Ikhtisar:
Hadoop adalah platform yang hampir identik dengan Big Data. Hal ini pada dasarnya adalah sebuah kerangka kerja open source yang memungkinkan penyimpanan dan pengolahan berkerumun data-set dalam skala besar. terutama, arsitektur Hadoop diketahui terdiri dari empat modul utama, yang mana HDF (Hadoop Distributed Fdengan System), Hadoop Common, YARN dan MapReduce. Masing-masing modul ini diatur untuk melakukan tugas-tugas spesifik tertentu, yang datang bersama-sama secara keseluruhan untuk memenuhi kebutuhan pengolahan data. Salah satu aspek kunci keberhasilan produksi adalah arsitektur Hadoop. Arsitektur ini menawarkan beberapa fitur utama yang bertanggung jawab untuk popularitas lebih kerangka kerja lainnya seperti yang sekarang. However, ada juga beberapa hal lain yang perlu dipertimbangkan untuk keberhasilan pelaksanaan Hadoop. Ini berarti, ini bukan hanya tentang memiliki sistem penyimpanan yang tepat dari catatan atau 24×7 menjalankan aplikasi, tetapi juga bagaimana hal tersebut terintegrasi dengan keseluruhan arsitektur dan alat-alat dari suatu perusahaan.
Artikel ini sebagian besar akan membahas arsitektur Hadoop secara rinci bersama dengan keunggulan masing-masing modul penawaran. Kami juga akan mencakup isu-isu keberhasilan produksi.
Berikut ini adalah Hadoop diagram arsitektur sederhana untuk 2.0 versi
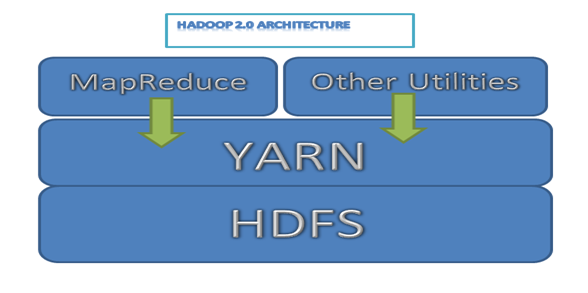
Hadoop 2.0 architecture
Image 1: Hadoop 2.0 architecture
HDFS Architecture
Seperti disebutkan sudah, Hadoop HDFS pasti adalah salah satu komponen kunci dari seluruh kerangka. Ini adalah modul yang bertugas memberikan handal, sistem penyimpanan permanen dan didistribusikan di beberapa node yang hadir dalam cluster Hadoop.
Now, cluster biasanya terdiri dari beberapa node yang dihubungkan bersama untuk membentuk satu sistem file lengkap. Semua data yang perlu disimpan pada awalnya dipecah menjadi beberapa potongan kecil yang dikenal sebagai blok. Blok ini kemudian didistribusikan dan disimpan di beberapa node cluster. Ini adalah cara di mana sistem file Hadoop dibangun dan memiliki kelebihan tertentu juga.
Mari kita lihat pada fitur lain dari HDFS.
Scalable
Karena kehadiran didistribusikan arsitektur sistem file, peta Hadoop dan mengurangi fungsi bekerja seperti angin. Fungsi-fungsi ini dapat dengan mudah dijalankan pada subset kecil dari data asli, sehingga menawarkan skalabilitas yang luar biasa. Ini juga merupakan keuntungan tambahan untuk bisnis, karena mereka hanya dapat menambahkan server linear, ketika data mereka tampaknya tumbuh.
Fleksibel
Aspek lain yang sangat menguntungkan dari HDFS adalah sifat yang sangat fleksibel dalam hal penyimpanan data. Menjadi open source, Hadoop dapat dengan mudah berjalan pada perangkat keras komoditas, yang menghemat biaya sangat. Also, sistem file Hadoop dapat menyimpan segala jenis data, apakah itu terstruktur, terstruktur, diformat atau bahkan dikodekan.
Hadoop bahkan memungkinkan untuk data tidak terstruktur untuk menjadi berharga untuk sebuah organisasi selama proses pengambilan keputusan, sesuatu yang praktis tidak pernah terdengar sebelumnya.
terpercaya
Sistem file Hadoop adalah kesalahan toleran, yang berarti bahwa data yang disimpan dalam HDFS direplikasi ke minimal dua lokasi lainnya. Thus, dalam hal ada runtuhnya sistem atau dua, selalu ada sistem ketiga yang akan memiliki salinan dari semua data Anda. Sistem ini kemudian dapat mengalokasikan beban kerja ke lokasi ini dan segala sesuatu dapat bekerja secara normal.
Berkas I / O
Efisiensi sistem file tergantung pada bagaimana ia melakukan operasi I / O. dalam HDFS, Data ditambahkan dengan membuat file baru dan menulis data ada. Sesudah ini, file tersebut tertutup dan data tertulis tidak dapat dihapus atau diubah lagi. Namun data baru dapat ditambahkan dengan membuka kembali file tersebut. Jadi fondasi dasar dari HDFS adalah 'Satu tulis dan beberapa membaca’ model.
blok Penempatan
dalam HDFS, file adalah kombinasi dari beberapa blok. Untuk menambahkan blok baru, NameNode memberikan blok id unik dan menambahkannya ke file. Setelah ini blok baru juga direplikasi di beberapa DataNodes.
HDFS kebijakan penempatan blok dikonfigurasi, sehingga pengguna dapat bereksperimen dengan berbagai alternatif untuk mendapatkan solusi optimal. By default, HDFS kebijakan penempatan blok mencoba untuk meminimalkan biaya menulis dan memaksimalkan performa membaca, ketersediaan dan kehandalan. Untuk melaksanakan ini, ketika sebuah blok baru ditambahkan ke file, replika pertama ditempatkan pada node yang sama di mana penulis hadir. Sesudah ini, replika 2 dan 3 diposisikan pada dua node yang berbeda di rak yang terpisah. Sekarang sisa replika ditempatkan secara acak. Namun larangan tersebut adalah bahwa, satu node tidak bisa menyimpan lebih dari satu replika dan satu rak tidak dapat menyimpan lebih dari dua replika.
Berikut gambar menunjukkan kasus khas penempatan replika di lingkungan rak (seperti yang dijelaskan di bagian atas)
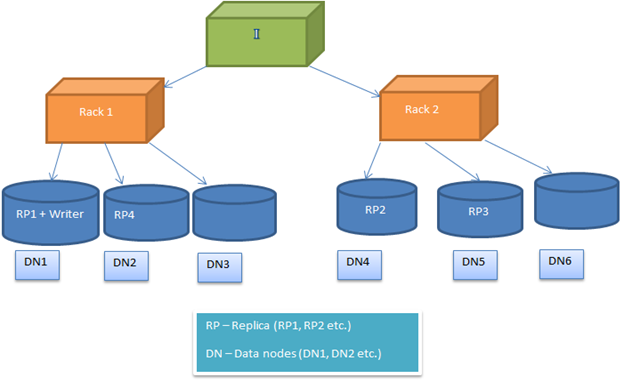
penempatan replika
Image2: Menunjukkan penempatan replika di lingkungan dua rak
Hadoop Umum / Hadoop Inti
Hadoop umum terdiri dari seperangkat utilitas untuk mendukung arsitektur Hadoop. Ini pada dasarnya API dasar untuk membantu modul lain berkomunikasi satu sama lain. Hal ini juga dianggap sebagai bagian penting dari arsitektur Hadoop seperti HDFS, MapReduce dan BENANG. Ini memberikan abstraksi di atas fitur inti yang mendasari seperti sistem file, OS dll.
BENANG Infrastruktur
YARN, atau 'Yet Another Resource Negotiator ', adalah modul dalam Hadoop yang bertanggung jawab untuk pengelolaan sumber daya komputasi. Dengan demikian, itu mengalokasikan CPU atau memori, berdasarkan tugas yang di tangan. Now, BENANG terutama terdiri dari dua bagian utama - Manajer Sumber Daya dan Node Manajer.
- Resource Manager
The Resource Manager, yang juga disebut sebagai master, memiliki kehadiran tunggal dalam sebuah cluster dan menjalankan beberapa layanan. Ini melacak di mana para pekerja berada dan juga mengelola Scheduler Sumber Daya, yang memberikan sumber.
- Node Manager
Node Manajer terjadi menjadi pekerja infrastruktur dan mungkin ada banyak dari mereka di cluster Hadoop. Setiap Manajer Node ini menawarkan sumber daya untuk cluster. Kapasitasnya sumber daya diukur dalam bentuk memori dan vcores (share core CPU). The Resource Manager memanfaatkan sumber daya dari Node Manajer, saat dibutuhkan untuk menjalankan tugas.
Hadoop BENANG memiliki aspek yang sangat menguntungkan tertentu yang membuat bagian penting dari arsitektur. Ini telah dijelaskan secara rinci.
Multi-tenancy
Salah satu keuntungan terbesar Hadoop BENANG adalah bahwa ia mendukung pengelolaan sumber daya dinamis. Meskipun berbagi sumber daya dari cluster yang sama, ia mampu menjalankan beberapa mesin dan beban kerja. And, seperti HDFS, BENANG juga sangat scalable, yang menawarkan kemampuan penjadwalan besar, tidak peduli apa beban kerja mungkin.
kesegaran
Hadoop BENANG menawarkan ketahanan, yang memungkinkan Anda untuk membuka data ke berbagai alat dan teknologi yang dapat membantu Anda mendapatkan yang terbaik dari pengolahan data. ekosistemnya adalah setup dengan baik untuk memenuhi kebutuhan berbagai pengembang dan juga organisasi skala kecil dan besar.
In fact, Hadoop saat ini dilengkapi dengan beberapa proyek terkenal seperti Hive, MapReduce, Zookeeper, HBase, HCatalog, dan lebih banyak. Also, sebagai pasar untuk Hadoop terus memperluas, alat baru ditambahkan untuk menghitung ini setiap hari.
Berikut ini adalah diagram arsitektur BENANG khas.
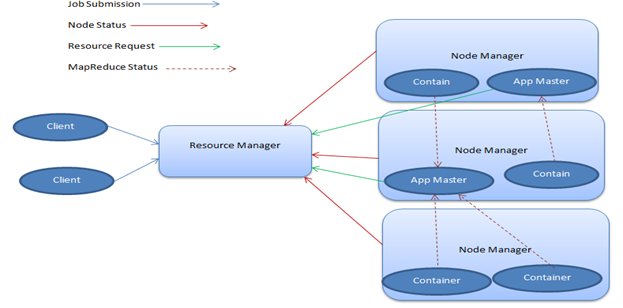
diagram BENANG Arsitektur
Image3: diagram BENANG Arsitektur
Kerangka MapReduce
MapReduce dikatakan menjadi jantung dari sistem Hadoop. Ini adalah kerangka pemrograman yang memungkinkan untuk menulis aplikasi untuk pemrosesan paralel besar data set yang tersedia di beberapa ratusan atau ribuan server dalam cluster Hadoop.
Ide dasar di balik kerja adalah pemetaan dan mengurangi tugas. Fungsi Peta bertanggung jawab untuk penyaringan dan pemilahan data, sedangkan Mengurangi fungsi melakukan operasi Ringkasan tertentu. MapReduce terlalu tiba dengan adil dari aspek penting yang membantu dalam mencapai kesuksesan produksi, yang mana
keluwesan
MapReduce dapat mengolah data dari semua jenis, apakah itu terstruktur, semi-terstruktur atau tidak terstruktur. Ini adalah salah satu aspek kunci yang membuat bagian penting dari seluruh arsitektur Hadoop.
aksesibilitas
Berbagai bahasa didukung oleh MapReduce, yang memungkinkan pengembang untuk bekerja dengan nyaman. In fact, MapReduce memberikan dukungan untuk Java, Python dan C , dan juga untuk bahasa tingkat tinggi seperti Apache Babi dan Hive.
Scalability
Menjadi bagian integral dari arsitektur Hadoop, MapReduce telah dirancang dengan sempurna dengan cara yang cocok dengan tingkat skalabilitas besar yang ditawarkan oleh HDFS. Hal ini memastikan pengolahan data unlimited, semua di bawah satu platform lengkap.
Bagaimana komponen Hadoop memastikan keberhasilan produksi?
Dalam lingkungan produksi, skalabilitas merupakan salah satu kriteria utama bagi keberhasilan bisnis. Karena, jika aplikasi tidak dapat skala (yang berjalan pada HDFS) saat jam sibuk, maka tidak akan dapat mendukung peningkatan jumlah pelanggan. Akibatnya bisnis akan kehilangan uang. So, dari sudut pandang arsitektur sangat penting untuk memiliki penyimpanan dan pengolahan scalable kemampuan, yang Hadoop dapat memberikan dengan sistem file terdistribusi (HDF).
The HDFS fitur lain seperti fleksibilitas untuk mendukung semua jenis data; keandalan (kesalahan toleran) dalam kasus runtuhnya sistem juga menambah nilai ke lingkungan produksi. File I / O dan penempatan blok juga penting karena mendukung manajemen data sangat efisien dalam lingkungan cluster. Jadi dapat disimpulkan bahwa keberhasilan produksi aplikasi Hadoop majorly tergantung pada arsitektur HDFS sendiri.
Dalam cluster khas 4000 node, kita bisa memiliki sekitar 65 juta file dan 80 juta blok. Setiap blok memiliki 3 replika, sehingga setiap node akan memiliki 60,000 blok. Ini adalah kasus yang khas di manajemen data Yahoo. Sehingga memberikan ide ongkos tentang lingkungan berkerumun dan penyimpanan data.
arsitektur BENANG menyediakan manajemen sumber daya yang efisien yang memperkenalkan di Hadoop 2.0 architecture. Ini memastikan pengelolaan sumber daya yang tepat dalam lingkungan produksi.
Terlepas dari komponen, pemrograman MapReduce membantu dalam pemrosesan paralel data dalam lingkungan terdistribusi. Jadi proses lebih cepat dicapai dalam sistem produksi untuk mendukung tuntutan dunia nyata.
Kesimpulan
Hal ini juga diketahui bahwa Big Data akan mendominasi masa mendatang dalam pengolahan data, dan dengan ekosistem Hadoop itu berkembang pada saat ini, itu juga diharapkan menjadi pelopor dalam domain. Hampir semua alat berbasis data membuat jalan mereka dengan Hadoop, dalam rangka untuk melawan tantangan diharapkan akan dihadapi dalam waktu dekat. Arsitektur Hadoop dibangun untuk mengelola volume besar data dalam lingkungan terdistribusi. Setiap komponen platform Hadoop dibuat untuk menangani jenis tertentu dari fungsi. So, secara keseluruhan menjamin keberhasilan produksi aplikasi bigdata. But we also need to remember that the associated bigdata technologies also play an important role in application deployment and its success in real life scenarios.