Permintaan untuk pengolahan data yang lebih cepat telah meningkat dan pengolahan data mengalir yg tanpa jeda tampaknya menjadi jawaban. Sementara Apache Spark masih digunakan di banyak organisasi untuk pengolahan data yang besar, Apache Flink telah datang dengan cepat sebagai alternatif. In fact, banyak yang berpikir bahwa ia memiliki potensi untuk menggantikan Apache Spark karena kemampuannya untuk memproses data streaming real time. Of course, juri pada apakah Flink dapat menggantikan Spark masih keluar karena Flink belum dimasukkan ke tes meluas. Tapi real-time pengolahan dan latency data rendah adalah dua dari karakteristik mendefinisikan nya. At the same time, ini perlu dipertimbangkan bahwa Apache Spark mungkin tidak akan pergi dari nikmat karena kemampuan pemrosesan batch yang akan masih relevan.
Kasus untuk Streaming Pengolahan Data
Untuk semua manfaat dari pengolahan berbasis-batch, tampaknya ada kasus yang kuat untuk real-time pengolahan data streaming yang. Streaming pengolahan data memungkinkan untuk mengatur dan memuat data warehouse cepat. Sebuah Streaming prosesor yang memiliki latency data rendah memberikan wawasan lebih pada data cepat. So, Anda memiliki lebih banyak waktu untuk mencari tahu apa yang sedang terjadi. Selain pengolahan lebih cepat, ada juga manfaat yang signifikan lain: Anda memiliki lebih banyak waktu untuk merancang sebuah respon yang tepat untuk acara. For example, dalam kasus deteksi anomali, latency rendah dan deteksi cepat memungkinkan Anda untuk mengidentifikasi respon terbaik yang merupakan kunci untuk mencegah kerusakan dalam kasus seperti serangan penipuan pada website yang aman atau kerusakan peralatan industri. So, Anda dapat mencegah kerugian besar.
Apa Apache Flink?
Apache Flink adalah alat pengolahan data besar dan dikenal untuk mengolah data besar dengan cepat dengan latency data rendah dan toleransi kesalahan yang tinggi pada sistem terdistribusi dalam skala besar. Fitur yang mendefinisikan adalah kemampuannya untuk memproses data streaming real time.
Apache Flink dimulai sebagai sebuah proyek open source akademis dan saat itu, itu dikenal sebagai Stratosphere. Later, itu menjadi bagian dari inkubator Apache Software Foundation. Untuk menghindari konflik nama dengan proyek lain, nama ini diubah untuk Flink. Nama Flink adalah tepat karena berarti tangkas. Bahkan logo yang dipilih, tupai adalah tepat karena tupai merupakan kebajikan kelincahan, kegesitan dan kecepatan.
Sejak itu ditambahkan ke Apache Software Foundation, itu kenaikan lebih cepat sebagai alat pengolahan data besar dan dalam 8 months, itu sudah mulai menangkap perhatian audiens yang lebih luas. minat masyarakat tumbuh di Flink tercermin dalam jumlah peserta dalam sejumlah pertemuan di 2015. Sejumlah orang menghadiri pertemuan pada Flink di Konferensi Strata di London pada Mei 2015 dan KTT Hadoop di San Jose pada bulan Juni, 2015. Lebih dari 60 orang menghadiri Bay Area Apache Flink bertemu-up host di markas MapR di San Jose pada bulan Agustus, 2015.
Gambar di bawah memberikan arsitektur Lambda dari Flink.
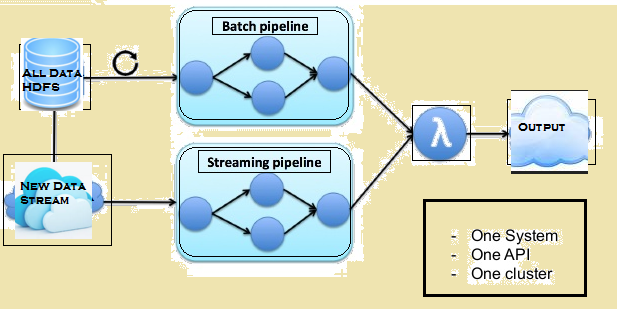
Lambda arsitektur Flink
Perbandingan antara Spark dan Flink
Meskipun ada beberapa kesamaan antara Spark dan Flink, misalnya, API dan komponen mereka, kesamaan tidak peduli banyak ketika datang ke pengolahan data. Diberikan di bawah ini perbandingan antara Flink dan Spark.
Pengolahan data
Spark memproses data dalam modus batch sementara Flink proses streaming data secara real time. Spark memproses potongan data, dikenal sebagai RDDS sementara Flink dapat memproses baris setelah baris data secara real time. So, sementara latency Data minimum selalu ada dengan Spark, itu tidak begitu dengan Flink.
iterasi
Spark mendukung iterasi data dalam batch tapi Flink native dapat iterate datanya dengan menggunakan arsitektur streaming. Gambar di bawah menunjukkan bagaimana berulang pengolahan berlangsung.
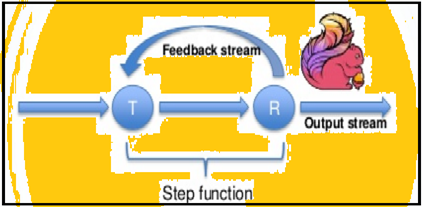
pengolahan berulang
Manajemen memori
Flink otomatis dapat beradaptasi dengan dataset bervariasi tetapi Spark perlu mengoptimalkan dan menyesuaikan pekerjaan secara manual ke dataset individu. Juga Spark melakukan partisi manual dan caching. So, mengharapkan beberapa penundaan proses.
Aliran data
Flink mampu memberikan hasil antara pengolahan datanya kapanpun dibutuhkan. Sementara Spark mengikuti sistem pemrograman prosedural, Flink mengikuti pendekatan aliran data terdistribusi. So, setiap kali hasil antara yang diperlukan, variabel siaran digunakan untuk mendistribusikan hasil pra-dihitung melalui ke semua node pekerja.
Data Visualisasi
Flink menyediakan antarmuka web untuk menyerahkan dan melaksanakan semua pekerjaan. Kedua Spark dan Flink terintegrasi dengan Apache Zeppelin dan memberikan data konsumsi, analisis data yang, penemuan, kolaborasi dan visualisasi. Apache Zeppelin juga menyediakan backend multi-bahasa yang memungkinkan Anda untuk mengirimkan dan mengeksekusi program Flink.
waktu memproses
Paragraf di bawah memberikan perbandingan antara waktu yang dibutuhkan oleh Flink dan Spark di pekerjaan yang berbeda.
Untuk membuat perbandingan yang adil, baik Flink dan Spark diberi sumber daya yang sama dalam bentuk spesifikasi mesin dan konfigurasi simpul.

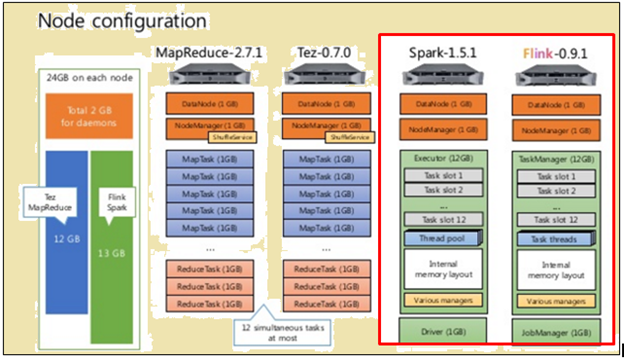
konfigurasi Node
Seperti yang ditunjukkan pada gambar di atas, gambar disorot dalam warna merah menunjukkan spesifikasi mesin untuk prosesor Flink sementara satu di samping itu menunjukkan bahwa dari prosesor Spark.
Seperti yang ditunjukkan pada gambar di atas, daerah disorot dalam warna merah menunjukkan konfigurasi simpul untuk prosesor Flink dan prosesor Spark.
prosesor Spark
Flink diproses lebih cepat karena eksekusi pipelined nya. Untuk mengolah data, Spark mengambil 2171 detik sementara Flink mengambil 1490 detik.
Ketika TeraSort dengan berbagai ukuran data yang dilakukan, Berikut adalah hasil:
- Untuk 10 tanggal GB, Flink tembak 157 detik dibandingkan dengan Spark ini 387 detik.
- Untuk 160 tanggal GB, Flink tembak 3127 detik dibandingkan dengan Spark ini 4927 detik.
berdasarkan Batch-atau Streaming data - yang proses lebih baik?
Kedua proses memiliki kelebihan dan cocok untuk situasi yang berbeda. Meskipun banyak yang mengklaim bahwa alat berbasis batch akan keluar dari nikmat, itu tidak akan terjadi dalam waktu dekat. Untuk memahami keuntungan relatif mereka, melihat perbandingan berikut:
| Streaming | batching |
| Data atau input tiba dalam bentuk catatan dalam urutan tertentu. | Data atau input dibagi menjadi batch berdasarkan jumlah record atau waktu. |
| Output diperlukan sesegera mungkin tetapi tidak lebih cepat dari waktu yang diperlukan untuk memverifikasi urutan. | Input yang diberikan berdasarkan kebutuhan tetapi sejumlah batch dipertahankan. |
| Output tidak perlu diubah setelah ada tertulis. | Sebuah negara baru dan rincian semua baris dari output dicatat. |
| Bisa juga melakukan batch processing data | Tidak dapat melakukan batch processing data |
Ada situasi individu di mana kedua Flink dan pengolahan Batch berguna. Ambil kasus penggunaan komputasi penjualan bulanan bergulir pada interval setiap hari. Dalam kegiatan ini, apa yang dibutuhkan adalah untuk menghitung harian total penjualan dan kemudian membuat jumlah kumulatif. Dalam kasus penggunaan seperti ini, pengolahan streaming data mungkin tidak diperlukan. batch processing data dapat mengurus batch individu angka penjualan berdasarkan tanggal dan kemudian menambahkannya. Pada kasus ini, bahkan jika ada beberapa latency Data, yang selalu bisa dibuat kemudian ketika data laten ditambahkan ke batch kemudian.
Ada yang sama menggunakan kasus yang memerlukan pengolahan Streaming. Ambil kasus penggunaan menghitung waktu bulanan bergulir setiap pengunjung menghabiskan pada sebuah situs web. Dalam kasus sebuah website, jumlah kunjungan dapat diperbarui, per jam, menit-bijaksana atau bahkan setiap hari. Namun masalah dalam hal ini adalah mendefinisikan sesi. Mungkin sulit untuk menentukan awal dan akhir dari sesi. Also, sulit untuk menghitung atau mengidentifikasi periode tidak aktif. So, pada kasus ini, tidak ada batas yang wajar untuk mendefinisikan sesi atau bahkan masa non-aktif. Dalam situasi seperti ini, Streaming pengolahan data secara real time diperlukan.
Summary
Meskipun Spark memiliki banyak keuntungan ketika datang ke pengolahan data batch dan masih memiliki banyak kasus penggunaan itu melayani, tampak bahwa Flink cepat mendapatkan traksi komersial. Fakta bahwa Flink juga dapat melakukan pemrosesan batch tampaknya menjadi hal besar yang mendukung. Of course, ini perlu dicatat bahwa kemampuan pemrosesan batch Flink mungkin tidak di liga yang sama seperti yang dari Spark. So, Spark masih memiliki beberapa waktu.