סקירה:
Hadoop היא פלטפורמה היא כמעט שם נרדף Big Data. זהו בעצם מסגרת קוד פתוח המאפשר אחסון ועיבוד של סטים-נתונים מקובצים בקנה מידה גדול. בְּרֹאשׁ וּבְרִאשׁוֹנָה, ארכיטקטורת Hadoop ידועה מהווה של ארבעה מודולים מרכזיים, שהם HDFS (Hadoop Distributed Fעם System), Common Hadoop, חוּט ו - MapReduce. כל אחד המודולים הללו מוגדר לבצע משימות מסוימות, אשר מגיע יחד כמכלול כדי לעמוד בדרישות עיבוד נתונים. אחד היבטי מפתח להצלחת ייצור הוא אדריכלות Hadoop. ארכיטקטורה זו מציעה תכונות עיקריות מספר כי הם אחראים הפופולריים שלו לאורך במסגרות אחרות נכון לעכשיו. However, יש גם כמה דברים אחרים לשקול עבור היישום המוצלח של Hadoop. זה אומר, זה לא רק על בעל מערכת אחסון נכון של רשומות או 24×7 ריצה של יישומים, אלא גם איך זה משתלב עם הארכיטקטורה וכלים הכוללות של מיזם.
מאמר זה יהיה בעיקר לדון אדריכלות Hadoop בפירוט יחד עם היתרונות כל הצעות מודול. כמו כן, אנו נכסה בעיות הצלחת ייצור.
להלן תרשים אדריכלות Hadoop פשוט 2.0 גרסאות
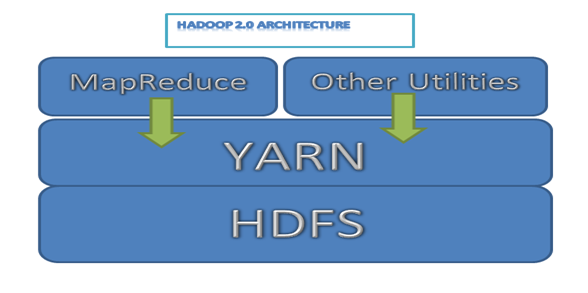
Hadoop 2.0 architecture
תמונה 1: Hadoop 2.0 architecture
אדריכלות HDFS
כפי שכבר הוזכר, Hadoop HDFS בוודאי הוא אחד ממרכיבי המפתח של המסגרת כולה. זהו מודול שמתפקידה לספק אמין, מערכת אחסון קבועה ומופצת על פני מספר צומת שנמצאים באשכול Hadoop.
Now, אשכול בדרך כלל מורכב מכמה צומת שמקושרים יחד וליצור מערכת קבצים מלאה. כל הנתונים שצריך להיות מאוחסן על הנשבר הראשון לקוביות מספר קטנות המכונות בלוקים. בלוקים אלה מופצים אז ומאוחסן על פני מספר צמתים של האשכול. זהו האופן שבו מערכת הקבצים Hadoop בנוי ויש לה יתרונות מסוימים, כמו גם.
הבה נעיף מבט על תכונות אחרות של HDFS.
Scalable
בשל נוכחותם של ארכיטקטורת מערכת קבצים מבוזרת, פונקציות המפה ולהפחית של Hadoop לעבוד כמו בריזה. ניתן פונקציות אלה להורג בקלות על תת קטן של הנתונים המקוריים, ובכך מציע יכולת הרחבה עצומה. זהו גם יתרון נוסף עבור עסקים, כפי שהם רק יכולים להוסיף שרתים באופן ליניארי, כאשר הנתונים שלהם נראים לגדול.
גָמִישׁ
היבט נוסף יתרון מאוד של HDFS הוא האופי הגמיש ביותר שלה מבחינת האחסון של נתונים. להיות קוד פתוח, Hadoop יכול בקלות לרוץ על החומרה, אשר חוסך עלויות מאוד. Also, מערכת הקבצים Hadoop יכול לאחסן כל סוג של נתונים, אם הוא מובנה, לא מובן, מעוצב או אפילו מקודד.
Hadoop אפילו עושה את זה אפשרי עבור נתונים לא מובנים כדי להיות בעל ערך לארגון במהלך תהליך קבלת החלטות, משהו היה חסר תקדים כמעט של לפני.
אָמִין
מערכת הקבצים Hadoop הוא אשם סובלני, כלומר הנתונים המאוחסנים HDFS משוכפל למינימום שני מיקומים אחרים. כָּך, במקרה שיש קריסה של מערכת או שתיים, תמיד יש מערכת שלישית כי תצטרך עותק של כל הנתונים שלך. המערכת יכולה ואז מחלק עומסי עבודה למיקום זה והכל יכול לעבוד כרגיל.
קובץ I / O
היעילות של כל מערכת קבצים תלויה איך היא מבצעת את פעולות I / O. בשנת HDFS, נתונים מתווספים על ידי יצירת קובץ חדש ולכתוב את הנתונים שם. אחרי זה, התיק נסגר והנתונים הכתובים שלא ניתן למחוק או לשנות עוד. אבל ניתן לצרף נתונים חדשים על ידי לפתוח מחדש את הקובץ. אז היסוד הבסיסי של HDFS הוא "כתיבה יחידה ורבים קוראים מרובה’ דֶגֶם.
מיקום בלוק
בשנת HDFS, קובץ הוא שילוב של בלוקים מרובים. להוספת בלוק חדש, NameNode מקצה id בלוק ייחודי ולהוסיף אותו לקובץ. אחרי זה הבלוק החדש משוכפל גם DataNodes המרובה.
מדיניות חסימת מיקום HDFS להגדרה, כך שמשתמש יכול להתנסות עם חלופות שונות כדי לקבל פתרונות אופטימיזציה. כברירת מחדל, מדיניות מיקום בלוק HDFS מנסה למזער את עלות הכתיבה ולמקסם את הביצועים לקריאה, זמינות ואמינות. כדי ליישם את זה, כאשר בלוק חדש מתווסף קובץ, העתיק הראשון מושם על אותו הצומת שבו הכותב הוא הווה. אחרי זה, העתק ה -2 וה -3 ממוקם על שני הצמתים השונים מתלה נפרד. עכשיו שאר העותקים המשוכפלים מונחים בצורה אקראית. אבל ההגבלה היא כי, אחד צומת לא יכול לשמור יותר העתק אחד מתלה אחד לא יכול לשמור יותר משני העתקים.
בעקבות תמונה מראה מקרה טיפוסי של מיקומים העתק בסביבה מתל (כמתואר לעיל, בסעיף)
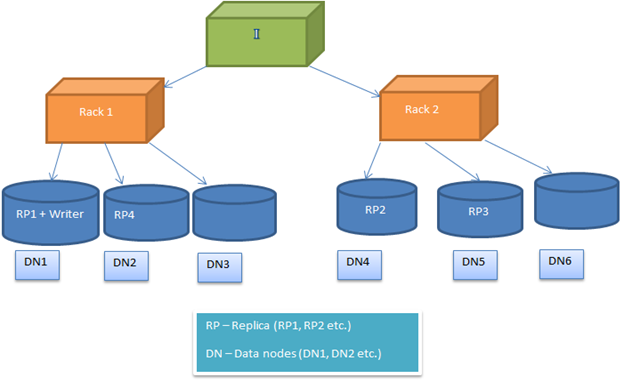
מיקום העתק
Image2: מציג מיקום העתק בסביבה מתל שני
Hadoop נפוצה / Hadoop Core
המשותף Hadoop מורכב סט של כלי עזר משותף לתמוך אדריכלות Hadoop. אלה הם בעצם APIs בסיס לעזור מודולים אחרים לתקשר אחד עם השני. הוא נחשב גם כחלק חשוב של אדריכלות Hadoop כמו HDFS, MapReduce וחוטים. הוא מספק הפשטה על גבי תכונות ליבה הבסיסיות כמו מערכת קבצים, OS וכו '.
תשתיות חוט
חוּט, או 'וו Another Resource Negotiator ', המודול נמצא Hadoop כי הוא אחראי על ניהול משאבי חישובית. ככזה, הוא מקצה מעבדים או זיכרון, מבוסס על עצמו את המשימה כי הוא בהישג יד. Now, חוט מורכב בעיקר משני חלקים מרכזיים - מנהל משאבים ואת מנהל Node.
- מנהל משאבים
מנהל המשאבים, גם אשר נקרא כמאסטר, יש נוכחות אחת באשכול ומפעיל שירותי מספר. היא עוקבת אחר שבו העובדים ממוקמים וגם מנהלת את מתזמן המשאבים, מקצת משאבים.
- מנהל node
מנהל צומת קורה להיות עובד של תשתית וייתכנו רבים מהם באשכול Hadoop. כל מנהלי צומת האלה להציע משאבים לאשכול. הקיבולת של משאביו נמדדה בצורה של זיכרון vcores (חלקם של ליבות CPU). מנהל משאבי מנצל משאבי ממנהל Node, כאשר היא צריכה לרוץ משימה.
יש Hadoop חוט היבטים יתרון מאוד מסוימים זה עושה את זה חלק חשוב של האדריכלות. אלה היו מתוארים בפירוט.
ריבוי משתמשים
אחד היתרונות הגדולים ביותר של Hadoop החוט הוא שזה תומך בניהול משאבים דינמי. למרות שיתוף המשאבים של אותו האשכול, היא מסוגלת לרוץ מנועים ועומסי עבודה מרובים. And, בדיוק כמו HDFS, חוט הוא גם מדרגית, אשר מציע יכולות תזמון מסיביות, לא משנה מה את עומס העבודה יכולה להיות.
חוסן
Hadoop החוט מציע חוסן, אשר מאפשר לך לפתוח את הנתונים שלך למגוון של כלים וטכנולוגיות שיכולים לעזור לך להפיק את המיטב של עיבוד נתונים. המערכת האקולוגית שלה היא התקנה היטב כדי לענות על הצרכים של יזמים שונים וגם ארגונים בקנה מידה קטנה וגדול.
In fact, Hadoop כיום מגיע עם מספר פרויקטים ידועים כגון כוורת, MapReduce, Zookeeper, HBase, HCatalog, והרבה יותר. Also, כמו בשוק Hadoop הולך ומתרחב, כלים חדשים מתווספים בספירה זו כל יום.
להלן תרשים אדריכלות חוט טיפוסי.
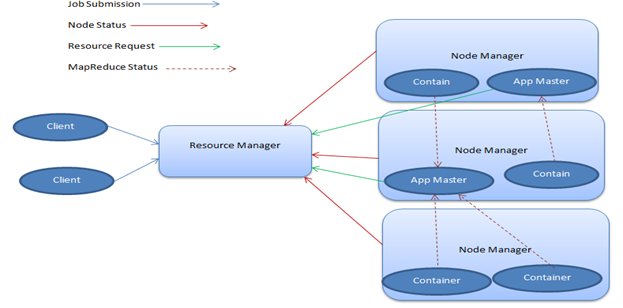
אדריכלות דיאגרמה חוט
Image3: אדריכלות דיאגרמה חוט
מסגרת MapReduce
MapReduce הוא אמר להיות בלב מערכת Hadoop. זוהי מסגרת התכנות המאפשרת כתיבת בקשות עיבוד מקביל של ערכות נתונים גדולות זמינות על פני כמה מאה או אלף שרתים באשכול Hadoop.
הרעיון הבסיסי שמאחורי העבודה שלה הוא המיפוי והצמצום של משימות. הפונקציה מפת אחראי סינון ומיון של נתונים, בעוד הפונקציה להפחית מבצעת פעולות סיכום מסוימות. MapReduce מגיע מדי עם נתח הוגן של היבטים חשובים המסייעים להשגת הצלחה הייצור, שהם
גְמִישׁוּת
MapReduce יכול לעבד נתונים מכל הסוגים, אם הוא מובנה, מובנים למחצה או בלתי מובנים. זהו אחד מן ההיבטים המרכזיים שהופכים אותו חלק חשוב של אדריכלות Hadoop כולו.
נְגִישׁוּת
קיים מגוון רחב של שפות נתמך על ידי MapReduce, מתיר למפתחים לעבוד בנוחות. In fact, MapReduce מספק תמיכה עבור Java, Python ו- C , וגם עבור שפות ברמה גבוהה כגון Apache חזיר ו כוורת.
Scalability
להיות חלק בלתי נפרד של אדריכלות Hadoop, MapReduce תוכנן בצורה מושלמת, באופן שהוא תואם את רמות יכולת ההרחבה המסיביות שמציעות HDFS. הדבר מבטיח עיבוד נתונים ללא הגבלה, הכל תחת פלטפורמה אחת שלמה.
איך Hadoop רכיבים להבטיח הצלחת ייצור?
בסביבת ייצור, מדרגיות היא אחד הקריטריונים העיקריים להצלחה עסקית. כי, אם הבקשה הבינלאומית לא יכול בהיקף (אשר פועל על HDFS) בשעות שיא, אז זה לא יהיה מסוגל לתמוך מספר גדל והולך של לקוחות. כתוצאה מכך העסק יפסיד כסף. So, מנקודת המבט אדריכלית חשוב מאוד להיות בעל יכולות אחסון ועיבוד מדרגים, אשר Hadoop יכול לספק עם מערכת קבצים מבוזרת שלה (HDFS).
HDFS האחר תכונות כמו גמישות לתמיכה כל סוג של נתונים; אֲמִינוּת (עמיד בפני תקלות) במקרה של קריסת מערכת מוסיפה ערך גם בסביבת ייצור. קובץ קלט / פלט ושם לחסום חשוב גם כפי שהוא תומך בניהול נתונים מאוד ביעילות בסביבת אשכולות. אז אנו יכולים להסיק כי הצלחת הייצור של כל יישום Hadoop תלוי majorly על אדריכלות HDFS עצמו.
באשכול אופייני 4000 nodes, אנחנו יכולים להיות סביב 65 מיליון קבצים 80 מיליון בלוקים. כל גוש הוא נתקל 3 העתקים, כך כל צומת יצטרך 60,000 בלוקים. זהו מקרה טיפוסי בבית וניהול נתונים יאהו. אז זה נותן רעיון הנסיעה על הסביבה התקבצו ואחסון נתונים.
אדריכלות חוט מספקת ניהול משאבים יעיל המהווה מציג ב Hadoop 2.0 architecture. זה מבטיח ניהול משאבים נכון בסביבת ייצור.
מלבד הרכיבים, תכנות MapReduce מסייע עיבוד מקביל של נתונים בסביבת מבוזרת. אז עיבוד מהיר יותר מושגת במערכת הייצור כדי לתמוך בדרישות בעולם האמיתי.
מסקנה
עובדה ידועה היא כי Big Data מוגדר להשתלט על פי הקרובה בעיבוד נתונים, ועם המערכת האקולוגית Hadoop הוא משגשג כיום, גם הוא צפוי להיות המועמד המוביל בתחום. כמעט כל כלים מבוססי נתונים עושים את דרכם עם Hadoop, על מנת להתמודד עם האתגרים הצפויים לו להיות מתמודד בעתיד הקרוב. אדריכלות Hadoop בנויה לנהל כמויות ענקיות אלה של נתונים בסביבת מבוזרת. כל מרכיב ומרכיב של פלטפורמת Hadoop הוא עשה כדי להתמודד עם סוגים ספציפיים של פונקציות. So, ככלל היא מבטיחה הצלחה הייצור של כל יישום bigdata. אבל אנחנו גם צריכים לזכור כי טכנולוגיות bigdata הקשורות גם לשחק תפקיד חשוב פריסת יישומים והצלחתה בתרחישים בחיים אמיתיים.