Pieprasījums pēc ātrāku datu apstrādei ir pieaugusi un, šķiet reāllaika straumēšanas datu apstrādi, ir atbilde. Kamēr Apache Spark joprojām tiek izmantots daudz organizāciju lieliem datu apstrādes, Apache Flinks ir nāk klajā strauji kā alternatīvu. In fact, daudzi domā, ka tas ir potenciāls, lai aizstātu Apache Spark, jo tā spēj apstrādāt straumēšanas datu reālā laika. Of course, žūrija par to, vai Flinks var aizstāt Spark vēl pārbaudes jo Flinks vēl jāliek uz izplatītākajiem testi. Bet reālā laika datu apstrādi un zemu dati latentuma ir divi no tās pazīmēm. At the same time, Tas ir jāņem vērā, ka Apache Spark, iespējams, neko no labā, jo tās partijas apstrādes iespējas būs joprojām ir nozīmīgi.
Lieta par straumēšanas datu apstrādes
Attiecībā uz visiem nopelniem partijas bāzes apstrādes, šķiet, ka spēcīgs gadījums reāllaika straumēšanas datu apstrādi. Straumēšanas datu apstrādi ļauj izveidot un ielādēt datu noliktavu ātri. Straumēšanas procesoru, kas ir zems datu latentuma dod vairāk ieskatu par datiem ātri. So, Jums ir vairāk laika, lai uzzinātu, kas notiek. Papildus ātrāk apstrādi, ir arī vēl viens nozīmīgs ieguvums: Jums ir vairāk laika, lai izstrādātu piemērotu reakciju uz notikumiem. For example, gadījumā, ja anomāliju noteikšanai, zemāku latentuma un ātrāka noteikšana ļauj noteikt labāko atbildi, kas ir būtiska, lai novērstu bojājumus tādos gadījumos kā krāpnieciskas uzbrukumi drošā tīmekļa vietnē vai rūpniecisko iekārtu bojājumus. So, Jūs varat novērst būtiskus zaudējumus.
Kas ir Apache Flinks?
Apache Flinks ir liels datu apstrādes rīks, un tas ir zināms, ātri apstrādāt lielu datu ar zemu datu latentuma un augstu defektu pielaidi uz izplatīto sistēmu plašā mērogā. Tās raksturojoša iezīme ir tās spēja apstrādāt straumēšanas datus reālā laikā.
Apache Flinks sākās pie kā akadēmisku atvērtā koda projekts, un toreiz, tā bija pazīstama kā Stratosfēra. Later, tā kļuva par daļu no Apache Software Foundation inkubatorā. Lai izvairītos no konflikta vārda ar citu projektu, nosaukums tika mainīts uz Flinks. Nosaukums Flinks ir piemērots, jo tas nozīmē, veikls. Pat izvēlētā logo, vāvere ir piemērots, jo vāvere pārstāv tikumiem manevrētspēja, izveicība un ātrums.
Tā kā tas tika pievienots Apache Software Foundation, tas bija diezgan ātri pieaugt lielu datu apstrādes nolūkos, un laikā 8 mēneši, tas sāka attēlotu uzmanību plašākai auditorijai. Tautas pieaug interese Flinks atspoguļojās skaitu apmeklētāju vairākās sanāksmēs, kas 2015. Vairāki cilvēki piedalījās sanāksmē par Flinks pie Strata konferencē Londonā maijā 2015 un Hadoop samitā San Jose jūnijā, 2015. Vairāk par 60 cilvēki apmeklēja Bay Area Apache Flinks tikšanos up hosted pie MapR mītnē Sanhosē augustā, 2015.
zem attēla dod Lambda arhitektūru Flinks.
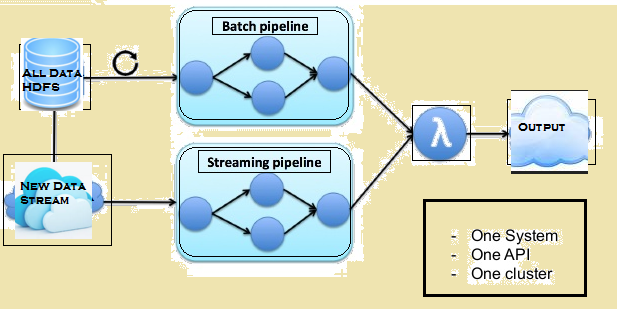
Lambda arhitektūra Flinks
Salīdzinājums starp Spark un Flinks
Lai gan ir dažas līdzības Spark un Flinks, piemēram, API un sastāvdaļas, līdzības nav jautājums daudz, kad runa ir par datu apstrādi. Ņemot vērā, zemāk ir salīdzinājums starp Flinks un Spark.
Datu apstrāde
Spark apstrādā datus partijas režīmā, kamēr Flinks apstrādā straumēšanas datiem reālā laikā. Spark apstrādā gabalos datu, pazīstams kā RDDs kamēr Flinks var apstrādāt rindas pēc rindas datus reālā laikā. So, bet minimālais datu latency ir vienmēr tur ar Spark, tas ir ne tik ar Flinks.
iterācijas
Spark atbalsta datu atkārtojumiem partijās bet Flinks var natively atkārtot savus datus, izmantojot savu straumēšanas arhitektūru. Sekojošā attēlā redzams, cik iteratīvs apstrāde notiek.
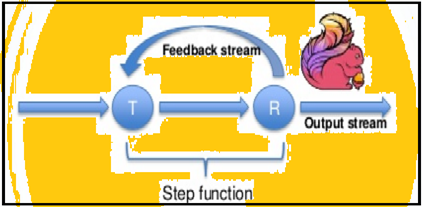
iteratīvs apstrāde
Memory Management
Flinks var automātiski pielāgoties dažādu datu kopu, bet Spark ir optimizēt un pielāgot tās darba roku uz atsevišķām datu kopām. Arī Spark dara manuālo sadalīšanu un caching. So, sagaidīt dažas apstrādes kavēšanās.
Data Flow
Flinks spēj sniegt starpposma rezultātus savā datu apstrādi, kad vien nepieciešams. Kaut Spark seko procesuālu plānošanas sistēmu, Flinks seko izplatīts datu plūsmas pieeju. So, kad starpposma rezultāti ir nepieciešami, apraides mainīgie tiek izmantoti, lai sadalītu iepriekš aprēķināts rezultātus cauri visiem darbinieku mezgliem.
Datu vizualizācija
Flinks nodrošina web interfeisu iesniegt un izpildīt visus darbus. Gan Spark un Flinks ir integrēti ar Apache Zeppelin un nodrošina datu ievākšanu, datu analītika, atklājums, sadarbība un vizualizācija. Apache Zeppelin nodrošina arī vairāku valodu backend, kas ļauj iesniegt un izpildīt Flinks programmas.
Apstrādes laiks
Turpmāk punkti sniedz salīdzinājumu starp, ko Flinks laika un Spark dažādās darba vietas.
Lai veiktu taisnīgu salīdzinājumu, gan Flinks un Spark tika dota tos pašus resursus formā iekārtu specifikācijas un mezglu konfigurācijas.

mezglu konfigurācija
Kā parādīts zemāk, attēls iezīmēts sarkanā krāsā norāda mašīnā specifikācijas ir Flinks procesoru, bet viens blakus, tas liecina, ka no Spark procesoru.
Kā parādīts zemāk, platība iezīmēts sarkanā norāda mezglu konfigurāciju pēc Flinks procesoru un Spark procesoru.
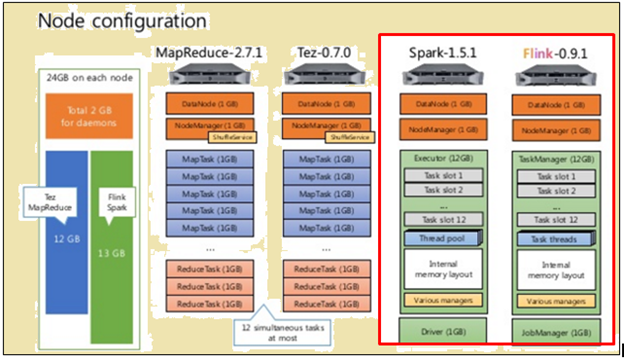
Spark procesors
Flinks apstrādāti ātrāk, jo tā konveijera izpildes. Apstrādāt datus, Spark paņēma 2171 sekundes, kamēr Flinks ņēma 1490 sekundes.
Kad tika veiktas TeraSort ar dažādiem datu izmēriem, Tālāk bija rezultāti:
- par 10 GB datums, Flinks apdedzinot 157 sekundes, salīdzinot ar Spark 387 sekundes.
- par 160 GB datums, Flinks apdedzinot 3127 sekundes, salīdzinot ar Spark 4927 sekundes.
Partijas bāzes vai Streaming Data - kas process ir labāk?
Abi procesi ir priekšrocības, un ir piemēroti dažādām situācijām. Lai gan daudzi apgalvo, ka partijas balstītu rīku dodas no labā, tas nav gatavojas jebkurā tuvākajā laikā notiks. Lai saprastu savas relatīvās priekšrocības, skatīt šādu salīdzinājumu:
| Streaming | dozēšana |
| Datus vai ieejas ierodas ierakstu veidā noteiktā secībā. | Dati vai ieejas ir sadalītas partijās, pamatojoties uz ierakstu skaitu vai laika. |
| Izejas ir nepieciešama, tiklīdz tas ir iespējams, bet ne ātrāk kā ar laiku, kas ir nepieciešams, lai pārbaudītu secību. | Ieejas tiek dota, pamatojoties uz prasībām, bet ir saglabātas noteiktu skaitu partijās. |
| Izejas nav nepieciešams mainīt pēc tā rakstīts. | Jauna valsts un informācija par visām rindām produkciju reģistrē. |
| Var arī veikt datu partijas apstrādes | Nevar darīt datu partijas apstrādes |
Ir atsevišķi gadījumi, kad gan Flinks un partijas apstrādes ir noderīgi. Veikt izmantošanas gadījumā skaitļošanas rites ikmēneša pārdošanas apjomus pie ikdienas intervāliem. Šajā pasākumā, to, kas ir vajadzīgs, ir aprēķināt ikdienas pārdošanas kopsummu un tad veikt kumulatīvo summu. Tādā izmantošanas gadījumā kā šis, nevar pieprasīt datu straumēšanas apstrāde. Datu partijas apstrādes var rūpēties par atsevišķu partiju pārdošanas rādītājiem, pamatojoties uz datumiem un tad pievienot tos. Šajā gadījumā, pat ja ir daži dati latentuma, ko vienmēr var sastāvēt vēlāk, kad, ka latentā dati tiek pievienoti vēlāk partijām.
Ir līdzīgi izmantot gadījumos, kas prasa straumēšanas apstrādi. Veikt izmantošanas gadījumu, aprēķinot kārtējā mēneša laikā katru apmeklētājs pavada mājas lapā. Gadījumā, ja mājas lapā, apmeklējumu skaits var atjaunināt, ik stundu, minūšu gudrs vai pat katru dienu. Bet problēma šajā gadījumā ir definēt sesijas. Tas var būt grūti noteikt sākuma un izbeigšanu sesijas. Also, ir grūti aprēķināt vai noteikt bezdarbības periodus. So, šajā gadījumā, nevar būt nekādas saprātīgas robežas definēšanas sesijas vai pat bezdarbības periodus. Situācijās, piemēram, šiem, ir nepieciešams straumēšanas datu apstrāde par reālajā laikā.
Summary
Lai gan Spark ir daudz priekšrocību, kad runa ir par partijas datu apstrādi, un tas joprojām ir daudz izmantošanas gadījumos Izklaides, šķiet, ka Flinks ir strauji gūst komerciālu vilci. Fakts, ka Flinks var arī darīt partijas apstrādes, šķiet, ir milzīgs lieta savā labā. Of course, tas nepieciešams jāatskaitās, ka partijas apstrādes spējas Flinks nedrīkst būt tajā pašā līgā, jo ka Spark. So, Spark vēl ir laiks.