The demand for faster data processing has been increasing and real-time streaming data processing appears to be the answer. While Apache Spark is still being used in a lot of organizations for big data processing, Apache Flink has been coming up fast as an alternative. In fact, many think that it has the potential to replace Apache Spark because of its ability to process streaming data real time. Of course, the jury on whether Flink can replace Spark is still out because Flink is yet to be put to widespread tests. But real-time processing and low data latency are two of its defining characteristics. At the same time, this needs to be considered that Apache Spark will probably not go out of favor because its batch processing capabilities will be still relevant.
Case for Streaming Data Processing
For all the merits of batch-based processing, there appears to be a strong case for real-time streaming data processing. Streaming data processing makes it possible to set up and load a data warehouse quickly. A streaming processor that has low data latency gives more insights on data quickly. So, you have more time to find out what is going on. In addition to quicker processing, there is also another significant benefit: you have more time to design an appropriate response to events. For example, in the case of anomaly detection, lower latency and quicker detection enables you to identify the best response which is key to prevent damage in cases such as fraudulent attacks on a secure website or industrial equipment damage. So, you can prevent substantial loss.
What is Apache Flink?
Apache Flink is a big data processing tool and it is known to process big data quickly with low data latency and high fault tolerance on distributed systems on a large scale. Its defining feature is its ability to process streaming data in real time.
Apache Flink started off as an academic open source project and back then, it was known as Stratosphere. Later, it became a part of the Apache Software Foundation incubator. To avoid conflict in name with another project, the name was changed to Flink. The name Flink is appropriate because it means agile. Even the logo chosen, a squirrel is appropriate because a squirrel represents the virtues of agility, nimbleness and speed.
Since it was added to the Apache Software Foundation, it had a rather quick rise as a big data processing tool and within 8 months, it had started to capture the attention of a wider audience. People’s growing interest in Flink was reflected in the number of attendees in a number of meetings in 2015. A number of people attended the meeting on Flink at the Strata Conference in London in May 2015 and the Hadoop Summit in San Jose in June, 2015. More than 60 people attended the Bay Area Apache Flink meet-up hosted at the MapR headquarters in San Jose in August, 2015.
The image below gives the Lambda architecture of Flink.
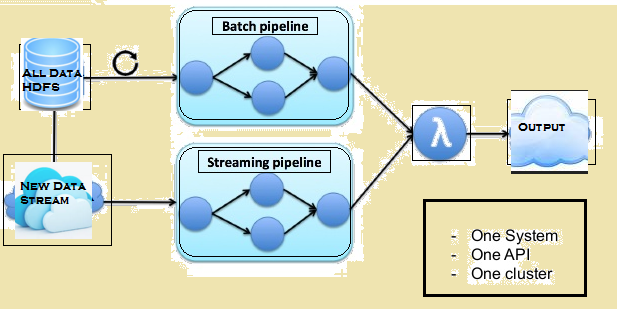
Lambda architecture of Flink
Comparison between Spark and Flink
Though there are a few similarities between Spark and Flink, for example, their APIs and components, the similarities do not matter much when it comes to data processing. Given below is a comparison between Flink and Spark.
Data processing
Spark processes data in batch mode while Flink processes streaming data in real time. Spark processes chunks of data, known as RDDs while Flink can process rows after rows of data in real time. So, while a minimum data latency is always there with Spark, it is not so with Flink.
Iterations
Spark supports data iterations in batches but Flink can natively iterate its data by using its streaming architecture. The image below shows how iterative processing takes place.
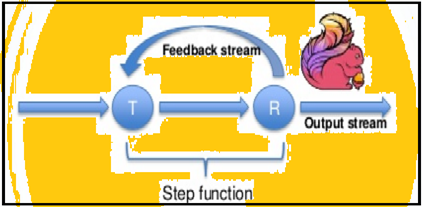
Iterative processing
Memory Management
Flink can automatically adapt to varied datasets but Spark needs to optimize and adjust its jobs manually to individual datasets. Also Spark does manual partitioning and caching. So, expect some delay in processing.
Data Flow
Flink is able to provide intermediate results on its data processing whenever required. While Spark follows a procedural programming system, Flink follows a distributed data flow approach. So, whenever intermediate results are required, broadcast variables are used to distribute the pre-calculated results through to all the worker nodes.
Data Visualization
Flink provides a web interface to submit and execute all jobs. Both Spark and Flink are integrated with Apache Zeppelin and provide data ingestion, data analytics, discovery, collaboration and visualization. Apache Zeppelin also provides a multi-language backend that allows you to submit and execute Flink programs.
Processing Time
The paragraphs below provide a comparison between the time taken by Flink and Spark in different jobs.
To make a fair comparison, both Flink and Spark were given the same resources in the form of machine specifications and node configurations.

Node configuration
As shown in the image above, the image highlighted in red indicates the machine specifications for a Flink processor while the one beside it shows that of a Spark processor.
As shown in the image above, the area highlighted in red indicates the node configuration for a Flink processor and a Spark processor.
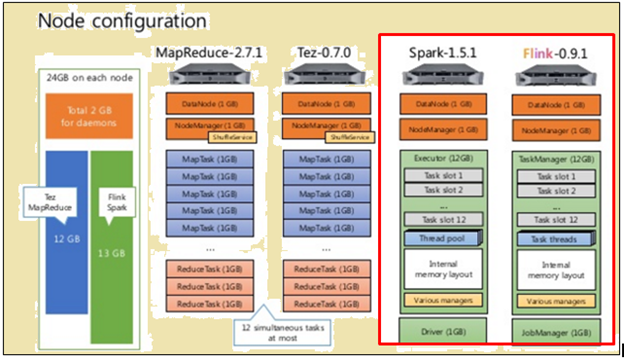
Spark processor
Flink processed faster because of its pipelined execution. To process data, Spark took 2171 seconds while Flink took 1490 seconds.
When TeraSort with various data sizes were performed, following were the results:
- For 10 GB data, Flink took 157 seconds compared to Spark’s 387 seconds.
- For 160 GB data, Flink took 3127 seconds compared to Spark’s 4927 seconds.
Batch-based or Streaming Data — which process is better?
Both processes have advantages and are suited for different situations. Though many are claiming that batch-based tools are going out of favor, it is not going to happen anytime soon. To understand their relative advantages, see the following comparison:
| Streaming | Batching |
| Data or inputs arrive in the form of records in a specific sequence. | Data or inputs are divided into batches based on the number of records or time. |
| Output is required as soon as is possible but not sooner than the time that is required to verify the sequence. | Inputs are given based on requirements but a certain number of batches are retained. |
| Output does not need to be modified after it is written. | A new state and the details of all the rows of the output are recorded. |
| Can also do batch processing of data | Is unable to do batch processing of data |
There are individual situations in which both Flink and Batch processing are useful. Take the use case of computing rolling monthly sales at daily intervals. In this activity, what is needed is to compute the daily sales total and then make a cumulative sum. In a use case like this, streaming processing of data may not be required. Batch processing of data can take care of the individual batches of sales figures based on dates and then add them. In this case, even if there is some data latency, which can always be made up later when that latent data is added to later batches.
There are similarly use cases which require streaming processing. Take the use case of calculating the rolling monthly time each visitor spends on a website. In case of a website, the number of visits may be updated, hourly, minute-wise or even daily. But the problem in this case is defining the session. It may be difficult to define the starting and ending of a session. Also, it is difficult to calculate or identify the periods of inactivity. So, in this case, there can be no reasonable boundaries for defining sessions or even periods of inactivity. In situations like these, streaming data processing on a real time basis is required.
Summary
Though Spark has a lot of advantages when it comes to batch data processing and it still has a lot of use cases it caters to, it appears that Flink is fast gaining commercial traction. The fact that Flink can also do batch processing seems to be a huge thing in its favor. Of course, this need to be accounted for that the batch processing capabilities of Flink may not be in the same league as that of Spark. So, Spark still has some time.