La demande pour un traitement plus rapide des données a augmenté et traitement en temps réel en continu de données semble être la réponse. Alors que Spark Apache est toujours utilisé dans un grand nombre d'organisations pour le grand traitement de données, Apache Flink a été arrive à grands pas comme une alternative. In fact, beaucoup pensent qu'il a le potentiel pour remplacer Spark Apache en raison de sa capacité à traiter des flux de données en temps réel. Of course, le jury si Flink peut remplacer Spark est encore parce que Flink doit encore être mis à des tests généralisés. Mais le traitement en temps réel et à faible latence des données sont deux de ses caractéristiques déterminantes. At the same time, cela doit être considéré que Spark Apache ne sera probablement pas sortir de faveur parce que ses capacités de traitement par lots seront toujours d'actualité.
Case pour la diffusion de traitement des données
Pour tous les mérites du traitement à base de lots, il semble y avoir un dossier solide pour traitement en temps réel des données de transmission en continu. Diffusion en traitement de données permet de configurer et de charger un entrepôt de données rapidement. Un processeur de streaming qui a une faible latence de données fournit des informations supplémentaires sur les données rapidement. So, vous avez plus de temps pour savoir ce qui se passe. Outre le traitement plus rapide, il y a aussi un autre avantage significatif: vous avez plus de temps pour concevoir une réponse appropriée aux événements. For example, dans le cas de la détection d'anomalies, une latence plus faible et la détection plus rapide vous permet d'identifier la meilleure réponse qui est la clé pour éviter des dommages dans des cas tels que les attaques frauduleuses sur un site Web sécurisé ou des dommages matériels industriels. So, vous pouvez éviter une perte substantielle.
Qu'est-ce que Apache Flink?
Apache Flink est un outil important de traitement de données et il est connu pour traiter les données rapidement grande avec une faible latence des données et haute tolérance de pannes sur les systèmes distribués à grande échelle. Sa caractéristique déterminante est sa capacité à traiter des flux de données en temps réel.
Apache Flink a commencé comme un projet open source universitaire et à l'époque, il était connu comme Stratosphere. Later, il est devenu une partie de l'incubateur Apache Software Foundation. Pour éviter les conflits de nom avec un autre projet, le nom a été changé pour Flink. Le nom Flink est approprié parce que cela signifie agile. Même le logo choisi, un écureuil est approprié, car un écureuil représente les vertus de l'agilité, prestesse et la vitesse.
Comme il a été ajouté à l'Apache Software Foundation, il y avait une augmentation assez rapide comme outil grand de traitement de données et à l'intérieur 8 months, il avait commencé à capter l'attention d'un public plus large. L'intérêt croissant de personnes en Flink se reflète dans le nombre de participants dans un certain nombre de réunions en 2015. Un certain nombre de personnes ont assisté à la réunion du Flink à la Conférence Strata à Londres en mai 2015 et le Sommet Hadoop à San Jose en Juin, 2015. Plus que 60 personnes ont assisté à la Bay Area Apache Flink meet-up hébergée au siège MapR à San Jose en Août, 2015.
L'image ci-dessous donne l'architecture Lambda de Flink.
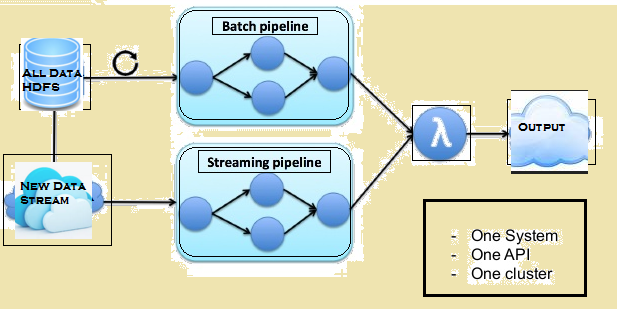
l'architecture Lambda de Flink
Comparaison entre Spark et Flink
Bien qu'il existe quelques similitudes entre Spark et Flink, par example, leurs API et composants, les similitudes ne comptent pas beaucoup quand il vient au traitement des données. Étant donné ci-dessous est une comparaison entre Flink et Spark.
Traitement de l'information
Spark traite les données en mode batch tout Flink traite les données en streaming en temps réel. Spark traite des morceaux de données, connu sous le nom RDD tout Flink peut traiter les lignes après lignes de données en temps réel. So, tandis qu'un temps de latence minimal de données est toujours là avec Spark, il est pas le cas avec Flink.
Iterations
Spark prend en charge les itérations de données par lots, mais Flink peut nativement itérer ses données en utilisant son architecture de streaming. L'image ci-dessous montre comment itérative traitement a lieu.
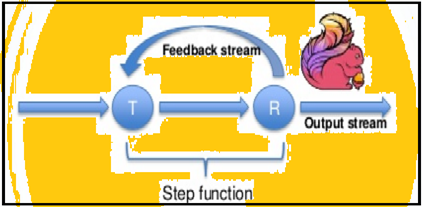
traitement itératif
Gestion de la mémoire
Flink peut adapter automatiquement aux ensembles de données variées, mais Spark a besoin d'optimiser et d'ajuster ses emplois manuellement aux ensembles de données individuels. Aussi Spark ne partitionnement manuel et la mise en cache. So, attendre un certain retard dans le traitement.
Flux de données
Flink est en mesure de fournir des résultats intermédiaires sur son traitement de données chaque fois que nécessaire. Alors que Spark suit un système de programmation procédural, Flink suit une approche de flux de données distribuées. So, chaque fois que les résultats intermédiaires sont obligatoires, les variables de diffusion sont utilisés pour distribuer les résultats calculés à l'avance par l'intermédiaire de tous les noeuds des travailleurs.
Visualisation de données
Flink fournit une interface Web pour présenter et exécuter tous les travaux. Les deux Spark et Flink sont intégrés avec Apache Zeppelin et fournissent l'ingestion de données, l'analyse de données, la découverte, la collaboration et de visualisation. Apache Zeppelin fournit également un backend multi-langue qui vous permet de soumettre et d'exécuter des programmes Flink.
Délai de traitement
Les paragraphes ci-dessous fournissent une comparaison entre le temps pris par Flink et Spark dans différents emplois.
Pour faire une comparaison équitable, à la fois Flink et Spark ont reçu les mêmes ressources sous la forme de spécifications de la machine et des configurations de noeuds.

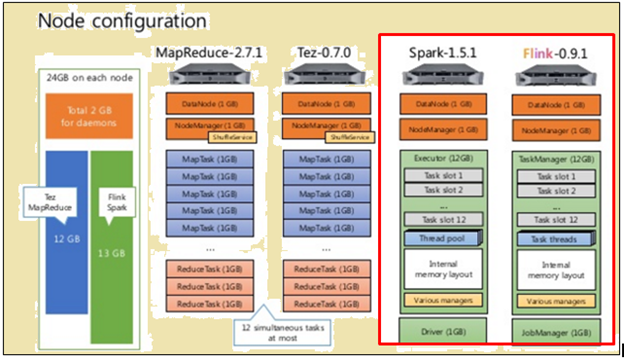
configuration de noeud
Comme cela est représenté dans l'image ci-dessus, l'image en rouge indique les spécifications de la machine pour un processeur Flink tandis que celle à côté d'elle montre que d'un processeur Spark.
Comme cela est représenté dans l'image ci-dessus, la zone en surbrillance en rouge indique la configuration du noeud pour un processeur Flink et un processeur de Spark.
processeur Spark
Flink traitée plus rapidement en raison de son exécution en pipeline. Pour traiter les données, Spark a pris 2171 secondes alors que Flink a pris 1490 secondes.
Lorsque TeraSort avec différents formats de données ont été réalisées, suivants ont été les résultats:
- Pour 10 Date GB, Flink tir 157 secondes par rapport à Spark de 387 secondes.
- Pour 160 Date GB, Flink tir 3127 secondes par rapport à Spark de 4927 secondes.
base par lots ou en données - procédé qui est mieux?
Les deux processus ont des avantages et sont adaptés à différentes situations. Bien que beaucoup prétendent que des outils batch-sont sorties de faveur, il ne va pas se produire de sitôt. Pour comprendre leurs avantages relatifs, voir la comparaison suivante:
| Diffusion | Batching |
| Les données ou les entrées arrivent sous la forme d'enregistrements dans une séquence spécifique. | Les données ou les entrées sont divisées en lots en fonction du nombre d'enregistrements ou de temps. |
| La sortie est nécessaire, dès que possible, mais pas plus tôt que le temps qui est nécessaire pour vérifier la séquence. | Les entrées sont données en fonction des besoins, mais un certain nombre de lots sont conservés. |
| Sortie n'a pas besoin d'être modifié après qu'il est écrit. | Un nouvel état et les détails de toutes les lignes de la sortie sont enregistrées. |
| Peut aussi faire le traitement des données par lots | Est incapable de faire le traitement des données par lots |
Il y a des situations individuelles dans lesquelles les deux Flink et le traitement par lots sont utiles. Prenons le cas de l'utilisation du calcul des ventes mensuelles de roulement à intervalles quotidiens. Dans cette activité,, ce qui est nécessaire est de calculer le total des ventes quotidiennes et ensuite faire une somme cumulative. Dans un cas d'utilisation de ce type, le streaming traitement des données ne peut pas être nécessaire. Le traitement par lots de données peut prendre en charge les lots individuels de chiffres de vente en fonction des dates, puis les ajouter. Dans ce cas, même s'il y a une certaine latence de données, qui peut toujours être faite plus tard, lorsque les données latente est ajouté à des lots ultérieurs.
Il existe de même des cas d'utilisation qui nécessitent un traitement en continu. Prenons le cas de l'utilisation du calcul du temps mensuel roulant chaque visiteur passe sur un site Web. Dans le cas d'un site Web, le nombre de visites peut être mis à jour, horaire, minute sage ou même tous les jours. Mais le problème dans ce cas est la définition de la session. Il peut être difficile de définir le début et la fin d'une session. Also, il est difficile de calculer ou d'identifier les périodes d'inactivité. So, dans ce cas, il peut y avoir pas de limites raisonnables pour définir des sessions ou même des périodes d'inactivité. Dans des situations comme celles-ci, traitement des données en continu sur une base en temps réel est nécessaire.
Summary
Bien que Spark a beaucoup d'avantages quand il vient au traitement des données par lots et il a encore beaucoup de cas d'utilisation, il répond à, il semble que Flink gagne rapidement la traction commerciale. Le fait que Flink peut aussi faire le traitement par lots semble être une chose énorme en sa faveur. Of course, ce besoin d'être pris en compte que les capacités de traitement par lots de Flink peuvent ne pas être dans la même ligue que celle de Spark. So, Spark a encore un peu de temps.