The demand for faster data processing has been increasing and real-time streaming data processing appears to be the answer. While Apache Spark is still being used in a lot of organizations for big data processing, Apache Flink foi subindo rapidamente como uma alternativa. In fact, muitos pensam que tem o potencial de substituir Apache faísca devido à sua capacidade para processar fluxo de dados em tempo real. Of course, o júri sobre se Flink pode substituir faísca é ainda para fora porque Flink ainda está para ser colocado para testes generalizados. Mas o processamento em tempo real e de baixa latência de dados são duas das suas características definidoras. At the same time, isso precisa ser considerado que o Apache faísca provavelmente não vai sair de favor, porque suas capacidades de processamento em lote será ainda relevante.
Case para Transmissão de Processamento de Dados
Para todos os méritos de processamento baseado em lote, parece haver um forte argumento para processamento de dados real-time streaming. Streaming de processamento de dados torna possível configurar e carregar um data warehouse rapidamente. Um processador de streaming que tem latência de dados de baixo dá mais esclarecimentos sobre os dados rapidamente. So, você tem mais tempo para descobrir o que está acontecendo. Além do processamento mais rápido, Há também uma outra vantagem significativa: você tem mais tempo para conceber uma resposta apropriada a eventos. For example, no caso de detecção de uma anomalia, menor latência e detecção mais rápida permite identificar a melhor resposta que é fundamental para evitar danos em casos como ataques fraudulentos em um site seguro ou danos no equipamento industrial. So, você pode evitar a perda substancial.
O que é Apache Flink?
Apache Flink é uma ferramenta de grande processamento de dados e sabe-se para processar grandes volumes de dados rapidamente com baixa latência de dados e alta tolerância a falhas em sistemas distribuídos em larga escala. Sua característica marcante é a sua capacidade para processar dados de streaming em tempo real.
Apache Flink começou como um projeto open source acadêmica e naquela época, era conhecida como estratosfera. Later, tornou-se uma parte da incubadora Apache Software Foundation. Para evitar conflitos de nome com outro projeto, o nome foi mudado para Flink. O nome Flink é apropriado porque significa ágil. Mesmo o logotipo escolhido, um esquilo é apropriado porque um esquilo representa as virtudes da agilidade, agilidade e velocidade.
Desde que foi adicionado à Apache Software Foundation, teve um aumento bastante rápido como uma ferramenta de grande processamento de dados e dentro 8 meses, que tinha começado a captar a atenção de um público mais amplo. crescente interesse das pessoas em Flink reflectiu-se no número de participantes em uma série de reuniões em 2015. Um número de pessoas participaram da reunião em Flink na Conferência Strata em Londres em Maio 2015 e na Cúpula Hadoop em San Jose em junho, 2015. Mais que 60 pessoas participaram da Bay Area Apache Flink meet-up hospedado na sede da MapR em San Jose em agosto, 2015.
A imagem abaixo dá a arquitetura Lambda de Flink.
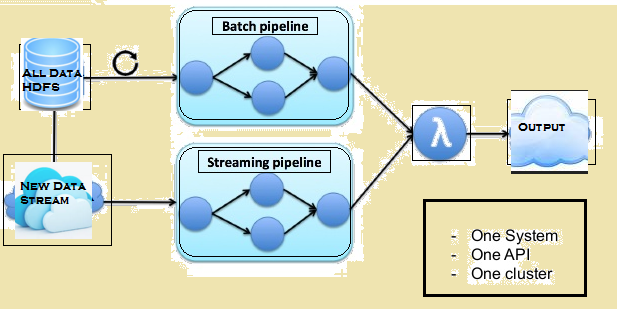
arquitetura Lambda de Flink
Comparação entre Faísca e Flink
Apesar de existirem algumas semelhanças entre Faísca e Flink, por exemplo, suas APIs e componentes, as semelhanças não importa muito quando se trata de processamento de dados. Dada a seguir é uma comparação entre Flink e faísca.
Processamento de dados
Faísca processa os dados no modo de lote, enquanto Flink processa dados de streaming em tempo real. Faísca processa blocos de dados, conhecido como RDDS enquanto Flink pode processar linhas após linhas de dados em tempo real. So, enquanto um mínimo de latência de dados é sempre lá com faísca, não é assim com Flink.
iterações
Faísca suporta iterações de dados em lotes, mas Flink pode nativamente iterar seus dados usando a sua arquitectura de streaming. A imagem abaixo mostra como iterativa processamento ocorre.
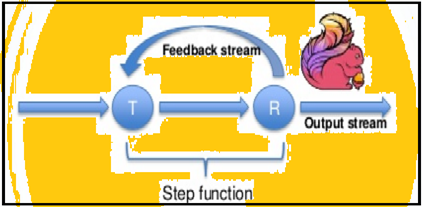
processamento iterativo
Gerenciamento de memória
Flink pode se adaptar automaticamente para conjuntos de dados variados, mas faísca precisa para otimizar e ajustar os seus postos de trabalho manualmente para conjuntos de dados individuais. Também faísca faz o particionamento manual e cache. So, esperar algum atraso no processamento.
Fluxo de dados
Flink é capaz de fornecer resultados intermediários em seu processamento de dados sempre que necessário. Enquanto faísca segue um sistema de programação procedural, Flink segue uma abordagem de fluxo de dados distribuídos. So, sempre que os resultados intermediários são necessários, variáveis de transmissão são usados para distribuir os resultados pré-calculados através de todos os nós do trabalhador.
Visualização de dados
Flink fornece uma interface web para apresentar e executar todos os trabalhos. Ambos faísca e Flink são integrados com o Apache Zeppelin e fornecer ingestão de dados, análise de dados, descoberta, colaboração e visualização. Apache Zeppelin também fornece um backend multi-linguagem que permite que você envie e executar programas Flink.
Tempo de processamento
Os parágrafos abaixo fornecem uma comparação entre o tempo gasto pelo Flink e faísca em diferentes postos de trabalho.
Para fazer uma comparação justa, tanto Flink e faísca foram dados os mesmos recursos, sob a forma de especificações da máquina e configurações do nó.

configuração do nó
Tal como mostrado na imagem acima, a imagem destacada em vermelho indica as especificações da máquina para um processador Flink enquanto o lado dele mostra que de um processador de faísca.
Tal como mostrado na imagem acima, a área destacada em vermelho indica a configuração do nó para um processador Flink e um processador de faísca.
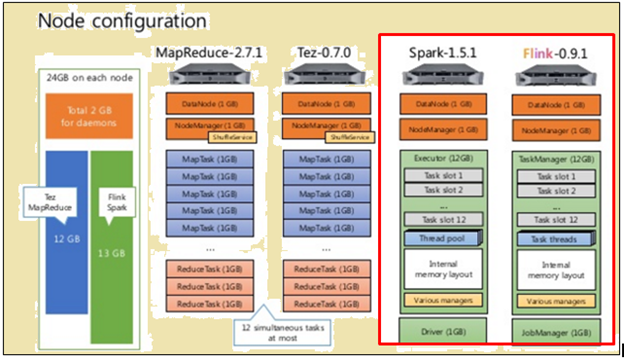
processador de faísca
Flink processadas mais rapidamente por causa da sua execução em pipeline. Para processar dados, faísca levou 2171 segundos enquanto Flink tomaram 1490 segundos.
Quando foram realizados TeraSort com vários tamanhos de dados, Estes foram os resultados:
- Para 10 data GB, Flink disparo 157 segundos em comparação com Spark 387 segundos.
- Para 160 data GB, Flink disparo 3127 segundos em comparação com Spark 4927 segundos.
Baseada em lote ou Transmissão de dados - processo que é melhor?
Ambos os processos têm vantagens e são adequadas para diferentes situações. Embora muitos estão reivindicando que ferramentas baseadas em lote estão saindo do favor, isso não vai acontecer tão cedo. Para entender as suas vantagens relativas, veja a seguinte comparação:
| Transmissão | batching |
| Dados ou entradas chegam na forma de registros em uma seqüência específica. | Dados ou entradas são divididos em lotes de acordo com o número de registos ou de tempo. |
| A saída é necessário logo que é possível, mas não mais cedo do que o tempo que é necessário para verificar a sequência. | As entradas são dadas com base em requisitos, mas um certo número de lotes são retidos. |
| A saída não precisam ser modificados depois de ser escrita. | Um novo estado e os detalhes de todas as linhas da saída são registradas. |
| também pode fazer o processamento em lote de dados | É incapaz de fazer o processamento em lote de dados |
Há situações individuais em que ambos Flink e processamento em lote são úteis. Tome o caso de uso de computação vendas mensais de rolamento em intervalos diários. Nesta actividade, o que é necessário é para calcular o total de vendas diário e, em seguida, fazer uma soma cumulativa. Em um caso de uso como este, processamento de streaming de dados pode não ser necessária. O processamento em lote de dados pode cuidar dos lotes individuais de números de vendas com base em datas e, em seguida, adicioná-los. Nesse caso, mesmo se houver alguma latência de dados, que pode ser sempre feita mais tarde quando os dados latente é adicionado para lotes posteriores.
Não são igualmente usar os casos que requerem processamento de streaming. Tome o caso de uso de calcular o tempo mensal de rolamento cada visitante gasta em um site. No caso de um site, o número de visitas podem ser actualizados, de hora em hora, minuto-wise ou mesmo diariamente. Mas o problema neste caso é que define a sessão. Pode ser difícil definir o início e término de uma sessão. Also, é difícil calcular ou identificar os períodos de inactividade. So, nesse caso, não pode haver limites razoáveis para definição de sessões ou mesmo períodos de inatividade. Em situações como essas, processamento de dados de streaming em uma base em tempo real é necessária.
Summary
Embora faísca tem uma série de vantagens quando se trata de processamento de dados em lote e ainda tem um monte de casos de uso que atende a, parece que Flink está rapidamente ganhando força comercial. O fato de que Flink também pode fazer o processamento em lote parece ser uma coisa enorme em seu favor. Of course, essa necessidade de ser responsável por que as capacidades de processamento em lote de Flink pode não estar na mesma liga como o de ignição. So, Faísca ainda tem algum tempo.