The demand for faster data processing has been increasing and real-time streaming data processing appears to be the answer. While Apache Spark is still being used in a lot of organizations for big data processing, Apacheのフリンクは、代替として急速に来てされています. In fact, 多くは、それがために、ストリーミングデータをリアルタイムで処理する能力のアパッチスパークを交換する可能性があると思います. Of course, フリンクが普及テストに置かれることはまだあるので、フリンクはスパークを置き換えることができるかどうかの陪審はまだ外です. しかし、リアルタイム処理と低データ待ち時間は、その定義の特性の2つです. At the same time, これは、そのバッチ処理能力がまだ関連になりますので、Apacheのスパークは、おそらく好意から行かないことを考慮する必要があります.
ストリーミングデータ処理のためのケース
バッチベースの処理のすべてのメリットのために, リアルタイムストリーミングデータ処理のための強力な場合があるように思われます. データ処理をストリーミングは設定して、迅速にデータウェアハウスをロードすることが可能になります. 低いデータ待ち時間を有するストリーミングプロセッサは、迅速にデータの詳細な洞察を提供します. So, あなたは何が起こっているのを確認するために多くの時間を持っています. より迅速な処理に加えて、, 別の重要な利点もあります: あなたは、イベントへの適切な応答を設計するためのより多くの時間を持っています. For example, 異常検出の場合, 低遅延かつ迅速に検出は、安全なウェブサイトや産業機器の損傷に対する不正な攻撃として例で損傷を防止するためのキーである最良の応答を識別することができます. So, あなたは実質的な損失を防ぐことができます.
Apacheのフリンクとは何ですか?
Apacheのフリンクは、ビッグデータ処理ツールであり、大規模で分散システム上の低いデータレイテンシーと高いフォールトトレランスとすぐにビッグデータを処理することが知られています. その決定的な特徴は、リアルタイムでストリーミングデータを処理する能力であります.
Apacheのフリンクは、当時の学術オープンソース・プロジェクトとしてスタートし、, それは、ストラトスフィアとして知られていました. Later, それは、Apache Software Foundationのインキュベーターの一部となりました. 別のプロジェクトと名の紛争を避けるために、, 名前はフリンクに変更されました. それはアジャイル意味するので名前フリンクが適切です. 選択されたとしてもロゴ, リスは、俊敏性の美徳を表すのでリスが適切です, 敏捷とスピード.
それは、Apacheソフトウェア財団に追加されましたので、, それは、ビッグデータ処理ツールとして、また内ではなく、迅速な上昇がありました 8 ヶ月, それは、幅広い視聴者の注目をキャプチャするために始めました. フリンクの人々の関心の高まりは、会議の数の中で参加者の数に反映されました 2015. 人の数は5月にロンドンの地層会議でフリンクの会議に出席しました 2015 6月にサンノゼでのHadoopサミット, 2015. より多い 60 人々は、8月にサンノゼでMAPR本社でホストされているベイエリアのApacheフリンクミートアップに参加しました, 2015.
下の画像は、フリンクのラムダ・アーキテクチャを提供します.
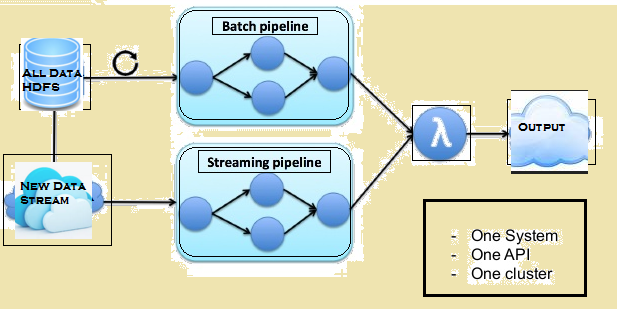
フリンクのラムダ・アーキテクチャ
スパークとフリンクとの比較
スパークとフリンクの間にいくつかの類似点がありますが, 例えば, 彼らのAPIおよびコンポーネント, それは、データ処理に来るとき類似性はあまり重要ではありません。. 下記のフリンクとスパークとの比較であります.
情報処理
フリンクリアルタイムでストリーミングデータを処理しながら、バッチモードでの処理データをスパーク. スパークは、データのチャンクを処理します, フリンクは、リアルタイムでデータの行の後に行を処理することができながら、RDDSとして知られています. So, 最小データ待ち時間は、Sparkと常にある一方で, それはフリンクとそうではありません.
イテレーション
スパークは、バッチでデータの反復をサポートしていますが、フリンクは、ネイティブのストリーミング・アーキテクチャを使用して、そのデータを反復処理することができます. 下の画像は、処理が行われる方法を反復示し.
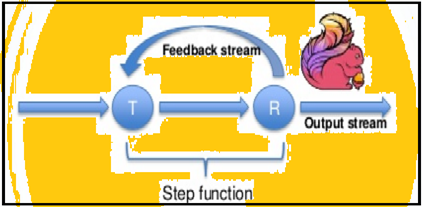
反復処理
メモリ管理
フリンクは、自動的に様々なデータセットに適応することができますが、スパークは、最適化し、個々のデータセットに手動でそのジョブを調整する必要があります. また、スパークは、手動パーティション分割とキャッシュを行います. So, 処理中に多少の遅延を期待します.
データフロー
FLINKは、必要なときはいつでも、そのデータ処理の中間結果を提供することができます. スパークは、手続き型プログラミングシステムを次の一方で, FLINKは、分散データ・フロー・アプローチに従います. So, 中間結果が必要とされるたびに, 変数はすべてのワーカーノードまで事前計算結果を配布するために使用されるブロードキャスト.
データ可視化
フリンクは提出し、すべてのジョブを実行するためのWebインターフェイスを提供します. スパークとフリンクの両方は、Apacheツェッペリンと統合され、データの摂取を提供しています, データ分析, 発見, コラボレーションと可視化. Apacheのツェッペリンはまた、あなたが提出しフリンクのプログラムを実行することを可能にする多言語のバックエンドを提供します.
処理時間
以下の段落では、異なるジョブにフリンクとスパークにかかる時間との比較を提供します.
公正な比較を行うために、, フリンクとスパークの両方がマシンの仕様およびノード構成の形で同じリソースを与えられました.

ノード構成
上の画像に示すように、, 画像は赤で強調表示、それはスパークプロセッサのことを示して横に1ながらフリンクプロセッサ用のマシンの仕様を示し、.
上の画像に示すように、, 赤で強調表示された領域は、フリンクプロセッサとスパークプロセッサ用のノード構成を示し、.
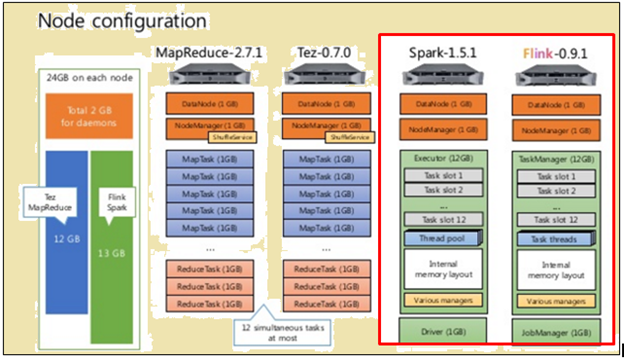
スパークプロセッサ
フリンクは、そのパイプライン実行の速い処理さ. データを処理します, スパークがかかりました 2171 秒フリンクがかかっている間 1490 秒.
様々なデータサイズのTeraSortを行った場合には, 以下の結果でした:
- ために 10 GB日, フリンクがかかりました 157 スパークのに比べ秒 387 秒.
- ために 160 GB日, フリンクがかかりました 3127 スパークのに比べ秒 4927 秒.
プロセスが優れている - バッチベースまたはストリーミングデータ?
両方のプロセスが利点を持っており、さまざまな状況に適しています. 多くは、バッチベースのツールは好意から行っていると主張しているが, いつでもすぐに起こるだろうされていません. それらの相対的な利点を理解するために、, 以下の比較を参照してください:
| ストリーミング | 計量 |
| データまたは入力が特定の順序でレコードの形式に到着します. | データまたは入力は、レコードの数や時間に基づいてバッチに分割されています. |
| 出力は、できるだけ早くであるとしてではなく、早くシーケンスを検証するために必要とされる時間よりも必要とされています. | 入力は、要件に基づいて与えられているが、バッチの一定数が保持されます. |
| それが書かれた後に出力を変更する必要はありません. | 新しい状態と出力のすべての行の詳細が記録されています. |
| また、データのバッチ処理を行うことができます | データのバッチ処理を行うことができません |
フリンクとバッチ処理の両方が有用である個々の状況があります. 毎日の間隔でローリング月次売上高を計算するユースケースを取ります. このアクティビティで, 必要とされるのは、毎日の売上合計を計算し、その後、累積和を作ることです. このような使用例では, データのストリーミング処理が必要とされないかもしれません. データのバッチ処理は日付に基づいて売上高の個々のバッチの世話をし、それらを追加することができます. この場合, いくつかのデータの遅延がある場合であっても, 常にその潜在データを後でバッチに追加され、後で時まで作製することができます.
同様に、ストリーミング処理を必要とするケースが使用されています. 各訪問者がウェブサイトに費やすローリング毎月の時間を計算するユースケースを取ります. ウェブサイトの場合、, 訪問回数を更新することができます, 毎時, 分単位、あるいは毎日. しかし、この場合の問題は、セッションを定義されています. セッションの開始と終了を定義することが困難な場合があります. Also, 計算または非活動期間を識別することは困難です. So, この場合, セッションや非活動であっても期間を定義するための合理的な境界が存在しないことができます. このような状況では, リアルタイムのストリーミングデータ処理が要求されます.
Summary
スパークは、多くの利点がありますが、それは、バッチデータ処理に来ると、それはまだそれがニーズに応えるの使用例をたくさん持っているとき、, フリンクは速い商用勢いを増しているように見え. フリンクはまた、バッチ処理を行うことができるという事実は、その好意で巨大なものであると思われます. Of course, この必要性は、フリンクのバッチ処理能力がスパークと同じリーグでなくてもよいことが考慮されるために. So, スパークは、まだいくつかの時間を持っています.