Vue d'ensemble: Nous sommes bien conscients des caractéristiques de Hadoop HDFS et. Dans ce document, nous allons parler de la fédération HDFS qui nous aide à améliorer une architecture HDFS existante. Il fournit une séparation claire entre l'espace de noms et de stockage permet ainsi l'évolutivité et l'isolement au niveau de la grappe.
Présentation: Hadoop fédération sépare la espace de noms couche et couche de stockage. Il permet à la couche de stockage de bloc. Il élargit également l'architecture d'un cluster de HDFS existant pour permettre les mises en œuvre et les cas d'utilisation nouvelle. L'architecture actuelle HDFS a deux couches -
- namespace - Cette couche gère les fichiers, répertoires et blocs. Cette couche prend en charge les opérations du système de fichiers de base e.g. liste des fichiers, création de fichiers, modification des fichiers et la suppression des fichiers et des dossiers.
- Bloc de stockage - Cette couche comporte deux parties -
- Gestion de bloc Celui-ci gère les DataNodes du cluster et fournit des opérations comme la création, effacement, la modification et la recherche. Il prend également en charge la gestion de la réplication.
- Stockage physique Cette stocke les blocs et fournit un accès pour lire ou écrire des opérations.
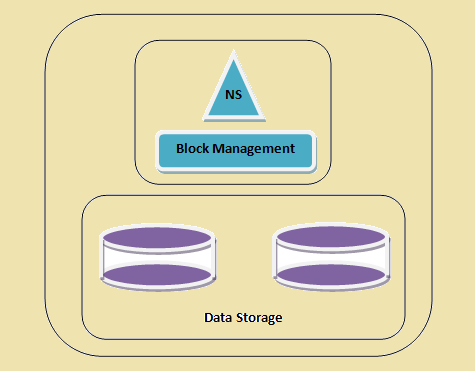
Un cluster HDFS
Figure 1: Un cluster HDFS
Dans l'architecture actuelle HDFS, nous avons un seul espace de noms pour l'ensemble du cluster qui est géré par un nœud de nom unique. En utilisant cette approche, il devient plus facile à mettre en œuvre le cluster HDFS. Cette superposition de l'architecture fonctionne très bien pour les petites configurations tandis que pour les grandes organisations où un énorme volume de données doit être pris en charge à une vitesse rapide, e.g. yahoo et Facebook il a été constaté que cette approche a des limites qui sont gérées par la fédération Hadoop. Donc, Hadoop fédération peut être définie comme l'architecture avancée pour surmonter les limitations de la mise en œuvre actuelle HDFS.
Laissez-nous vérifier les limitations comme expliqué ci-dessous -
- Étroitement couplé bloc de stockage et Namespace - Dans l'architecture actuelle de stockage de bloc et l'espace de noms sont étroitement couplés qui rend les implémentations alternatives de nom nœuds difficiles et restreint d'autres services à utiliser le stockage en bloc directement.
- Namespace Évolutivité - Le cluster HDFS échelles horizontalement en ajoutant DataNodes mais nous ne pouvons pas ajouter plus de l'espace de noms à un cluster existant horizontalement. Nous pouvons élargir l'espace de noms verticalement sur un seul NameNode. Le NameNode stocke les métadonnées du système de fichiers complet dans sa mémoire qui limite le nombre de blocs, fichiers et répertoires à être pris en charge sur le système de fichiers qui doit être logé dans la mémoire de l'unique NameNode.
- Performance - Les opérations du système de fichiers actuels sont limités au débit d'un nœud de nom unique qui, à des supports présents 60000 tâches concurrentes. Mais la nouvelle carte vient réduire d'Apache aura un support pour plus de 100000 tâches concurrentes et donc, il faudra plusieurs nœuds.
- Isolement - En général, les déploiements HDFS sont disponibles sur un environnement multi-locataires où un cluster unique est partagé par plusieurs organisations. Dans cette configuration un espace de noms séparé est pas possible pour une application ou d'une organisation.
Fédération HDFS:
Hadoop fédération permet l'extension du service de nom horizontalement. Il utilise plusieurs espaces de noms namenodes ou qui sont indépendants les uns des autres. Ceux-ci sont indépendants namenodes fédérée c'est à dire. ils ne nécessitent pas inter coordination. Ces DataNodes sont utilisés comme stockage commun par tous les namenodes. Chaque DataNode est inscrit sur tous les namenodes du cluster. Ces DataNodes envoient des rapports périodiques et répond aux commandes à partir des noeuds de noms. Nous avons une piscine de bloc qui est un ensemble de blocs qui appartiennent à un seul espace de noms. Dans un cluster, les blocs DataNodes magasins pour toutes les piscines de bloc. Chaque pool de bloc est géré de façon indépendante. Cela permet à l'espace de noms pour générer ids de bloc pour de nouveaux blocs sans en informer d'autres namespaces. Si l'on NameNode échoue pour une raison quelconque, l'DataNode continue à servir d'autres namenodes.
Un espace de noms et son bloc sont collectivement appelés namespace Volume. Quand un espace de noms ou un NameNode est supprimé du pool de bloc correspondant au DataNode est automatiquement supprimé. Dans le processus de la grappe jusqu'à gradation, chaque volume d'espace de noms est mis à jour en tant qu'unité.
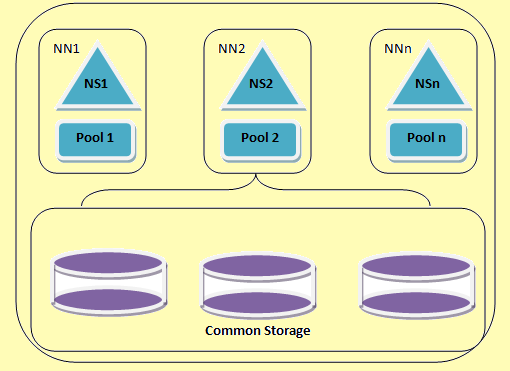
Une architecture de fédération HDFS
Figure 2: Une architecture de fédération HDFS
Avantages de la Fédération Hadoop:
Hadoop fédération vient avec des avantages et des avantages qui sont répertoriés comme sous -
- Evolutivité et isolement - namenodes multiples échelles horizontalement dans l'espace de noms de système de fichiers. Cela sépare effectivement les volumes d'espace de noms pour les utilisateurs et les catégories d'application et fournit un isolement absolu.
- Service de stockage générique - La piscine de niveau bloc abstraction permet l'architecture de construire de nouveaux systèmes de fichiers sur le dessus de stockage de bloc. Nous pouvons facilement construire de nouvelles applications sur la couche de stockage de bloc sans utiliser l'interface de système de fichiers. catégories personnalisées de pool de bloc peuvent également être construites qui sont différentes de la piscine de bloc par défaut.
- Conception simple - Namenodes et des espaces de noms sont indépendants les uns des autres. Il n'y a guère de scénario qui nécessite de changer les nœuds de noms existants. Chaque nœud du nom est conçu pour être robuste. Fédération est également rétrocompatible. Il intègre facilement avec les déploiements de nœuds simples existants qui fonctionnent sans aucune modification de configuration.
Configuration d'une Fédération HDFS:
La configuration de la Fédération Hadoop est conçue de telle sorte que tous les noeuds de la grappe ont la même configuration. La configuration est effectuée dans les étapes suivantes: -
- Step 1 - Les paramètres suivants doivent être ajoutés dans la configuration existante -
- résolution de noms - Ceci est configuré avec une liste séparées par des virgules NameServiceIDs. Ce paramètre est utilisé par DataNodes pour déterminer tous les namenodes du cluster.
- Step 2 - Les configurations suivantes doivent être suffixé avec l'ID de service de nom correspondant dans le fichier de configuration commun.
- NameNode
- Secondary NameNode
- BackupNode
Un fichier de configuration de l'échantillon pour deux namenodes est illustré ci-dessous -
Listing 1: Un fichier de configuration de l'échantillon pour deux noeuds
[Code]
<configuration>
<propriété>
<nom>dfs.nameservices</nom>
<valeur>ns1, ns2</valeur>
</propriété>
<propriété>
<nom>dfs.namenode.rpc-address.ns1</nom>
<valeur>nn-host1:6600</valeur>
</propriété>
<propriété>
<nom>dfs.namenode.http-address.ns1</nom>
<valeur>nn-host1:8080</valeur>
</propriété>
<propriété>
<nom>dfs.namenode.secondaryhttp-address.ns1</nom>
<valeur>NHS-host1:8080</valeur>
</propriété>
<propriété>
<nom>dfs.namenode.rpc-address.ns2</nom>
<valeur>nn-host2:6600</valeur>
</propriété>
<propriété>
<nom>dfs.namenode.http-address.ns2</nom>
<valeur>nn-host2:8080</valeur>
</propriété>
<propriété>
<nom>dfs.namenode.secondaryhttp-address.ns2</nom>
<valeur>NHS-host2:8080</valeur>
</propriété>
</configuration>
[/Code]
Formatage du NameNode: Laissez-nous les commandes au format NameNode.
- Step 1 – Un nœud de nom unique peut être formaté en utilisant ce qui suit -
$HADOOP_USER_HOME / bin / hdfs NameNode -format [-clusterid <CLUSTER_ID>]
L'identifiant de cluster doit être unique et ne doit pas entrer en conflit avec une autre sortie grappe id. Si non prévu, un identifiant de cluster unique est généré au moment de la mise en forme.
- Step 2 - NameNode supplémentaire peut être formaté en utilisant la commande suivante -
$HADOOP_PREFIX_HOME / bin / hdfs NameNode -format -clusterid <CLUSTER_ID>
Il est important ici que l'identifiant de cluster mentionnés ici doit être le même de celui mentionné dans la étape 1. Si ces deux diffèrent, le NameNode supplémentaire ne sera pas la partie du cluster fédéré.
Démarrage et arrêt du cluster: Laissez-nous vérifier les commandes pour démarrer et arrêter le cluster.
- Démarrez le cluster - Le cluster peut être démarré en exécutant la commande suivante -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
- Arrêtez le cluster - Le cluster peut être arrêté en exécutant la commande suivante -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
Ajouter un nouveau NameNode à un cluster existant: Nous avons déjà décrit ce nom noeud multiple est au cœur de Hadoop fédération. Il est donc important de comprendre les étapes pour ajouter de nouveaux nœuds de nom et l'échelle horizontale.
Les étapes suivantes sont nécessaires pour ajouter de nouveaux namenodes -
- Le paramètre de configuration - résolution de noms doit être ajouté dans la configuration.
- NameServiceID doit être suffixé dans la configuration
- NameNode nouveau lié à la configuration doit être ajouté dans les fichiers de configuration.
- Le fichier de configuration doit être propagée à tous les nœuds du cluster.
- Démarrez la nouvelle NameNode et NameNode secondaire
- Actualiser les autres DataNodes de choisir le NameNode nouvellement ajouté en exécutant la commande suivante -
o $ HADOOP_PREFIX_HOME / bin / hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
- La commande ci-dessus doit être exécutée contre tous DataNodes sur le cluster.
Summary: HDFS fédération a été mis en place pour surmonter les limitations de mise en œuvre plus tôt HDFS. Ajout d'évolutivité à la couche d'espace de noms est la caractéristique la plus importante de HDFS architecture de fédération. Mais HDFS fédération est également rétro-compatible, de sorte que la configuration de NameNode unique sera également travailler sans aucune modification.
Résumons notre discussion sous forme de balles suivantes
- HDFS fédération sépare la couche NameNode et le couche de stockage.
- HDFS fédération est conçu pour surmonter les limitations de l'architecture unique nœud HDFS où le stockage peut évoluer horizontalement pas l'espace de noms.
- HDFS fédération vient avec les avantages suivants -
- Isolement
- Scalability
- simple design
- configuration HDFS est très simple et est aussi facile à gérer.