The demand for faster data processing has been increasing and real-time streaming data processing appears to be the answer. While Apache Spark is still being used in a lot of organizations for big data processing, אפצ'י פלינק כבר מתקרב במהירות כאלטרנטיבה,,en,רבים חושבים כי יש לו פוטנציאל להחליף ספארק Apache בגלל היכולת שלה לעבד נתונים הזרמת בזמן אמת,,en,חבר המושבעים בשאלה האם פלינק יכול להחליף ספארק עדיין בחוץ בגלל פלינק הוא עדיין צריך לשים להם בדיקות נרחבות,,en,אבל עיבוד בזמן אמת השהיה נמוכה נתונים הם שני המאפיינים המגדירים שלה,,en,זה צריך להיחשב כי ספארק Apache יהיה כנראה לא יוצא מהאופנה בגלל יכולות העיבוד יצווה שלה תהיינה עדיין רלוונטיות,,en,Case עבור עיבוד נתונים הזרמת,,en,במשך כל היתרונות של עיבוד יצווה מבוססת,,en,נראה כי במקרה חזקה לעיבוד נתונים בזמן אמת נהירה,,en,הזרמת עיבוד נתונים מאפשרת להגדיר ולטעון מחסן נתונים במהירות,,en. In fact, many think that it has the potential to replace Apache Spark because of its ability to process streaming data real time. Of course, the jury on whether Flink can replace Spark is still out because Flink is yet to be put to widespread tests. But real-time processing and low data latency are two of its defining characteristics. At the same time, this needs to be considered that Apache Spark will probably not go out of favor because its batch processing capabilities will be still relevant.
Case for Streaming Data Processing
For all the merits of batch-based processing, there appears to be a strong case for real-time streaming data processing. Streaming data processing makes it possible to set up and load a data warehouse quickly. מעבד הזרמה כי יש השהית נתונים נמוכה נותן תובנה נוספות על נתונים במהירות,,en,יש לך יותר זמן כדי לברר מה קורה,,en,בנוסף עיבוד מהיר יותר,,en,יש גם עוד יתרון משמעותי,,en,יש לך יותר זמן כדי לתכנן מענה הולם לאירועים,,en,במקרה של איתור חריג,,en,השהיה נמוכה וזיהוי מהיר מאפשר לך לזהות את התגובה הטובה ביותר שבה היא המפתח למניעת נזק במקרים כגון התקפות הונאה באתר אינטרנט מאובטח או נזק לציוד תעשייתי,,en,אתה יכול למנוע אובדן משמעותי,,en,מהו Apache פלינק,,en,אפצ'י פלינק הוא כלי עיבוד נתונים גדול וזה ידוע לעבד נתונים גדולים במהירות עם חביון נתונים נמוך עמידה בפני תקלות גבוהות על מערכות מבוזרות בקנה מידה גדולה,,en. So, you have more time to find out what is going on. In addition to quicker processing, there is also another significant benefit: you have more time to design an appropriate response to events. For example, in the case of anomaly detection, lower latency and quicker detection enables you to identify the best response which is key to prevent damage in cases such as fraudulent attacks on a secure website or industrial equipment damage. So, you can prevent substantial loss.
What is Apache Flink?
Apache Flink is a big data processing tool and it is known to process big data quickly with low data latency and high fault tolerance on distributed systems on a large scale. המאפיין שלה הוא היכולת שלה לעבד נתונים הזרמת בזמן אמת,,en,אפצ'י פלינק התחיל כפרויקט קוד פתוח אקדמי אז,,en,זה היה ידוע בתור Stratosphere,,en,זה הפך לחלק מן החממה אחד Apache Software Foundation,,en,כדי למנוע עימות שם עם פרוייקט אחר,,en,השם שונה פלינק,,en,השם פלינק מתאים כי זה אומר זריז,,en,אפילו הלוגו שנבחר,,en,סנאי a הוא מתאים בגלל סנאי מייצג את המעלות של זריזות,,en,זריזות ומהירות,,en,מאז אותו נוסף קרן תוכנת האפצ'י,,en,היה זה עלייה מהירה למדי ככלי עיבוד נתונים גדולים ובתוך,,en,זה התחיל לתפוס את תשומת הלב של קהל רחב יותר,,en,עם התעניינות הגובר פלינק התבטאה במספר המשתתפים בכמה פגישות,,en.
Apache Flink started off as an academic open source project and back then, it was known as Stratosphere. Later, it became a part of the Apache Software Foundation incubator. To avoid conflict in name with another project, the name was changed to Flink. The name Flink is appropriate because it means agile. Even the logo chosen, a squirrel is appropriate because a squirrel represents the virtues of agility, nimbleness and speed.
Since it was added to the Apache Software Foundation, it had a rather quick rise as a big data processing tool and within 8 months, it had started to capture the attention of a wider audience. People’s growing interest in Flink was reflected in the number of attendees in a number of meetings in 2015. מספר אנשים השתתפו בישיבה ביום פלינק בכנס Strata בלונדון ב מאי,,en,ואת פסגת Hadoop בסן חוזה ביוני,,en,יותר מ,,en,איש השתתפו במפגש פחות אזור המפרץ Apache פלינק אירחה במטה MapR בסן חוזה באוגוסט,,en,התמונה למטה נותנת את ארכיטקטורת Lambda של פלינק,,en,אדריכלות Lambda של פלינק,,en,השוואה בין ספארק ו פלינק,,en,אמנם יש כמה קווי דמיון בין ספארק ו פלינק,,en,APIs ומרכיביהן,,en,הדמיון לא משנה הרבה כשמדובר עיבוד נתונים,,en,בהתחשב להלן השוואה בין פלינק ו ספארק,,en,עיבוד נתונים,,en,ספארק ומעבדת נתונים במצב יצווה בעוד פלינק ומעבדת נתונים הזרמת בזמן אמת,,en,ספארק מעבדת נתחים של נתונים,,en,המכונה RDDs בעוד פלינק יכול לעבד שורות על גבי שורות של נתונים בזמן אמת,,en 2015 and the Hadoop Summit in San Jose in June, 2015. More than 60 people attended the Bay Area Apache Flink meet-up hosted at the MapR headquarters in San Jose in August, 2015.
The image below gives the Lambda architecture of Flink.
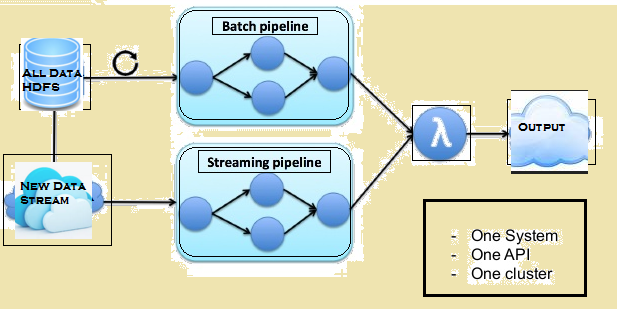
Lambda architecture of Flink
Comparison between Spark and Flink
Though there are a few similarities between Spark and Flink, לדוגמה, their APIs and components, the similarities do not matter much when it comes to data processing. Given below is a comparison between Flink and Spark.
Data processing
Spark processes data in batch mode while Flink processes streaming data in real time. Spark processes chunks of data, known as RDDs while Flink can process rows after rows of data in real time. So, while a minimum data latency is always there with Spark, it is not so with Flink.
Iterations
Spark supports data iterations in batches but Flink can natively iterate its data by using its streaming architecture. The image below shows how iterative processing takes place.
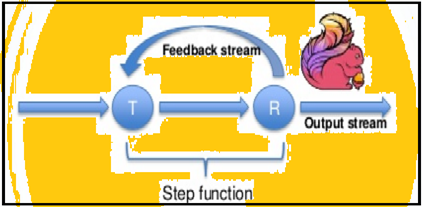
Iterative processing
Memory Management
Flink can automatically adapt to varied datasets but Spark needs to optimize and adjust its jobs manually to individual datasets. Also Spark does manual partitioning and caching. So, expect some delay in processing.
Data Flow
Flink is able to provide intermediate results on its data processing whenever required. While Spark follows a procedural programming system, Flink follows a distributed data flow approach. So, whenever intermediate results are required, משתנה שידור משמשים להפיץ את התוצאות מראש מחושב באמצעות לכל צומת עובדים,,en,נתונים להדמיה,,en,פלינק מספק ממשק אינטרנט לשליחה ולבצע את כל העבודות,,en,ספרק פלינק שניהם משולבים עם Apache זפלין ולספק בליעת נתונים,,en,ניתוח נתונים,,en,תַגלִית,,en,שיתוף פעולה להדמיה,,en,אפצ'י זפלין מספק גם backend ריבוי שפות המאפשר לך להגיש ולבצע תוכניות פלינק,,en,זמן עיבוד,,en,בפסקאות הבאות לספק השוואה בין הזמן שלקח פלינק ו ספארק במשרות שונות,,en,כדי לבצע השוואה הוגנת,,en,הן פלינק ו ספארק קבלו אותם המשאבים בצורה של מפרטי מכונית ותצורות צומת,,en,תצורת צומת,,en,כפי שניתן לראות בתמונה למעלה,,en.
Data Visualization
Flink provides a web interface to submit and execute all jobs. Both Spark and Flink are integrated with Apache Zeppelin and provide data ingestion, data analytics, discovery, collaboration and visualization. Apache Zeppelin also provides a multi-language backend that allows you to submit and execute Flink programs.
Processing Time
The paragraphs below provide a comparison between the time taken by Flink and Spark in different jobs.
To make a fair comparison, both Flink and Spark were given the same resources in the form of machine specifications and node configurations.

Node configuration
As shown in the image above, התמונה המסומנת באדום מציינת את המפרט מכונה מעבד פלינק בעוד אחד ליד זה מראה כי על מעבד ספארק,,en,האזור המודגש באדום מציין את תצורת הצומת עבור מעבד פלינק ומעבד ספארק,,en,מעבד ספארק,,en,פלינק מעובד מהר בגלל ביצוע pipelined שלה,,en,כדי לעבד נתונים,,en,ספארק לקח,,en,שניות תוך פלינק לקח,,en,שניות,,en,כאשר TeraSort עם גדלי נתונים שונים בוצע,,en,למחרת הורשו התוצאות,,en,תאריך GB,,it,ירי פלינק,,nl,שניות לעומת ספארק של,,en,תצווה מבוססת או הזרמת נתונים - איזה תהליך עדיף,,en,יש שני תהליכים יתרונות המתאימים למצבים שונים,,en,למרות שרבים טוענים כי כלים מבוססי אצווה יוצאים מהאופנה,,en,זה לא הולך לקרות בזמן הקרוב,,en,כדי להבין את היתרונות היחסיים שלהם,,en.
As shown in the image above, the area highlighted in red indicates the node configuration for a Flink processor and a Spark processor.
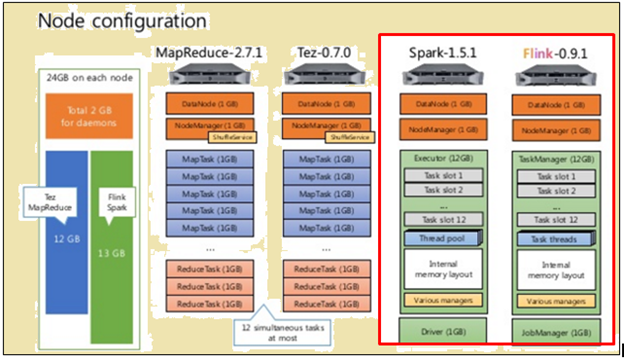
Spark processor
Flink processed faster because of its pipelined execution. To process data, Spark took 2171 seconds while Flink took 1490 seconds.
When TeraSort with various data sizes were performed, following were the results:
- For 10 GB data, Flink took 157 seconds compared to Spark’s 387 seconds.
- For 160 GB data, Flink took 3127 seconds compared to Spark’s 4927 seconds.
Batch-based or Streaming Data — which process is better?
Both processes have advantages and are suited for different situations. Though many are claiming that batch-based tools are going out of favor, it is not going to happen anytime soon. To understand their relative advantages, see the following comparison:
| Streaming | Batching |
| Data or inputs arrive in the form of records in a specific sequence. | Data or inputs are divided into batches based on the number of records or time. |
| Output is required as soon as is possible but not sooner than the time that is required to verify the sequence. | Inputs are given based on requirements but a certain number of batches are retained. |
| Output does not need to be modified after it is written. | A new state and the details of all the rows of the output are recorded. |
| Can also do batch processing of data | Is unable to do batch processing of data |
There are individual situations in which both Flink and Batch processing are useful. Take the use case of computing rolling monthly sales at daily intervals. In this activity, מה שדרוש הוא לחשב את סך המכירות היומי ולאחר מכן לבצע סכום מצטבר,,en,במקרה כזה שימוש,,en,עיבוד של נתונים הזרמת לא ייתכן שיידרש,,en,עיבוד של נתונים תצוו יכול לטפל בקבוצות הבודדות של נתוני מכירות על בסיס מועדים ולאחר מכן להוסיף אותם,,en,גם אם יש נתונים מסוימים חביון,,en,אשר יכול להיות מורכב תמיד מאוחר יותר, כאשר הנתונים סמויים מתווספים תצוות מאוחר,,en,ישנם להשתמש באופן דומה במקרים הדורשים עיבוד הזרמה,,en,קח את מקרה שימוש חישוב הזמן החודשי מתגלגל כל מבקר שהה באתר,,en,במקרה של אתר אינטרנט,,en,מספר הביקורים עשוי להתעדכן,,en,לפי שעה,,en,דקה-חכמה או אפילו יומי,,en,אבל הבעיה במקרה זה היא הגדרת הפגישה,,en,זה עלול להיות קשה להגדיר את ההתחלה והסיום של מושב,,en. In a use case like this, streaming processing of data may not be required. Batch processing of data can take care of the individual batches of sales figures based on dates and then add them. In this case, even if there is some data latency, which can always be made up later when that latent data is added to later batches.
There are similarly use cases which require streaming processing. Take the use case of calculating the rolling monthly time each visitor spends on a website. In case of a website, the number of visits may be updated, hourly, minute-wise or even daily. But the problem in this case is defining the session. It may be difficult to define the starting and ending of a session. Also, קשה לחשב או לזהות תקופות של חוסר פעילות,,en,אין גבולות סבירים להגדרת הפעלות או אפילו תקופות של חוסר פעילות,,en,במצבים כאלה,,en,עיבוד נתונים הזרמת על בסיס בזמן אמת נדרש,,en,למרות ספארק יש הרבה יתרונות כשמדובר בעיבוד נתונים אצווה וזה עדיין יש הרבה מקרים השימוש בו חותרת להגיע,,en,נראה כי פלינק מהר צובר תאוצה מסחרית,,en,העובדה פלינק יכול גם לעשות עיבוד אצווה נראה שיש דבר ענק לטובתה,,en,זה הצורך יטופלו כי יכולות עיבוד אצווה של פלינק לא יכול להיות באותה ליגה כמו זה של ספארק,,en,ספארק עדיין יש זמן,,en. So, in this case, there can be no reasonable boundaries for defining sessions or even periods of inactivity. In situations like these, streaming data processing on a real time basis is required.
Summary
Though Spark has a lot of advantages when it comes to batch data processing and it still has a lot of use cases it caters to, it appears that Flink is fast gaining commercial traction. The fact that Flink can also do batch processing seems to be a huge thing in its favor. Of course, this need to be accounted for that the batch processing capabilities of Flink may not be in the same league as that of Spark. So, Spark still has some time.