De vraag naar snellere gegevensverwerking is toegenomen en real-time streaming gegevensverwerking blijkt het antwoord. Terwijl Apache Spark wordt nog steeds gebruikt in een groot aantal organisaties voor big data processing, Apache Flink komt al snel als een alternatief. In fact, velen denken dat het de potentie heeft om Apache Spark vervangen vanwege zijn vermogen om streaming data real-time te verwerken. Of course, de jury over de vraag of Flink Spark kan vervangen is nog steeds uit, omdat Flink is nog niet op grote schaal tests worden gezet. Maar real-time verwerking en lage latency data zijn twee van de bepalende karakteristieken. At the same time, dit moet worden aangenomen dat Apache Spark waarschijnlijk niet zal gaan uit de gratie omdat de batch processing mogelijkheden nog relevant zullen zijn.
Case voor Streaming Data Processing
Voor alle verdiensten van batch-gebaseerde verwerking, lijkt er een sterke zaak voor real-time streaming data verwerking. Streaming verwerking van gegevens maakt het mogelijk op te zetten en snel laden van een datawarehouse. Een streaming processor die lage data latency heeft geeft meer inzicht op gegevens snel. So, heb je meer tijd om uit te vinden wat er gaande is. Naast snellere verwerking, er is ook een belangrijk voordeel is: heb je meer tijd om een passende reactie op gebeurtenissen te ontwerpen. For example, in het geval van anomaliedetectie, lagere latentie en snellere detectie kunt u het beste antwoord dat is de sleutel tot de schade in gevallen zoals frauduleuze aanvallen op een beveiligde website of industriële apparatuur schade te voorkomen te identificeren. So, kunt u aanzienlijk verlies te voorkomen.
Wat is Apache Flink?
Apache Flink is een grote gegevensverwerking gereedschap en het is bekend dat big data snel te verwerken met een lage data latency en een hoge fouttolerantie op gedistribueerde systemen op grote schaal. Zijn kenmerkende eigenschap is de mogelijkheid om streaming data in real-time te verwerken.
Apache Flink begon als een academisch open source project en toen, was het bekend als Stratosphere. Later, het werd een deel van de Apache Software Foundation incubator. Om conflicten in de naam te vermijden met een ander project, de naam werd veranderd in Flink. De naam Flink is passend omdat het agile betekent. Zelfs het logo gekozen, een eekhoorn is geschikt, omdat een eekhoorn vertegenwoordigt de deugden van de behendigheid, wendbaarheid en snelheid.
Omdat het werd toegevoegd aan de Apache Software Foundation, het had een vrij snelle stijging als een grote gegevensverwerking hulpmiddel en binnen 8 months, het was begonnen om de aandacht van een breder publiek te vangen. People's groeiende interesse in Flink werd weerspiegeld in het aantal deelnemers in een aantal bijeenkomsten in 2015. Een aantal mensen woonden de bijeenkomst op Flink aan de Strata Conference in Londen mei 2015 en de top van Hadoop in San Jose in juni, 2015. Meer dan 60 mensen woonden de Bay Area Apache Flink meet-up ondergebracht bij het MapR hoofdkantoor in San Jose in augustus, 2015.
De afbeelding hieronder geeft de Lambda architectuur van Flink.
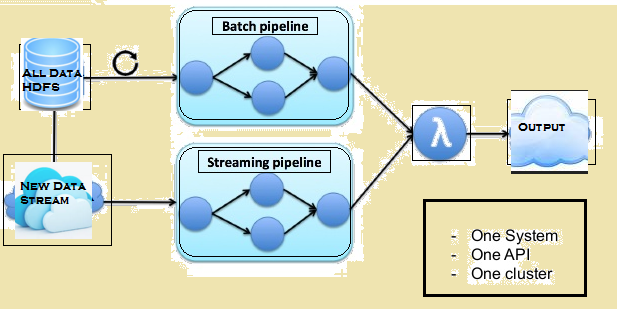
Lambda architectuur van Flink
Vergelijking tussen Spark en Flink
Hoewel er een paar overeenkomsten tussen Spark en Flink, bij voorbeeld, hun API's en onderdelen, de overeenkomsten niet veel uit als het gaat om gegevensverwerking. Hieronder is een vergelijking tussen Flink en Spark.
gegevensverwerking
Spark verwerkt gegevens in batch-modus, terwijl Flink verwerkt streaming data in real-time. Spark verwerkt brokken van gegevens, bekend als RDDs terwijl Flink rijen na rijen gegevens in real time kan verwerken. So, terwijl een minimale data latency is er altijd met Spark, is het niet zo met Flink.
herhalingen
Spark ondersteunt data iteraties in batches, maar Flink kan zijn gegevens native herhalen met behulp van de streaming architectuur. De afbeelding hieronder laat zien hoe iteratieve verwerking plaatsvindt.
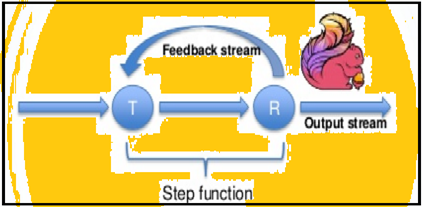
iteratieve verwerking
Geheugen management
Flink kan zich automatisch aanpassen aan verschillende datasets, maar Spark nodig heeft om te optimaliseren en haar banen handmatig aan te passen aan de individuele datasets. Ook Spark doet handmatige partitionering en caching. So, verwachten dat enige vertraging in de verwerking.
Informatiestroom
Flink is in staat om tussentijdse resultaten op de verwerking van gegevens te verstrekken wanneer nodig. Terwijl Spark volgt een procedureel programmeersysteem, Flink volgt een gedistribueerde data stroom aanpak. So, wanneer tussenresultaten vereist, uitzending variabelen worden gebruikt om door alle knooppunten de werknemer de vooraf berekende resultaten distribueren.
data Visualization
Flink biedt een webinterface voor te leggen en uit te voeren alle jobs. Zowel de Spark en Flink zijn geïntegreerd met Apache Zeppelin en gegevens verstrekken inslikken, data analytics, ontdekking, samenwerking en visualisatie. Apache Zeppelin biedt ook een multi-language backend die u toelaat om te leggen en uit te voeren programma's Flink.
Verwerkingstijd
De volgende paragrafen bieden een vergelijking tussen de tijd die Flink en Spark in verschillende banen.
Om een eerlijke vergelijking te maken, zowel Flink en Spark werden dezelfde middelen in de vorm van machinespecificaties en knooppuntconfiguraties.

knooppuntconfiguratie
Zoals aangegeven in de afbeelding hierboven, de afbeelding in het rood geeft de machine specificaties voor een Flink processor, terwijl de ene ernaast laat zien dat een Spark processor.
Zoals aangegeven in de afbeelding hierboven, het gebied gemarkeerd in rood geeft het knooppunt configuratie voor een Flink processor en een Spark processor.
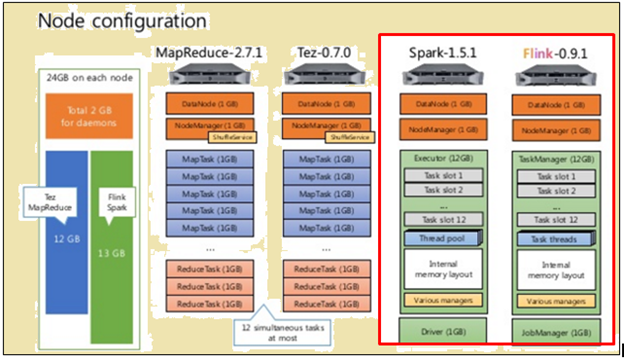
Spark processor
Flink sneller in behandeling nemen vanwege de pijplijn de. Om gegevens te verwerken, Spark nam 2171 seconden Flink nam 1490 seconden.
Wanneer TeraSort met diverse data formaten werden uitgevoerd, volgende waren de resultaten:
- Voor 10 GB date, Flink took 157 seconden ten opzichte van de Spark 387 seconden.
- Voor 160 GB date, Flink took 3127 seconden ten opzichte van de Spark 4927 seconden.
-Batch gebaseerde of Streaming Data - welk proces is beter?
Beide processen hebben voor- en geschikt voor verschillende situaties. Hoewel velen beweren dat batch-gebaseerde tools gaan uit de gratie, het is niet van plan om op elk moment snel gebeuren. Om hun relatieve voordelen te begrijpen, Zie de volgende vergelijking:
| streaming | batching |
| Gegevens of middelen komen in de vorm van records in een bepaalde volgorde. | Data ingang wordt onderverdeeld in batches op basis van het aantal records of tijd. |
| Uitgang vereist zo spoedig mogelijk doch niet eerder dan de tijd die nodig is om de volgorde te controleren. | Ingangen zijn toegekend op basis van de eisen, maar een aantal batches behouden. |
| Uitgang niet te worden aangepast na schrijven. | Een nieuwe staat en de details van alle rijen van de output worden opgenomen. |
| Kan ook doen batch verwerking van gegevens | Is niet in staat om batch verwerking van gegevens te doen |
Er individuele situaties waarin zowel Flink en batchverwerking bruikbaar. Neem de use case van IT-rollen maandelijkse verkopen bij dagelijkse intervallen. In deze activiteit, wat nodig is om de dagelijkse verkoop totaal te berekenen en vervolgens een cumulatieve som. In een geval als dit gebruik, streaming verwerking van gegevens kan niet worden verlangd. Batch verwerking van gegevens kan zorgen voor de afzonderlijke partijen van de verkoopcijfers op basis van de data en dan voeg ze toe. In dit geval, zelfs als er een aantal gegevens latency, die altijd kan worden later als latente data wordt toegevoegd aan later batches.
Er worden op dezelfde wijze te gebruiken zaken die streaming verwerking vereisen. Neem het use case voor de berekening van de rollende maandelijkse tijd elke bezoeker besteedt op een website. Bij een website, het aantal bezoeken kan worden bijgewerkt, ieder uur, minute-wijs of zelfs dagelijks. Het probleem in dit geval is het definiëren van de sessie. Het kan moeilijk zijn om het begin- en eindpunt van een sessie te definiëren. Also, Het is moeilijk te berekenen of identificeren van de perioden van inactiviteit. So, in dit geval, kan er geen redelijke grenzen voor het definiëren van sessies of zelfs periodes van inactiviteit. In situaties als deze, streaming verwerking van gegevens op een real-time basis is vereist.
Summary
Hoewel Spark heeft veel voordelen als het gaat om batch verwerking van gegevens en het heeft nog steeds een veel gebruik gevallen is geschikt voor, het lijkt erop dat Flink snel wint commerciële tractie. Het feit dat Flink ook kan doen batch processing lijkt een enorme ding in haar voordeel te zijn. Of course, Deze moeten worden opgenomen dat de batch processing mogelijkheden van Flink misschien niet in dezelfde competitie als die van de Spark. So, Spark heeft nog wat tijd.