მიმოხილვა: ჩვენ კარგად ვიცით, თვისებები Hadoop და HDFS. ამ დოკუმენტში, ჩვენ ვსაუბრობთ HDFS ფედერაცია, რომელიც გვეხმარება, რათა გაზარდოს არსებული HDFS არქიტექტურა. ის უზრუნველყოფს მკაფიო გამიჯვნა სახელთა სივრცე და შენახვის ამით საშუალებას scalability და იზოლაციის კასეტური დონე.
შესავალი: Hadoop ფედერაცია ჰყოფს namespace ფენა და შენახვის ფენის. ეს საშუალებას აძლევს ბლოკი შენახვის ფენის. იგი ასევე აფართოებს არქიტექტურა არსებული HDFS კასეტური დაუშვას ახალი შესრულება და გამოყენების შემთხვევაში. მიმდინარე HDFS არქიტექტურის ორი ფენა -
- სახელთა სივრცე - ეს ფენა მართავს ფაილი, საიტები და ბლოკავს. ეს ფენა მხარს უჭერს ძირითადი ფაილური სისტემის ოპერაციებს, მაგ. ჩამონათვალი ფაილი, შექმნა ფაილი, მოდიფიკაცია ფაილი და წაშლა ფაილები და ფოლდერები.
- ბლოკი შენახვის - ეს ფენა აქვს ორ ნაწილად -
- Block მენეჯმენტი ეს მართავს datanodes კასეტური და უზრუნველყოფს ოპერაციების როგორც შექმნა, წაშლა, ცვლილების და ძიება. იგი ასევე ზრუნავს რეპლიკაცია მართვის.
- ფიზიკური შენახვის ინახავს ბლოკები და უზრუნველყოფს ხელმისაწვდომობის წაკითხვის ან ჩაწერის ოპერაციების.
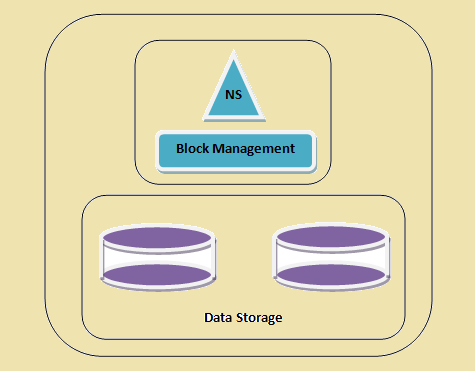
HDFS კასეტური
Figure 1: HDFS კასეტური
მიმდინარე HDFS არქიტექტურა, ჩვენ მხოლოდ ერთი სივრცე მთელი კასეტური რომელიც მართავს ერთი სახელი კვანძის. ამ მეთოდით ხდება უფრო ადვილად განახორციელონ HDFS კასეტური. ეს layering არქიტექტურის მუშაობს ჯარიმა პატარა რეგულაციისთვის ხოლო ამისთვის დიდი ორგანიზაციებთან, სადაც დიდი მოცულობის მონაცემები უნდა იქნას მიღებული ზრუნვა სწრაფი სიჩქარე, მაგ. yahoo და Facebook აღმოჩნდა, რომ ეს მიდგომა აქვს გარკვეული შეზღუდვები, რომლებიც სიფრთხილით მიერ Hadoop ფედერაცია. ასე რომ, Hadoop ფედერაცია შეიძლება განისაზღვროს, როგორც მოწინავე არქიტექტურის დაძლიოს შეზღუდვები მიმდინარე HDFS განხორციელების.
მოდით შეამოწმეთ შეზღუდვები როგორც ქვემოთ -
- მაგრად რასაც ბლოკი შენახვის და სახელთა სივრცე - მიმდინარე არქიტექტურის ბლოკი შენახვისა და სახელთა სივრცე მჭიდროდ რასაც რაც ალტერნატიული შესრულება სახელი კვანძების რთული და ზღუდავს სხვა მომსახურების გამოყენება ბლოკი შენახვის პირდაპირ.
- სახელთა სივრცე Scalability - HDFS კასეტური სასწორები ჰორიზონტალურად დასძინა datanodes მაგრამ ჩვენ არ შეგვიძლია დაამატოთ მეტი namespace არსებული კასეტური ჰორიზონტალურად. ჩვენ შეგვიძლია გავაფართოვოთ namespace ვერტიკალურად ერთ namenode. Namenode ინახავს სრული ფაილური სისტემა მეტადატის მის ხსოვნას, რომელიც ზღუდავს რაოდენობა ბლოკები, ფაილების და დირექტორიების მხარდაჭერა ფაილური სისტემა, რომელიც უნდა შესახლებულ მეხსიერებაში ერთი namenode.
- შესრულება - მიმდინარე ფაილის სისტემის ოპერაციების მხოლოდ გამტარუნარიანობა ერთი სახელი კვანძის რომელიც დღესდღეობით მხარს უჭერს 60000 კონკურენტმა ამოცანები. მაგრამ ახალი მოდის რუკა შემცირების Apache ექნება მხარდაჭერა უფრო მეტია, ვიდრე 100000 კონკურენტმა ამოცანები და, შესაბამისად, მოითხოვს მრავალი კვანძების.
- იზოლაცია - ზოგადად, HDFS განლაგდებიან ხელმისაწვდომია მრავალ tenant გარემო, სადაც ერთი კასეტური იზიარებენ სხვადასხვა ორგანიზაციებთან. ამ setup ცალკე namespace არ არის გამორიცხული, ერთ განაცხადს და ერთი ორგანიზაცია.
HDFS ფედერაცია:
Hadoop ფედერაცია საშუალებას სკალირების სახელი მომსახურება ჰორიზონტალურად. იგი იყენებს რამდენიმე namenodes და სახელთა რომლებიც დამოუკიდებელია ერთმანეთისგან. ეს არის დამოუკიდებელი namenodes ფედერალური i.e. ისინი არ საჭიროებს inter კოორდინაცია. ეს datanodes გამოიყენება როგორც საერთო შენახვის ყველა namenodes. თითოეული datanode რეგისტრირებულია ყველა namenodes კასეტური. ეს datanodes პერიოდული ანგარიშები და პასუხობს ბრძანებები სახელი კვანძების. ბლოკი აუზი, რომელიც არის კომპლექტი ბლოკები, რომ მიეკუთვნება ერთ სახელთა სივრცე. კასეტური, datanodes მაღაზიები ბლოკები ყველა ბლოკი აუზი. თითოეული ბლოკი აუზი შეძლო დამოუკიდებლად. ეს საშუალებას სახელი ფართი წარმოქმნის ბლოკი პირადობის მოწმობა ახალი ბლოკები ინფორმირების გარეშე სხვა სახელთა. თუ რომელიმე namenode ვერ ნებისმიერი მიზეზით, datanode ინარჩუნებს ემსახურება სხვა namenodes.
ერთი სახელთა სივრცე და მისი ბლოკის ერთობლივად მოუწოდა სახელთა სივრცე მოცულობა. როდესაც სახელთა ან namenode ამოღებულია შესაბამისი ბლოკი აუზი datanode ამოღებულია ავტომატურად. პროცესში კასეტური up გრადაცია, თითოეულ namespace მოცულობა განახლებული როგორც ერთეული.
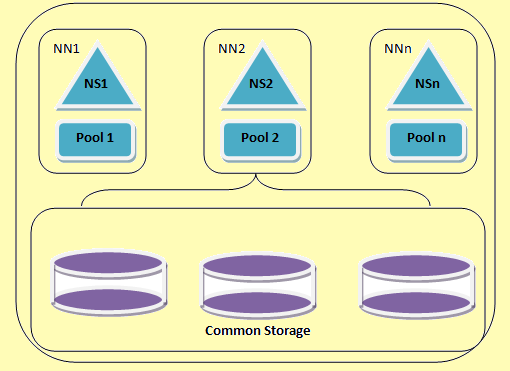
HDFS ფედერაცია არქიტექტურა
Figure 2: HDFS ფედერაცია არქიტექტურა
უპირატესობები Hadoop ფედერაცია:
Hadoop ფედერაცია მოდის გარკვეული უპირატესობა და სარგებელი, რომელიც ჩამოთვლილია როგორც ქვეშ -
- Scalability და იზოლაცია - მრავალჯერადი namenodes ჰორიზონტალურად სასწორები მდე ფაილური სისტემა namespace. ეს რეალურად ჰყოფს namespace ტომი წევრებს და კატეგორიის პროგრამა და უზრუნველყოფს აბსოლუტურ იზოლაციაში.
- Generic შენახვის სამსახურის - ბლოკი დონეზე აუზი აბსტრაქცია საშუალებას არქიტექტურის ავაშენოთ ახალი ფაილური სისტემების თავზე ბლოკი შენახვის. ჩვენ შეგვიძლია ადვილად ააშენოს ახალი პროგრამები ბლოკი შენახვის ფენის გარეშე გამოყენებით ფაილი სისტემის ინტერფეისი. ადრინდელს კატეგორია ბლოკი აუზი ასევე შეიძლება აშენდა, რომლებიც განსხვავდება საწყისი ბლოკი აუზი.
- მარტივი დიზაინი - Namenodes და სახელთა დამოუკიდებელი ერთმანეთს. არ არსებობს ისეთი გარემოება, რომელიც მოითხოვს შეცვლას სახელი კვანძების. თითოეული სახელი კვანძის აგებული უნდა იყოს ძლიერი. ფედერაცია უკან თავსებადი. იგი ადვილად აერთიანებს არსებული ერთი კვანძის განლაგდებიან, რომელიც მუშაობს ყოველგვარი კონფიგურაციის ცვლილებების.
კონფიგურირებას HDFS ფედერაცია:
კონფიგურაცია Hadoop ფედერაციის შექმნილია ისე, რომ ყველა კვანძების კასეტური აქვს იგივე კონფიგურაციის. კონფიგურაციის ხორციელდება შემდეგი ნაბიჯები -
- Step 1 - შემდეგი პარამეტრების უნდა იყოს დამატებული არსებული კონფიგურაცია -
- nameservices - ეს არის კონფიგურირებული სია მძიმით გამოყოფილი NameServiceIDs. ეს პარამეტრი გამოიყენება Datanodes, რათა დადგინდეს ყველა namenodes კასეტური.
- Step 2 - შემდეგი კონფიგურაციის საჭიროებს დაზუსტებას მფლობელის suffixed შესაბამის სახელი მომსახურების ID ერთიან კონფიგურაციის ფაილი.
- Namenode
- Secondary NameNode
- BackupNode
ნიმუში კონფიგურაციის ფაილი ორ namenodes არის ნაჩვენები ქვემოთ -
Listing 1: ნიმუში კონფიგურაციის ფაილი ორ კვანძების
[Code]
<კონფიგურაციის>
<ქონების>
<სახელი>dfs.nameservices</სახელი>
<ღირებულება>ns1, ns2</ღირებულება>
</ქონების>
<ქონების>
<სახელი>dfs.namenode.rpc-address.ns1</სახელი>
<ღირებულება>nn-host1:6600</ღირებულება>
</ქონების>
<ქონების>
<სახელი>dfs.namenode.http-address.ns1</სახელი>
<ღირებულება>nn-host1:8080</ღირებულება>
</ქონების>
<ქონების>
<სახელი>dfs.namenode.secondaryhttp-address.ns1</სახელი>
<ღირებულება>NHS-host1:8080</ღირებულება>
</ქონების>
<ქონების>
<სახელი>dfs.namenode.rpc-address.ns2</სახელი>
<ღირებულება>nn-host2:6600</ღირებულება>
</ქონების>
<ქონების>
<სახელი>dfs.namenode.http-address.ns2</სახელი>
<ღირებულება>nn-host2:8080</ღირებულება>
</ქონების>
<ქონების>
<სახელი>dfs.namenode.secondaryhttp-address.ns2</სახელი>
<ღირებულება>NHS-host2:8080</ღირებულება>
</ქონების>
</კონფიგურაციის>
[/Code]
ფორმატირება Namenode: მოდით ბრძანებას ფორმატი namenode.
- Step 1 – ერთი სახელი კვანძის შეიძლება ფორმატის გამოყენებით შემდეგ -
$HADOOP_USER_HOME / bin / HDFS namenode -format [-clusterId <cluster_id>]
კასეტური id უნდა იყოს უნიკალური და არ უნდა ეწინააღმდეგებოდეს ნებისმიერი სხვა არსებული კასეტური id. თუ არ არის გათვალისწინებული, უნიკალური კასეტური id გამომუშავებული დროს გაფორმებით.
- Step 2 - დამატებითი namenode შეიძლება ფორმატის გამოყენებით ბრძანება -
$HADOOP_PREFIX_HOME / bin / HDFS namenode -format -clusterId <cluster_id>
მნიშვნელოვანია, რომ აქ კასეტური id აღინიშნოს უნდა იყოს იგივე, რომ აღნიშნული ნაბიჯი 1. თუ ამ ორი სხვადასხვა, დამატებითი namenode არ იქნება ნაწილი ფედერალური კასეტური.
დაწყების და შეჩერების კასეტური: მოდით შეამოწმეთ ბრძანებები დაიწყოს და შეწყვიტოს კასეტური.
- დაწყება კასეტური - კასეტური შეიძლება დაიწყო შესრულებაში შემდეგი ბრძანება -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
- შეაჩერე კასეტური - კასეტური შეიძლება გააჩერა შესრულებაში შემდეგი ბრძანება -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
დამატება ახალი namenode არსებული კასეტური: ჩვენ უკვე აღწერილი, რომ მრავალი სახელი კვანძის გულში Hadoop ფედერაცია. ასე რომ, ეს მნიშვნელოვანია იმის გაგება, ნაბიჯები, რათა ახალი სახელი კვანძების და მასშტაბის ჰორიზონტალურად.
შემდეგი ნაბიჯები საჭირო, რათა ახალი namenodes -
- კონფიგურაციის პარამეტრი - nameservices უნდა იყოს დამატებული კონფიგურაციის.
- NameServiceID უნდა suffixed კონფიგურაციის
- New Namenode დაკავშირებული config უნდა დაემატოს ამ კონფიგურაციის ფაილი.
- კონფიგურაციის ფაილი უნდა გავრცელდა ყველა კვანძების კასეტური.
- დაიწყოს ახალი namenode და საშუალო namenode
- ამოცნობა სხვა datanodes აირჩიოთ ახლად დამატებული namenode მიერ გაშვებული შემდეგ ბრძანება -
o $HADOOP_PREFIX_HOME/bin/hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
- აღნიშნული ბრძანება უნდა შესრულდეს წინააღმდეგ datanodes კასეტური.
Summary: HDFS ფედერაცია დაინერგა დაძლიოს შეზღუდვები ადრე HDFS განხორციელების. დამატება scalability at სივრცე ფენის ყველაზე მნიშვნელოვანი თვისება HDFS ფედერაცია არქიტექტურა. მაგრამ HDFS ფედერაცია უკან თავსებადი, ასე რომ, ერთი namenode კონფიგურაციის ასევე მუშაობს ყოველგვარი ცვლილებების.
მოდით შევაჯამოთ ჩვენი დისკუსიის სახით შემდეგ ტყვიები
- HDFS ფედერაცია ჰყოფს namenode ფენის და შენახვის ფენის.
- HDFS ფედერაცია მიზნად ისახავს დაძლიოს შეზღუდვები ერთი კვანძის HDFS არქიტექტურა, სადაც შენახვის შეიძლება გავაფართოვოთ ჰორიზონტალურად არ სივრცე.
- HDFS ფედერაცია მოდის შემდეგი უპირატესობები -
- Isolation
- Scalability
- მარტივი დიზაინი
- HDFS კონფიგურაცია ძალიან მარტივია და ასევე მარტივი.