Die Nachfrage nach schnelleren Datenverarbeitung wurde erhöht und Echtzeit-Streaming-Datenverarbeitung scheint die Antwort zu sein. Während Apache Funke wird immer noch in vielen Organisationen für große Datenverarbeitung, Apache Flink wurde kommen schnell als Alternative. In fact, Viele denken, dass sie das Potenzial zu ersetzen Apache Funke hat wegen seiner Fähigkeit, Streaming-Daten in Echtzeit zu verarbeiten. Of course, die Jury, ob Flink Funken ersetzen kann, ist nach wie vor, weil Flink ist noch zu weit verbreiteten Tests unterzogen werden,. Aber Echtzeitverarbeitung und der geringen Datenlatenz sind zwei seiner definierende Merkmale. At the same time, dies muss berücksichtigt werden, dass Apache Spark wahrscheinlich nicht in Ungnade zu gehen, weil seine Stapelverarbeitung immer noch relevant sein werden.
Fall für Streaming-Datenverarbeitung
Für alle die Vorzüge der Batch-basierte Verarbeitung, es erscheint ein starkes Argument für die Echtzeit-Streaming-Datenverarbeitung zu sein. Streaming Datenverarbeitung ermöglicht es, einzurichten und ein Data Warehouse laden schnell. Ein Streaming-Prozessor, der geringen Datenlatenz hat gibt mehr Einblicke in die Daten schnell. So, Sie haben mehr Zeit, um herauszufinden, was los ist,. Zusätzlich zu einer schnelleren Verarbeitung, es ist auch ein weiterer bedeutender Vorteil: Sie haben mehr Zeit, eine angemessene Antwort auf Ereignisse zu entwerfen. For example, im Fall der Erkennung von Anomalien, geringere Latenzzeiten und schnellere Erkennung ermöglicht es Ihnen, die beste Antwort zu identifizieren, die Schäden in Fällen wie betrügerische Angriffe auf eine sichere Website oder industriellen Anlagen Schäden zu verhindern Schlüssel. So, Sie können erhebliche Verluste verhindern.
Was ist Apache Flink?
Apache Flink ist ein großes Datenverarbeitungswerkzeug und es bekannt ist, große Datenmengen schnell mit geringen Datenlatenz und hohe Fehlertoleranz auf verteilten Systemen in großem Maßstab zu verarbeiten. Sein Merkmal ist seine Fähigkeit, Streaming-Daten in Echtzeit zu verarbeiten.
Apache Flink begann als akademische Open-Source-Projekt aus und wieder dann, es wurde als Stratosphere bekannt. Later, es wurde ein Teil der Apache Software Foundation Inkubator. Um Konflikte zu vermeiden in Namen mit einem anderen Projekt, der Name wurde geändert Flink. Der Name Flink ist angemessen, weil es bedeutet, agil. Auch das Logo gewählt, ein Eichhörnchen ist angemessen, weil ein Eichhörnchen die Tugenden der Beweglichkeit darstellt, Gewandtheit und Schnelligkeit.
Da es wurde an die Apache Software Foundation hinzugefügt, es hatte einen ziemlich schnellen Anstieg als großen Datenverarbeitungswerkzeug und innerhalb 8 months, es hatte begonnen, die Aufmerksamkeit eines größeren Publikums zu erfassen. Volks wachsende Interesse an Flink wurde in der Anzahl der Teilnehmer in einer Reihe von Sitzungen spiegelt sich in 2015. Eine Reihe von Menschen nahmen an dem Treffen auf Flink an der Strata Conference im Mai in London 2015 und die Hadoop Summit in San Jose im Juni, 2015. Mehr als 60 Menschen nahmen an der Bay Area Apache Flink-Treffen in der Zentrale in San Jose im August MapR gehostet, 2015.
Das Bild unten zeigt die Lambda-Architektur von Flink.
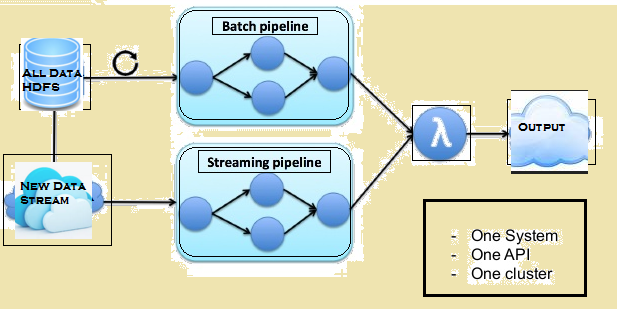
Lambda-Architektur von Flink
Vergleich zwischen Funken und Flink
Zwar gibt es einige Ähnlichkeiten zwischen Funken und Flink, beispielsweise, ihre APIs und Komponenten, die Ähnlichkeiten nicht viel Rolle, wenn es um die Datenverarbeitung kommt. Da unten ist ein Vergleich zwischen Flink und Funken.
Datenverarbeitung
Funken verarbeitet Daten im Batch-Modus, während Flink Streaming-Daten in Echtzeit verarbeitet,. Funken verarbeitet Datenblöcke, bekannt als RDDs während Flink Reihen nach Zeilen von Daten in Echtzeit verarbeiten kann,. So, während eine minimale Datenlatenz ist dort immer mit Funken, es ist nicht so mit Flink.
Iterations
Funken unterstützt Daten Iterationen in Chargen aber Flink kann nativ seine Daten iterieren durch seine Streaming-Architektur. Das Bild unten zeigt, wie iterative Verarbeitung erfolgt.
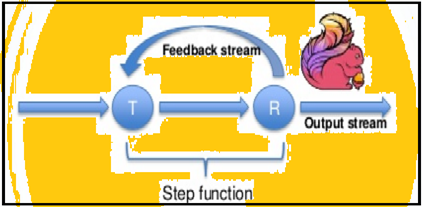
Iterative Verarbeitung
Speicherverwaltung
Flink kann variiert Datensätze automatisch anpassen aber Funken muss zu optimieren und anzupassen ihre Arbeitsplätze manuell auf einzelne Datensätze. Auch Funken macht manuelle Partitionierung und Caching. So, erwarten, dass einige Verzögerungen bei der Bearbeitung.
Datenfluss
Flink in der Lage, die Zwischenergebnisse auf der Datenverarbeitung zur Verfügung zu stellen, wann immer erforderlich. Während Funken folgt ein prozedurales Programmiersystem, Flink folgt eine verteilte Datenfluss Ansatz. So, wenn Zwischenergebnisse erforderlich, Runds Variablen werden verwendet, um die vorausberechneten Ergebnisse in allen Arbeiter Knoten zu verteilen.
Datenvisualisierung
Flink bietet eine Web-Schnittstelle zu unterbreiten, und führen Sie alle Jobs. Sowohl Funken und Flink sind mit Apache Zeppelin integriert und Daten Einnahme liefern, Datenanalyse, Entdeckung, Zusammenarbeit und Visualisierung. Apache Zeppelin bietet auch eine mehrsprachige Backend, das Ihnen erlaubt zu unterbreiten und ausführen Flink Programme.
Bearbeitungszeit
Die Absätze sollen einen Vergleich zwischen dem von Flink und Spark in verschiedenen Jobs die Zeit genommen.
Um einen fairen Vergleich, beide Flink und Funken wurden die gleichen Ressourcen in Form von Maschinenspezifikationen und Node-Konfigurationen gegeben.

Node-Konfiguration
Wie im Bild oben, das Bild rot markiert zeigt die Maschine Spezifikationen für eine Flink Prozessor, während der man daneben, dass in einer Spark-Prozessor zeigt.
Wie im Bild oben, der Bereich rot markiert zeigt die Knoten-Konfiguration für einen Flink Prozessor und einen Spark-Prozessor.
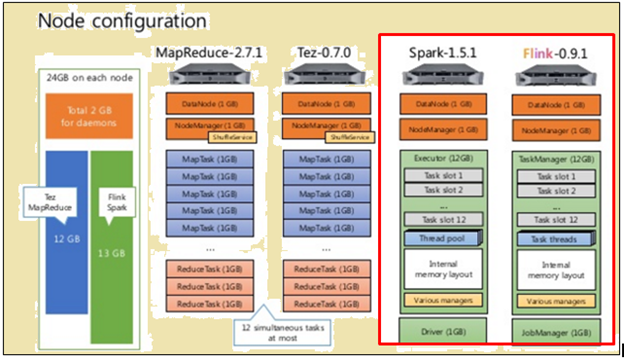
spark-Prozessor
Flink verarbeitet schneller wegen seiner Pipeline-Ausführung. Zur Verarbeitung von Daten, Funke nahm 2171 Sekunden, während Flink nahm 1490 Sekunden.
Wenn TeraSort mit verschiedenen Datengrößen wurden durchgeführt,, Nachfolgend wurden die Ergebnisse:
- Für 10 GB Datum, Flink Brennen 157 Sekunden im Vergleich der Spark 387 Sekunden.
- Für 160 GB Datum, Flink Brennen 3127 Sekunden im Vergleich der Spark 4927 Sekunden.
Batch-basierten oder mit Streaming-Daten - das Verfahren ist besser?
Beide Verfahren haben Vor- und sind für unterschiedliche Situationen geeignet. Obwohl viele sind, dass Batch-basierte Tools behauptet aus Bevorzugung gehen, es wird nicht so bald passieren. Um zu verstehen, ihre relativen Vorteile, finden Sie im folgenden Vergleich:
| Streaming | Dosiersysteme |
| Daten oder Eingaben kommen in Form von Datensätzen in einer bestimmten Reihenfolge. | Daten oder Eingaben werden in Chargen aufgeteilt basierend auf der Anzahl von Datensätzen oder Zeit. |
| Output erforderlich so schnell wie möglich ist, aber nicht früher als die Zeit, die erforderlich ist, um die Sequenz zu verifizieren. | Eingänge basieren auf Anforderungen gelten jedoch nur eine bestimmte Anzahl von Chargen werden beibehalten. |
| Ausgang muss nicht geändert werden, nachdem es geschrieben. | Ein neuer Staat und die Details aller Zeilen der Ausgabe aufgezeichnet. |
| Kann auch tun Batch-Verarbeitung von Daten | Ist nicht in der Lage die Stapelverarbeitung von Daten zu tun |
Es gibt einzelne Fälle, in denen beide Flink und Batch-Verarbeitung geeignet sind,. Nehmen Sie die Verwendung bei der Berechnung Roll monatlichen Verkäufe in täglichen Intervallen. In dieser Aktivität, was benötigt wird, ist die tägliche Gesamtumsatz zu berechnen und dann eine kumulative Summe machen. In einem Anwendungsfall wie folgt, Streaming-Verarbeitung von Daten kann nicht verlangt werden. Batch-Verarbeitung von Daten kann Pflege der einzelnen Chargen der Verkaufszahlen nehmen zu Terminen beruhen und dann hinzufügen. In diesem Fall, selbst wenn es einige Datenlatenz, was immer später nachgeholt werden, wenn die latente Daten später Chargen hinzugefügt wird.
Es werden in ähnlicher Fälle zu benutzen, die Streaming-Verarbeitung erfordern. Nehmen Sie die Verwendung bei der Roll monatlichen Zeit Berechnung jeder Besucher auf einer Website verbringt. Im Falle einer Webseite, die Anzahl der Besuche kann aktualisiert werden, stündlich, Minute weise oder sogar täglich. Aber das Problem in diesem Fall ist die Definition der Sitzungs. Es kann schwierig sein, den Beginn und das Ende einer Sitzung zu definieren. Also, es ist schwierig, die Phasen der Inaktivität zu berechnen oder zu identifizieren,. So, in diesem Fall, kann es für die Definition von Sitzungen oder auch Perioden der Inaktivität keine vernünftigen Grenzen sein. In Situationen wie diese, Streaming-Datenverarbeitung auf Echtzeitbasis erforderlich ist.
Summary
Obwohl Funken viele Vorteile hat, wenn es darum geht, Batch-Datenverarbeitung und es hat immer noch eine Menge Anwendungsfälle es bietet, es scheint, dass Flink schnell kommerziellen Zugkraft gewinnt. Die Tatsache, dass Flink können auch Batch-Verarbeitung zu tun scheint eine große Sache zu seinen Gunsten zu sein. Of course, dies muss berücksichtigt werden, dass die für die Stapelverarbeitung von Flink kann in der gleichen Liga wie der Funke nicht sein. So, Funke hat noch einige Zeit.