaka svojej schopnosti spracovávať streamovanie dát v reálnom čase. Of course, porota o tom, či Flink môžu nahradiť Spark je ešte skoro, pretože Flink je ešte potrebné dať k rozsiahlym skúškam. Ale spracovanie v reálnom čase a nízka latencia Dáta sú dva z jeho určujúcich charakteristík. At the same time, Tento potrebné vziať do úvahy, že Apache Spark pravdepodobne nebude chodiť von láskavosti, pretože jej schopnosti spracovania dávkové bude stále aktuálne.
Puzdro pre Streaming spracovanie dát
Pre všetky zásluhy dávkového spracovania na základe, tam sa zdá byť dostatočne silný dôvod pre spracovanie dátových prúdov dát v reálnom čase. Streaming spracovanie dát umožňuje nastaviť a rýchlo načítať dátový sklad. Streaming procesor, ktorý má nízku latenciu dát poskytuje lepší prehľad o dátach rýchlo. So, budete mať viac času, aby zistili, čo sa deje. Okrem rýchlejšieho spracovania, tam je tiež ďalšia významná výhoda: budete mať viac času navrhnúť vhodnú reakciu na udalosti. For example, V prípade detekcie anomálií, nižšiu latenciu a rýchlejšia detekcia umožňuje určiť najlepšie odozvu, ktorá je kľúčom k zabráneniu poškodeniu v prípadoch, ako podvodné útoky na zabezpečené webové stránky alebo poškodenie priemyselného zariadenia. So, môžete zabrániť značnú stratu.
Čo je Apache Flink?
Apache Flink je veľký spracovanie dát nástroje a je známe, že rýchlo spracovať veľký dáta s nízkou latenciou dát a vysokú odolnosť proti chybám na distribuovaných systémov vo veľkom meradle. Jeho charakteristickým znakom je schopnosť spracovávať dáta dátových prúdov v reálnom čase.
Apache Flink nastupuje ako akademický open source projektu a vtedy, to bolo známe ako Stratosphere. Later, to sa stalo súčasťou inkubátore Apache Software Foundation. Aby nedochádzalo ku konfliktom v mene s iným projektom, bol názov zmenený na Flink. Meno Flink je vhodné, pretože to znamená, že agilné. Dokonca aj logo vybraná, veverička je vhodné, pretože veverička predstavuje cnosti agility, obratnosť a rýchlosť.
Vzhľadom k tomu, že bol pridaný do Apache Software Foundation, to malo dosť rýchly vzostup ako veľký spracovanie dát nástroje a vnútri 8 mesiaca, to začalo upútať pozornosť širšie publikum. Ľudová rastúci záujem o Flink sa odráža v počte účastníkov v rade schôdzok v 2015. Rad ľudí sa zúčastnilo stretnutia na Flink na konferencii Strata v Londýne v máji 2015 a Summit Hadoop v San Jose v júni, 2015. Viac ako 60 ľudí sa zúčastnilo Bay Area Apache Flink Meet-up hostované v sídle Mapro v San Jose v auguste, 2015.
Obrázok nižšie uvádza Lambda architektúru Flink.
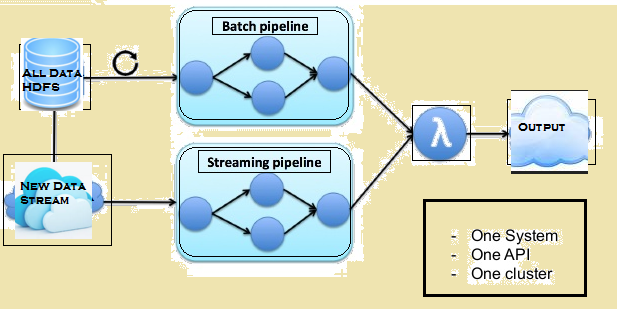
Lambda architektúra Flink
Porovnanie Spark a Flink
Hoci existuje niekoľko podobností medzi Spark a Flink, napríklad, ich API a komponenty, podobnosti nevadí moc, pokiaľ ide o spracovanie údajov. Nižšie je porovnanie medzi Flink a Spark.
Spracovanie dát
Spark spracováva dáta v dávkovom režime, zatiaľ čo Flink spracováva dáta streaming v reálnom čase. Spark spracováva bloky dát, známy ako RDDs zatiaľ čo Flink môže spracovať riadky po riadkov dát v reálnom čase. So, zatiaľ čo minimálna čakacia doba dát je vždy k dispozícii so zážihovým, to nie je tak s Flink.
iterácie
Spark podporuje prenosové iterácií v sériách, ale Flink môže natívne iterácii svoje dáta pomocou jeho streamovanie architektúry. Nižšie uvedený obrázok ukazuje, ako iteratívny spracovanie prebieha.
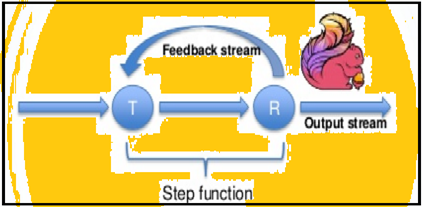
iteratívny spracovanie
správa pamäte
Flink môže automaticky prispôsobí rozmanitých dátových sád, ale Spark je potrebné optimalizovať a upraviť svoje úlohy ručne na jednotlivé súbory dát. Tiež Spark robí ručné delenie a caching. So, očakávať určité oneskorenie pri spracovaní.
tok dát
Flink je schopný poskytnúť priebežné výsledky na jeho spracovanie dát bude v prípade potreby. Kým Spark nasleduje procedurálny programovací systém, Flink nasleduje distribuovaný prístup dátový tok. So, kedykoľvek Priebežné výsledky sú požadované, vysielania premenné sa používajú na distribúciu pre-vypočítala výsledkov prostredníctvom do všetkých pracovných uzlov.
vizualizácia dát
Flink poskytuje webové rozhranie predložiť a vykonávať všetky úlohy. Obaja Spark a Flink sú integrované s Apache Zeppelin a poskytovať údaje požití, dáta analytics, objav, Spolupráca a vizualizácia. Apache Zeppelin tiež poskytuje viacjazyčnú backendu, ktorý umožňuje, aby predložili a spúšťať programy Flink.
Doba spracovania
Nasledujúce odseky poskytujú porovnanie medzi dobou, ktorú Flink a Spark v rôznych pracovných miest.
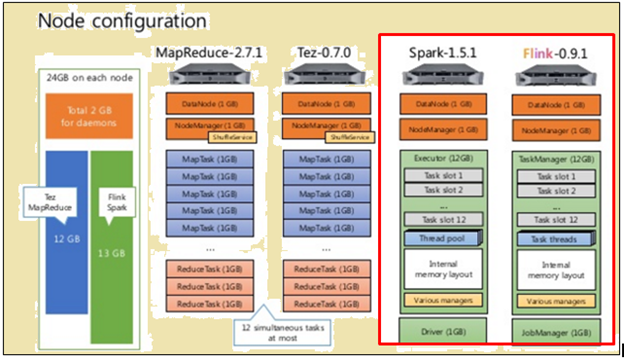
Ak chcete spravodlivé porovnanie, ako Flink a Spark dostali rovnaké prostriedky vo forme špecifikácie stroje a konfiguráciou uzla.

konfigurácia uzla
Ako je znázornené na obrázku vyššie, obraz označené červenou farbou označuje špecifikácie zariadenia pre spracovateľov Flink, zatiaľ čo jeden vedľa neho ukazuje, že zapaľovacie procesora.
Ako je znázornené na obrázku vyššie, oblasť zvýraznená na červeno označuje konfiguráciu uzla pre procesor Flink a Spark procesorom.
spark procesor
Flink spracované rýchlejšie, pretože jeho realizácia pipeline. spracovávať údaje, spark vzal 2171 sekúnd, zatiaľ čo Flink vzal 1490 sekundy.
Keď boli vykonané TeraSort s rôznymi veľkosťami dátových, Nasledujúce boli výsledky:
- pre 10 dátum GB, Flink streľba 157 sekúnd v porovnaní s Spark 387 sekundy.
- pre 160 dátum GB, Flink streľba 3127 sekúnd v porovnaní s Spark 4927 sekundy.
Batch na báze alebo streamovanie dát - pričom tento spôsob je lepší?
Oba procesy majú svoje výhody a sú vhodné pre rôzne situácie. Aj keď veľa z nich tvrdil, že nástroje pre dávkové báze idú von láskavosti, že sa to nestane v dohľadnej dobe. Pochopiť ich relatívnej výhody, viď nasledujúca porovnanie:
| Streaming | Dávkovanie |
| Údaje alebo zdrojové dáta dorazia v podobe záznamov v určitom poradí. | Údaje alebo vstupy sú rozdelené do dávok na základe počtu záznamov alebo času. |
| Výstup je nutná, akonáhle je to možné, ale nie skôr, než čas, ktorý je vyžadovaný na overenie sekvencie. | Vstupy sú zostavené na základe požiadaviek, ale určitý počet dávok sú zachované. |
| Výstup nemusí byť zmenený po tom, čo je napísané. | Nový stav a podrobnosti o všetkých riadkoch výstupu sú zaznamenané. |
| Môžete tiež vykonať dávkové spracovanie dát | Nie je schopný urobiť dávkové spracovanie dát |
Existujú jednotlivé situácie, v ktorej obe Flink a dávkové spracovanie sú užitočné. Vezmite si príklad použitia výpočtovej prevádzkového mesiaca tržby v denných intervaloch. V tejto činnosti, čo je potrebné, je pre výpočet denného Celkový predaj a potom sa kumulatívny súčet. V prípade použitia, ako je tento, nesmie požadovať spracovanie streamovanie dát. dávkové spracovanie dát môže postarať o jednotlivých šarží predajných štatistík vychádza z dát a potom pridať. V tomto prípade, aj keď tam je nejaká údaje latencia, ktorá môže byť vždy neskôr, keď je, že latentný údaje pridaný neskôr šarží.
Tam sú podobne používať prípady, ktoré vyžadujú spracovanie streamovanie. Vezmite si príklad použitia výpočtu prevádzkového mesiaca čas každý návštevník strávi na webových stránkach. V prípade, že webové stránky, počet návštev môže byť aktualizovaný, hodinový, minúta-múdry, alebo dokonca denne. Ale problém je v tomto prípade definuje reláciu. To môže byť ťažké definovať počiatočné a koncové relácie. Also, je ťažké pre výpočet alebo identifikovať obdobie nečinnosti. So, v tomto prípade, nemôže existovať žiadna rozumná hranica pre definovanie relácií či dokonca obdobie nečinnosti. V takýchto situáciách, Je potrebné streaming spracovanie dát v reálnom čase.
Summary
Hoci Spark má veľa výhod, pokiaľ ide o dávkové spracovanie dát a stále má veľa prípadov použitia Zameriava sa na, Zdá sa, že Flink sa rýchlo získava komerčné trakciu. Skutočnosť, že Flink si tiež urobiť dávkové spracovanie sa zdá byť obrovská vec v jej prospech. Of course, táto potreba byť vysvetlené, že schopnosti dávkové spracovanie Flink nemusia byť v rovnakej lige ako to Spark. So, Spark má ešte nejaký čas.