La domanda per l'elaborazione dei dati più veloce è in aumento e in tempo reale l'elaborazione dei dati in streaming sembra essere la risposta. Mentre Apache Spark è ancora in uso in molte organizzazioni per la grande elaborazione dei dati, Apache Flink è venuta in fretta come alternativa. In fact, Molti pensano che ha il potenziale di sostituire Apache Spark a causa della sua capacità di elaborare i dati in streaming in tempo reale. Of course, la giuria se Flink può sostituire Spark è ancora fuori perché Flink deve ancora essere messo a test diffusi. Ma elaborazione in tempo reale e la latenza di dati a bassa sono due delle sue caratteristiche che la definiscono. At the same time, questo deve essere considerato che Apache Spark probabilmente non andare in disgrazia perché le sue capacità di elaborazione in batch saranno ancora rilevanti.
Custodia per Streaming Elaborazione Dati
Per tutti i meriti di elaborazione batch-based, sembra che vi sia una forte necessità di elaborazione in tempo reale dei dati di streaming. Streaming elaborazione dei dati consente di creare e caricare un data warehouse in fretta. Un processore streaming che ha latenza dei dati a basso dà ulteriori delucidazioni sui dati in modo rapido. So, si ha più tempo per scoprire cosa sta succedendo. Oltre al trattamento veloce, c'è anche un altro vantaggio significativo: si ha più tempo per progettare una risposta adeguata agli eventi. For example, in caso di rilevamento delle anomalie, minore latenza e rilevazione più veloce consente di identificare la migliore risposta che è la chiave per evitare danni in casi come gli attacchi fraudolenti su un sito web sicuro o danni alle apparecchiature industriali. So, è possibile prevenire la perdita sostanziale.
Che cosa è Apache Flink?
Apache Flink è un grande strumento di elaborazione dei dati ed è noto per elaborare dati grandi rapidamente con bassa latenza dei dati e elevata tolleranza guasti su sistemi distribuiti su larga scala. La sua caratteristica principale è la capacità di elaborare i dati in streaming in tempo reale.
Apache Flink iniziato come un progetto open source accademico e allora, era conosciuta come Stratosphere. Later, entrò a far parte dell'incubatore Apache Software Foundation. Per evitare conflitti di nome con un altro progetto, il nome fu cambiato in Flink. Il nome Flink è appropriato perché significa agile. Anche il logo scelto, uno scoiattolo è appropriato perché uno scoiattolo rappresenta le virtù di agilità, agilità e la velocità.
Da quando è stato aggiunto alla Apache Software Foundation, essa ha avuto un aumento piuttosto rapido come un grande strumento di elaborazione dei dati e all'interno 8 mesi, aveva iniziato a catturare l'attenzione di un pubblico più vasto. crescente interesse popolare in Flink è riflesso nel numero di partecipanti in una serie di incontri in 2015. Un certo numero di persone hanno partecipato alla riunione del Flink alla Conferenza Strata a Londra nel maggio 2015 e il vertice Hadoop a San Jose nel mese di giugno, 2015. Più di 60 persone hanno partecipato alla meet-up Bay Area Apache Flink ospitata presso la sede MAPR a San Jose nel mese di agosto, 2015.
L'immagine che segue riporta l'architettura Lambda di Flink.
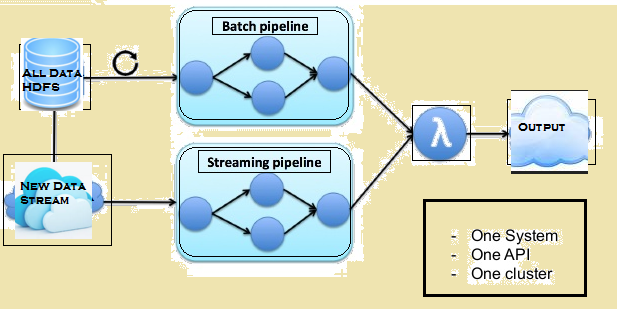
architettura Lambda di Flink
Confronto tra Spark e Flink
Anche se ci sono alcune somiglianze tra Spark e Flink, per esempio, loro API e componenti, Le somiglianze non ha molta importanza quando si tratta di elaborazione dei dati. Dato che segue è un confronto tra Flink e Spark.
Elaborazione dati
Spark elabora i dati in modalità batch mentre Flink elabora i dati in streaming in tempo reale. Spark elabora blocchi di dati, conosciuto come RDDs mentre Flink in grado di elaborare righe dopo righe di dati in tempo reale. So, mentre una latenza minima di dati è sempre lì con Spark, non è così con Flink.
iterazioni
Spark supporta iterazioni di dati in lotti ma Flink può nativamente iterare i propri dati utilizzando la sua architettura di streaming. L'immagine sotto mostra come iterativo trasformazione avviene.
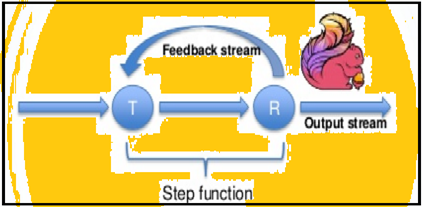
elaborazione iterativa
Gestione della memoria
Flink in grado di adattarsi automaticamente alle diverse serie di dati, ma Spark ha bisogno di ottimizzare e modificare i suoi posti di lavoro manualmente a singoli gruppi di dati. Anche Spark fa partizionamento manuale e caching. So, aspettare qualche ritardo nella lavorazione.
Flusso di dati
Flink è in grado di fornire risultati intermedi la sua elaborazione dati in qualsiasi momento. Mentre Spark segue un sistema di programmazione procedurale, Flink segue un approccio dei flussi di dati distribuiti. So, ogni volta che i risultati intermedi sono obbligatori, variabili broadcast vengono utilizzati per distribuire i risultati precalcolati attraverso tutti i nodi lavoratore.
Data Visualization
Flink fornisce un'interfaccia web per presentare ed eseguire tutti i lavori. Sia Spark e Flink sono integrati con Apache Zeppelin e di fornire l'ingestione dei dati, analisi dei dati, scoperta, la collaborazione e la visualizzazione. Apache Zeppelin fornisce anche un back-end multi-lingua che permette di inoltrare ed eseguire programmi Flink.
tempo di elaborazione
I paragrafi seguenti forniscono un confronto tra il tempo impiegato da Flink e Spark in diversi posti di lavoro.
Per fare un confronto equo, sia Flink e Spark sono state date le stesse risorse, sotto forma di specifiche della macchina e configurazioni di nodi.

configurazione del nodo
Come mostrato nell'immagine sopra, l'immagine evidenziata in rosso indica le specifiche della macchina per un processore Flink mentre quello accanto mostra che di un processore Spark.
Come mostrato nell'immagine sopra, l'area evidenziata in rosso indica la configurazione del nodo per un processore Flink e un processore Spark.
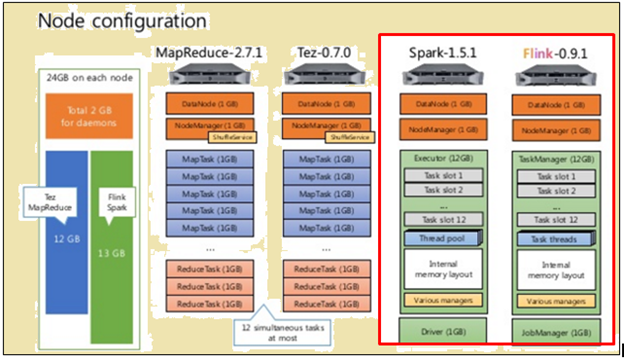
processore Spark
Flink elaborato più velocemente a causa della sua esecuzione pipeline. Per elaborare i dati, Spark ha preso 2171 secondi mentre Flink ha preso 1490 secondi.
Quando sono stati eseguiti TeraSort con i vari formati di dati, Erano i risultati:
- Per 10 GB data, Flink cottura 157 secondi rispetto a Spark di 387 secondi.
- Per 160 GB data, Flink cottura 3127 secondi rispetto a Spark di 4927 secondi.
Batch-based in Streaming dati - quale processo è meglio?
Entrambi i processi hanno vantaggi e sono adatte per le diverse situazioni. Anche se molti affermano che gli strumenti di batch-based stanno andando in disgrazia, non sta per accadere in qualunque momento presto. Per capire i loro vantaggi relativi, vedere il seguente confronto:
| Streaming | Dosaggio |
| I dati o ingressi pervengono in forma di record in una sequenza specifica. | I dati o ingressi sono suddivisi in lotti in base al numero di record o tempo. |
| Uscita è necessaria più presto è possibile, ma non prima del tempo necessario a verificare la sequenza. | Gli ingressi sono dati in base alle esigenze, ma un certo numero di lotti vengono mantenute. |
| Uscita non ha bisogno di essere modificato dopo che è stato scritto. | Un nuovo stato e i dettagli di tutte le righe della uscita sono registrati. |
| Può anche fare l'elaborazione in batch dei dati | È in grado di fare l'elaborazione in batch dei dati |
Ci sono singole situazioni in cui sia Flink e l'elaborazione in batch sono utili. Prendete il caso d'uso di calcolare le vendite mensili di laminazione a intervalli giornalieri. In questa attività, ciò che è necessario è quello di calcolare il totale delle vendite al giorno e poi fare una somma cumulativa. In un caso d'uso come questo, l'elaborazione di streaming dei dati potrebbe non essere necessaria. L'elaborazione batch dei dati può prendersi cura dei singoli lotti di dati di vendita in base alle date e poi aggiungerli. In questo caso, anche se vi è una certa latenza dei dati, che può essere sempre costituita tardi quando i dati latente viene aggiunto lotti successivi.
Ci sono similmente casi d'uso che richiedono l'elaborazione in streaming. Prendete il caso d'uso del calcolo del tempo mensile rolling ogni visitatore trascorre su un sito web. In caso di un sito web, il numero di visite può essere aggiornato, ogni ora, minuto-saggio o anche ogni giorno. Ma il problema in questo caso è la definizione della sessione. Può essere difficile da definire l'inizio e la fine di una sessione. Also, è difficile calcolare o identificare i periodi di inattività. So, in questo caso, non ci possono essere limiti ragionevoli per definire le sessioni o anche periodi di inattività. In situazioni come queste, è richiesta l'elaborazione dei dati in streaming su una base in tempo reale.
Summary
Anche se Spark ha un sacco di vantaggi quando si tratta di elaborazione dei dati in batch e ha ancora un sacco di casi d'uso si rivolge a, sembra che Flink sta rapidamente guadagnando trazione commerciale. Il fatto che Flink può anche fare l'elaborazione in batch sembra essere una cosa enorme in suo favore. Of course, questa necessità di essere rappresentato che le capacità di elaborazione in batch di Flink potrebbero non essere nella stessa lega come quella di Spark. So, Spark ha ancora un po 'di tempo.