Overzicht: We zijn ons terdege bewust van de kenmerken van Hadoop en HDFS. In dit document zullen we praten over de HDFS federatie, die ons helpt om een bestaande HDFS architectuur te verbeteren. Het zorgt voor een duidelijke scheiding tussen namespace en opslag maakt dus schaalbaarheid en isolatie op clusterniveau.
Introductie: Hadoop federatie scheidt de namespace laag en opslaglaag. Het stelt het blok opslaglaag. Het breidt ook de architectuur van een bestaande HDFS cluster om nieuwe implementaties en use cases. De huidige HDFS architectuur bestaat uit twee lagen -
- namespace - Deze laag beheert bestanden, directories en blokkeert. Deze laag ondersteunt de basis-bestandssysteem operaties bijv. notering van bestanden, creatie van dossiers, modificatie van bestanden en verwijderen van bestanden en mappen.
- Block Storage - Deze laag bestaat uit twee delen -
- blok beheer Dit beheert de datanodes in het cluster en biedt operaties zoals creatie, schrapping, modificatie en zoeken. Het zorgt ook voor het beheer van replicatie.
- fysieke opslag Dit slaat de blokken en biedt toegang voor lezen of schrijven operaties.
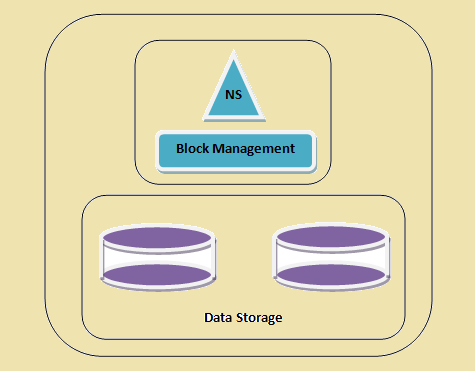
Een HDFS cluster
Figure 1: Een HDFS cluster
In de huidige HDFS architectuur, we hebben maar één namespace voor de hele cluster, die wordt beheerd door een enkele naam van het knooppunt. Met deze aanpak wordt het gemakkelijker om de HDFS cluster implementeren. Deze gelaagdheid van de architectuur werkt prima voor kleinere opstellingen terwijl het voor grotere organisaties, waar een enorme hoeveelheid gegevens moet de zorg worden genomen met een hoge afdruksnelheid, bijv. Yahoo en Facebook is gebleken dat deze aanpak heeft een aantal beperkingen die worden behandeld door de Hadoop federatie. Zodat Hadoop federatie kan worden gedefinieerd als de geavanceerde architectuur om de beperkingen van de huidige HDFS uitvoering overwinnen.
Laten we de beperkingen te controleren zoals hieronder uiteengezet -
- Nauw gekoppeld Block Storage en Namespace - In de huidige architectuur van de blok opslag en de Namespace zijn nauw verbonden die de alternatieve implementaties van naam knooppunten uitdagend maakt en beperkt andere diensten aan het blok opslag direct te gebruiken.
- Namespace Schaalbaarheid - De HDFS cluster schalen horizontaal door het toevoegen van datanodes maar we kunnen niet meer namespace horizontaal toe te voegen aan een bestaande cluster. We kunnen namespace verticaal te schalen op een enkele namenode. De namenode slaat het volledige bestandssysteem metadata binnen zijn geheugen dat het aantal blokken beperkt, bestanden en mappen moeten worden ondersteund op het bestandssysteem dat moet worden ondergebracht in het geheugen van de interne namenode.
- performance - Het huidige bestand werking van het systeem zijn beperkt tot de doorvoer van een enkele naam van het knooppunt die op dit moment steunen 60000 gelijktijdige taken. Maar de nieuwe komende kaart brengen van Apache zal een ondersteuning voor meer dan 100000 gelijktijdige taken en zal dus meerdere knooppunten vereisen.
- isolatie - In het algemeen zijn de HDFS implementaties op een multi-tenant omgeving waarin een cluster wordt gedeeld door meerdere organisaties. In deze opstelling een afzonderlijke naamruimte is niet mogelijk voor een toepassing of een organisatie.
HDFS Federation:
Hadoop federatie maakt het schalen van de naam van de dienst horizontaal. Het gebruikt verscheidene namenodes of naamruimten die onafhankelijk van elkaar. Dit zijn onafhankelijke namenodes federated d.w.z. zij vereisen inter coördinatie. Deze datanodes worden gebruikt als gezamenlijke opslag door alle namenodes. Elke datanode is geregistreerd bij alle namenodes in het cluster. Deze datanodes sturen periodieke verslagen en reageert op de commando's van de naam nodes. We hebben een blok zwembad dat is een verzameling van blokken die behoren tot een enkele namespace. In een cluster, de datanodes winkels blokken voor het blok zwembaden. Elk blok zwembad is onafhankelijk beheerd. Dit maakt het mogelijk de naam ruimte om blok ids voor nieuwe blokken te genereren zonder medeweten van andere namespaces. Als men namenode of andere reden mislukt, de datanode blijft op het bedienen van andere namenodes.
Een namespace en het blok worden gezamenlijk genoemd namespace Volume. Wanneer een namespace of een namenode wordt verwijderd de corresponderende blok zwembad bij de datanode wordt automatisch verwijderd. In het proces van cluster up-gradatie, elke naamruimte volume wordt bijgewerkt als eenheid.
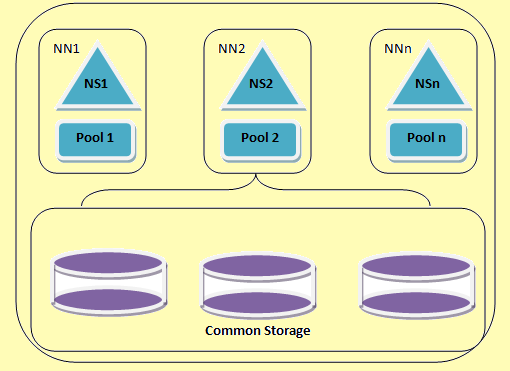
Een HDFS federatie architectuur
Figure 2: Een HDFS federatie architectuur
Voordelen van Hadoop Federation:
Hadoop federatie komt met een aantal voordelen en de voordelen die zijn opgenomen als onder -
- Schaalbaarheid en isolatie - Meerdere namenodes schalen horizontaal in het bestandssysteem namespace. Deze scheidt eigenlijk namespace volumes voor de gebruikers en categorieën van toepassing en biedt een absolute isolatie.
- Generieke Storage Service - Blokniveau zwembad abstractie maakt de architectuur van nieuwe bestand systemen te bouwen op de top van blokopslag. We kunnen gemakkelijk nieuwe toepassingen op het blok opslag laag te bouwen zonder gebruik te maken van het bestandssysteem-interface. Aangepaste categorieën blok zwembad kan ook worden gebouwd, die afwijken van de standaard blok zwembad zijn.
- Eenvoudig Ontwerp - Namenodes en namespaces zijn onafhankelijk van elkaar. Er is nauwelijks een scenario dat vergt het veranderen van de bestaande naam nodes. Elke naam van het knooppunt is gebouwd robuust te zijn. Federatie is ook achterwaarts compatibel. Het kan eenvoudig worden geïntegreerd met de bestaande enkele knoop implementaties die werken zonder enige wijzigingen in de configuratie.
een HDFS Federation configureren:
Configuratie van Hadoop Federatie ontworpen zodanig dat alle knooppunten in het cluster dezelfde configuratie. De configuratie wordt uitgevoerd in de volgende stappen worden uitgevoerd -
- Step 1 - De volgende parameters moet worden toegevoegd in de bestaande configuratie -
- nameservices - Dit wordt geconfigureerd met een lijst met door komma's gescheiden NameServiceIDs. Deze parameter wordt gebruikt door Datanodes om alle namenodes in de cluster te bepalen.
- Step 2 - De volgende configuraties moet als suffix de bijbehorende naam service-ID in het gemeenschappelijk configuratiebestand.
- Namenode
- Secondary NameNode
- BackupNode
Een voorbeeld configuratiebestand voor twee namenodes is hieronder weergegeven -
Listing 1: Een voorbeeld configuratiebestand voor twee knooppunten
[Code]
<configuratie>
<eigendom>
<naam>dfs.nameservices</naam>
<waarde>ns1, ns2</waarde>
</eigendom>
<eigendom>
<naam>dfs.namenode.rpc-address.ns1</naam>
<waarde>nn-host1:6600</waarde>
</eigendom>
<eigendom>
<naam>dfs.namenode.http-address.ns1</naam>
<waarde>nn-host1:8080</waarde>
</eigendom>
<eigendom>
<naam>dfs.namenode.secondaryhttp-address.ns1</naam>
<waarde>NHS-host1:8080</waarde>
</eigendom>
<eigendom>
<naam>dfs.namenode.rpc-address.ns2</naam>
<waarde>nn-host2:6600</waarde>
</eigendom>
<eigendom>
<naam>dfs.namenode.http-address.ns2</naam>
<waarde>nn-host2:8080</waarde>
</eigendom>
<eigendom>
<naam>dfs.namenode.secondaryhttp-address.ns2</naam>
<waarde>NHS-host2:8080</waarde>
</eigendom>
</configuratie>
[/Code]
Het formatteren van de Namenode: Laten we de commando's voor het opmaken van namenode.
- Step 1 – Een enkele naam van het knooppunt kunnen worden geformatteerd met behulp van de volgende -
$HADOOP_USER_HOME / bin / HDFS namenode -formaat [-ClusterID <cluster_id>]
Het cluster id moet uniek zijn en mag niet in strijd zijn met andere spannende cluster id. Indien geen, een unieke cluster id gegenereerd bij de opmaak.
- Step 2 - Extra namenode kunnen worden geformatteerd met de volgende opdracht -
$HADOOP_PREFIX_HOME / bin / HDFS namenode -formaat -clusterId <cluster_id>
Het is van belang dat de hier vermelde cluster id steeds gelijk aan die in de genoemde moet stap 1. Als deze twee verschillend, de extra namenode niet het deel van de Federale cluster.
Het starten en stoppen van de cluster: Laten we eerst controleren de opdrachten voor het starten en stoppen van de cluster.
- Start de cluster - Het cluster kan worden gestart door het volgende commando -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
- Stop de cluster - Het cluster kan worden gestopt door het volgende commando -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
Een nieuwe namenode aan een bestaande cluster: We hebben al beschreven dat meerdere naam van het knooppunt is in het hart van Hadoop federatie. Het is dus belangrijk om de stappen om nieuwe naam nodes toe te voegen en te schalen horizontaal te begrijpen.
De volgende stappen zijn nodig om nieuwe namenodes toe te voegen -
- De configuratie parameter - nameservices te worden ingevoegd in de configuratie.
- NameServiceID dient als suffix in de configuratie
- Nieuwe Namenode betrekking tot config moet worden toegevoegd in de configuratiebestanden.
- Het configuratiebestand worden gepropageerd naar alle knooppunten in het cluster.
- Start het nieuwe namenode en de secundaire namenode
- Vernieuw de andere datanodes om de nieuw toegevoegde namenode halen door de volgende opdracht -
o $HADOOP_PREFIX_HOME/bin/hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
- Het bovenstaande commando moet worden uitgevoerd tegen alle datanodes op het cluster.
Summary: HDFS federatie is ingevoerd om de beperkingen van eerdere HDFS implementatie overwinnen. Het toevoegen van schaalbaarheid bij de namespace laag is het belangrijkste kenmerk van HDFS federatie architectuur. Maar HDFS federatie is ook achterwaarts compatibel, dus de enige namenode configuratie zal ook werken zonder wijzigingen.
Laat ons samen te vatten onze discussie in de vorm van volgende kogels
- HDFS federatie scheidt de namenode layer en de opslaglaag.
- HDFS federatie is ontworpen om de beperkingen van de enkele knoop HDFS architectuur te overwinnen waar de opslag kan opschalen horizontaal niet de namespace.
- HDFS federatie komt met de volgende voordelen -
- Isolatie
- Scalability
- eenvoudig Ontwerp
- HDFS configuratie is zeer eenvoudig en is ook gemakkelijk te beheren.