Përmbledhje:
Hadoop është një platformë që është pothuajse sinonim me Big Dhënave. Kjo është në thelb një kornizë me burim të hapur që lejon ruajtjen dhe përpunimin e të dhënave të grumbulluara-vë në një shkallë të madhe. kryesisht, arkitektura Hadoop është i njohur për të përbëhet nga katër module kryesore, cilat jane HDFS (Hadoop Distributed Fme SSISTEMI), Hadoop Common, fije dhe MapReduce. Secili prej këtyre moduleve është e vendosur për të kryer disa detyra të veçanta, të cilat vijnë së bashku si një e tërë për të përmbushur kërkesat e përpunimit të të dhënave. Një nga aspektet kryesore për suksesin e prodhimit është arkitektura Hadoop. Kjo arkitekturë ofron disa karakteristika kryesore që janë përgjegjës për popullaritetin e saj mbi kornizat e tjera si tani. However, ka edhe disa gjëra të tjera të marrin në konsideratë për zbatimin e suksesshëm të Hadoop. Kjo do të thotë, kjo nuk është vetëm në lidhje me të paturit e një sistemi të duhur të magazinimit të të dhënave ose 24×7 drejtimin e aplikacioneve, por edhe se si ai integron me arkitekturën e përgjithshme dhe mjeteve të një ndërmarrjeje.
Ky artikull do të diskutojë në masë të madhe të arkitekturës Hadoop në detaje bashkë me avantazhet Çdo ofron modul. Ne gjithashtu do të mbulojnë çështjet e suksesit të prodhimit.
Në vijim është një e thjeshtë Hadoop arkitekturë diagram për 2.0 Versione
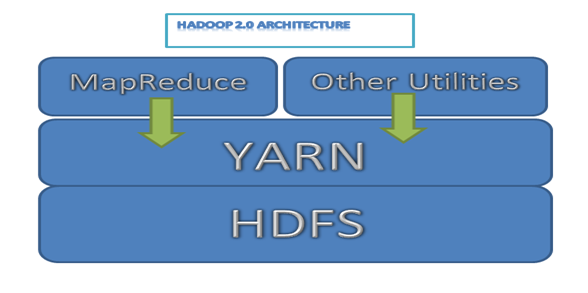
Hadoop 2.0 architecture
imazh 1: Hadoop 2.0 architecture
HDFS Architecture
Siç është përmendur tashmë, Hadoop HDFS me siguri është një nga komponentët kryesore të të gjithë kuadrit. Kjo është modul i cili është i ngarkuar me sigurimin e një të besueshme, sistem të përhershëm dhe shpërndarë magazinimit në disa nyje që janë të pranishme në një grup Hadoop.
Now, një grup zakonisht përbëhet nga disa nyjet që janë të lidhura së bashku për të formuar një sistem të plotë të skedarëve. Të gjitha të dhënave që duhet të ruhen është në thyer për herë të parë në disa chunks të vogla të njohur si blloqe. Këto blloqe janë shpërndarë më pas dhe ruhen në disa nyje të grupimit. Kjo është mënyra në të cilën është ndërtuar file sistemi Hadoop dhe ka përparësi të caktuara, si dhe.
Le të kemi një vështrim në tiparet e tjera të HDFS.
Scalable
Për shkak të pranisë së shpërndarë arkitekturës të sistemit fotografi, Harta Hadoop dhe të reduktuar funksionet punojnë si një meze. Këto funksione mund të ekzekutohet me lehtësi në subsets të vogla të të dhënave origjinale, duke ofruar scalability e madhe. Kjo është edhe një avantazh shtuar për bizneset, si ata mund të shtoni vetëm serverat linear, kur të dhënat e tyre duket të rritet.
elastik
Një aspekt tjetër shumë e dobishme për HDFS është natyra e tij shumë fleksibël në drejtim të ruajtjes së të dhënave. Duke qenë burim të hapur, Hadoop lehtë mund të kandidojë në hardware mall, e cila kursen shpenzimet jashtëzakonshme. Also, file sistemi Hadoop mund të ruajë çdo lloj të të dhënave, nëse ajo është e strukturuar, pastrukturuar, formatuar apo edhe koduar.
Hadoop edhe bën të mundur që të dhënat e pastrukturuar të jetë e vlefshme për një organizatë gjatë procesin e vendimmarrjes, diçka që ishte praktikisht i padëgjuar më parë.
i besueshëm
Sistemi Hadoop file është faji tolerant, që do të thotë se të dhënat e ruajtura në HDFS është përsëritur për një minimum dy vende të tjera. Thus, në rast se ka një kolaps i një sistemi ose dy, nuk është gjithmonë një sistem i tretë që do të ketë një kopje të të gjitha të dhënave tuaja. Sistemi pastaj mund të ndajë ngarkesën e punës në këtë vend dhe për çdo gjë që mund të punojnë normalisht.
Të paraqesë I / O
Efikasiteti i çdo file të sistemit varet se si ajo kryen operacionet I / O. në HDFS, dhënave është shtuar duke krijuar një skedar të ri dhe të shkruani të dhënat nuk. Pas kësaj, skedari është mbyllur dhe të dhënat e shkruara nuk mund të fshihet ose të ndryshohet më. Por të dhënat e reja mund të bashkangjitet duke ri-hapur dosjen. Pra, themeli bazë i HDFS është 'shkruajnë vetëm dhe të lexuar të shumta’ Model.
Vendosja Block
në HDFS, skedë është një kombinim i blloqeve të shumëfishta. Për të shtuar një bllok të ri, NameNode cakton një bllok unik id dhe shtoni atë në dosjen. Pas kësaj blloku i ri është përsëritur edhe në DataNodes shumta.
HDFS Politika bllok vendosje është configurable, kështu që përdoruesit mund të eksperimentojnë me alternativa të ndryshme për të marrë zgjidhje të optimizuar. By default, HDFS Politika block vendosja përpiqet për të minimizuar koston e shkrimit dhe maksimizuar performancën lexuar, disponueshmërinë dhe besueshmërinë. Për të zbatuar këtë, kur një bllok i ri është shtuar në një skedar, kopje e parë është vendosur në të njëjtën nyje ku shkrimtari është i pranishëm. Pas kësaj, kopje e 2 dhe 3 është i pozicionuar në dy nyje të ndryshme në një raft të veçantë. Pjesa tjetër e replicas janë vendosur rastësisht. Por kufizimi është se, një nyje nuk mund të mbajë më shumë se një kopje dhe një raft nuk mund të mbajnë më shumë se dy kopje.
Pas image tregon një rast tipik të vendosjeve kopje në një mjedis raft (siç përshkruhet në seksionin e mësipërm)
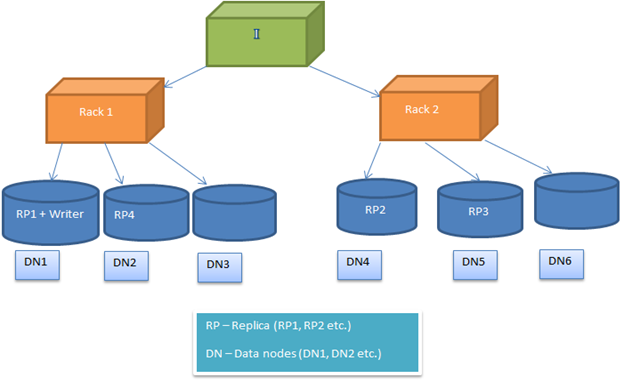
vendosja replica
Image2: Tregon vendosjen kopje në një mjedis të dy raft
Hadoop Common / Hadoop Core
Hadoop përbashkët përbëhet nga grup të përbashkët të shërbimeve për të mbështetur Hadoop arkitekturë. Këto janë në thelb TV bazë për të ndihmuar në modulet e tjera të komunikojnë me njëri-tjetrin. Ai konsiderohet gjithashtu si një pjesë e rëndësishme e arkitekturës Hadoop si HDFS, MapReduce dhe fije. Ajo siguron një abstraksion në krye të tiparet themelore thelbësore si file të sistemit, OS etj.
Infrastruktura fije
fije, ose 'dhedhe Njënother Resource Negotiator ', është modul në Hadoop që është përgjegjëse për menaxhimin e burimeve kompjuterike. Si i tillë, ajo ndan CPU ose kujtesës, bazuar në aktivitet që është në anën. Now, Fije është bërë kryesisht nga dy pjesë të mëdha - Menaxherin e Burimeve dhe Node Soccer.
- Menaxheri i Burimeve
Menaxheri i Burimeve, e cila është referuar edhe si mjeshtër, ka një prani të vetëm në një grumbull dhe shkon disa shërbime. Ajo mban gjurmët e ku punëtorët janë të vendosura dhe gjithashtu menaxhon Scheduler Burimeve, e cila cakton burimet.
- nyja Menaxher
Nyjen Menaxheri ndodh të jetë punëtor i infrastrukturës dhe mund të ketë shumë prej tyre në një grup Hadoop. Secila nga këto Menaxherët Nyja ofrojnë burime për grup. kapaciteti i saj i burimeve matet ne formen e memories dhe vcores (pjesa e CPU cores). Menaxheri i Burimeve përdor burimet nga Node Menaxher, kur ajo ka nevojë për të drejtuar një detyrë.
Hadoop fije ka disa aspekte shumë të dobishme që e bëjnë atë një pjesë e rëndësishme e arkitekturës. Këto janë përshkruar në mënyrë të detajuar.
Multi-qiramarrjes
Një nga përparësitë më të mëdha Hadoop fije është se ajo mbështet menaxhimin e burimeve dinamike. Pavarësisht ndarjes së burimeve të të njëjtit grup, ajo është e aftë për drejtimin e motorëve të shumta dhe ngarkesën e punës. And, ashtu si HDFS, Fije është gjithashtu shumë të shkallëzuar, e cila ofron aftësive masive caktimin, pa marrë parasysh se çfarë mund të jetë ngarkesa e punës.
Fuqia
Hadoop fije ofron Fuqia, e cila ju lejon për të hapur deri të dhënat tuaja në një shumëllojshmëri e mjeteve dhe teknologjive që mund të ju ndihmojë të merrni më të mirë nga përpunimit të të dhënave. Ekosistemi i saj është i instalimit për të plotësuar nevojat e zhvilluesve të ndryshme dhe gjithashtu organizatat e shkallës vogla dhe të mëdha.
In fact, Hadoop për momentin vjen me disa projekte të njohura të tilla si Hive, MapReduce, Zookeeper, HBase, HCatalog, dhe shumë më tepër. Also, si tregu për Hadoop vazhdon zgjerimin, Mjete të reja janë shtuar në këtë pikë çdo ditë.
Në vijim është një tipik fije arkitekturë diagram.
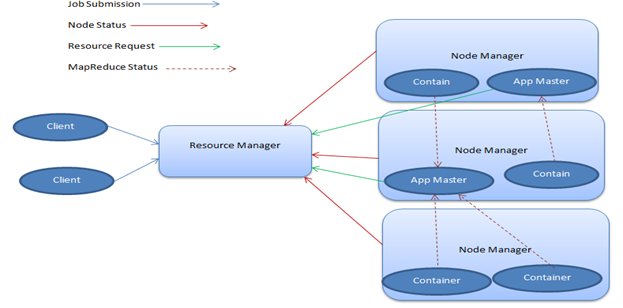
Fije Architecture diagram
Image3: Fije Architecture diagram
Korniza MapReduce
MapReduce është e thënë të jetë zemra e sistemit Hadoop. Kjo është korniza e programimit që lejon shkrimin e aplikacioneve për përpunimin paralel të mëdha të të dhënave-vë në dispozicion të gjithë qindra apo mijëra serverat e disa në një grup Hadoop.
Ideja themelore prapa saj të punës është hartimi dhe reduktimin e detyrave. Funksioni Map është përgjegjës për filtrimin dhe zgjidhja e të dhënave, ndërsa Ulja funksioni kryen operacione të caktuara përmbledhëse. MapReduce gjithashtu vjen me pjesën e saj të drejtë të aspekteve të rëndësishme që ndihmojnë në arritjen e suksesit të prodhimit, cilat jane
lakueshmëri
MapReduce mund të përpunojnë të dhënat e të gjitha llojeve, nëse ajo është e strukturuar, gjysmë-strukturuar apo të pastrukturuara. Kjo është një nga aspektet kryesore që e bëjnë atë një pjesë e rëndësishme e të gjithë arkitekturës Hadoop.
Qasja
Një gamë të gjerë të gjuhëve është mbështetur nga MapReduce, e cila lejon zhvilluesve për të punuar të qetë. In fact, MapReduce siguron mbështetje për Java, Python dhe C , dhe edhe për gjuhë të nivelit të lartë të tilla si Apache Pig dhe Hive.
Scalability
Duke qenë një pjesë integrale e arkitekturës Hadoop, MapReduce është projektuar në mënyrë të përkryer në një mënyrë që përputhet nivelet masive scalability ofruara nga HDFS. Kjo siguron përpunimin e të pakufizuar të dhënave, të gjithë nën një platformë të plotë.
Si komponentët Hadoop siguruar suksesin e prodhimit?
Në një mjedis të prodhimit, scalability është një nga kriteret kryesore për suksesin e biznesit. sepse, nëse kërkesa nuk mund të shkallës (e cila shkon në HDFS) gjatë orëve të pikut, atëherë ajo nuk do të jetë në gjendje për të mbështetur rritjen e numrit të konsumatorëve. Si rezultat i biznesit do të humbasin para. So, nga pikëpamja arkitektonike e parë është shumë e rëndësishme që të ketë shkallëzuar magazinimit dhe të përpunimit të aftësive, të cilat Hadoop mund të sigurojë me sistemin e saj të shpërndarë fotografi (HDFS).
HDFS tjera karakteristika si fleksibilitet për të mbështetur çdo lloj të të dhënave; seriozitet (faji tolerant) në rast të një kolapsi të sistemit gjithashtu shton vlerë një mjedis të prodhimit. File I / O dhe bllok vendosja është gjithashtu e rëndësishme si ajo e mbështet menaxhimin e të dhënave shumë efikase në një mjedis grumbulli. Pra, ne mund të konkludojmë se suksesi prodhimi i çdo kërkesë Hadoop majorly varet nga vetë arkitekturën HDFS.
Në një grup tipik i 4000 nodes, ne mund të kemi rreth 65 milion fotografi dhe 80 milion blloqe. Çdo bllok është që 3 kopje, kështu që çdo nyje do të ketë 60,000 blloqe. Ky është një rast tipik të Yahoo menaxhimin e të dhënave. Pra, ajo i jep një ide fare në lidhje me mjedisin grumbulluara dhe ruajtjen e të dhënave.
Arkitektura fije siguron një menaxhim efikas të burimeve që është fut në Hadoop 2.0 architecture. Ajo siguron menaxhimin e duhur të burimeve në mjedis të prodhimit.
Përveç nga komponentët, programimit MapReduce ndihmon në përpunimin paralel të të dhënave në një mjedis të shpërndarë. Pra, një përpunim më të shpejtë është arritur në sistemin e prodhimit për të mbështetur kërkesat e botës reale.
Përfundim
Ajo është e njohur mirë se Big Data është vendosur të dominojnë herë që vijnë në përpunimin e të dhënave, dhe me ekosistemin Hadoop është lulëzuar për momentin, ajo pritet të jetë në krye në domenin. Pothuajse të gjitha mjetet e të dhënave të bazuara janë duke e bërë rrugën e tyre me Hadoop, me qëllim për t'iu kundërvënë sfidave të pritshme për t'u përballur në të ardhmen e afërt. Arkitektura Hadoop është ndërtuar për të menaxhuar këto vëllime të mëdha të të dhënave në një mjedis të shpërndarë. Secila dhe çdo komponent i platformës Hadoop është bërë për të trajtuar lloje të veçanta të funksioneve. So, si një e tërë ajo siguron suksesin e prodhimit të çdo aplikim bigdata. But we also need to remember that the associated bigdata technologies also play an important role in application deployment and its success in real life scenarios.