Yleiskatsaus: Olemme hyvin tietoisia ominaisuudet Hadoop ja HDFS. Tässä asiakirjassa me puhumme HDFS liittovaltio, joka auttaa meitä parantamaan olemassa HDFS arkkitehtuuri. Se on selkeä erottaminen nimiavaruus ja varastointi siten mahdollistaa skaalautuvuuden ja eristämisen ryhmätasolla.
Käyttöönotto: Hadoop liitto erottaa nimiavaruuden kerros ja varastointikerroksen. Se mahdollistaa lohkon varastointikerrosta. Se laajentaa myös arkkitehtuuria olemassa HDFS klusterin jotta uusia toteutuksia ja käyttötapauksia. Nykyinen HDFS arkkitehtuuri on kaksi kerrosta -
- nimiavaruuden - Tämä kerros hallitsee tiedostojen, hakemistoja ja lohkot. Tämä kerros tukee perus-tiedostojärjestelmää toiminnot esim. listaus tiedostojen, luominen Tiedostojen, muuttaminen tiedostoja ja poistetaan tiedostoja ja kansioita.
- Block Storage - Tämä kerros on kaksi osaa -
- Block Management Tämä johtaa datanodes klusterin ja tarjoaa toimintoja, kuten luomisen, poisto, muutos ja haku. Se huolehtii myös replikaation johdon.
- fyysinen Storage Tämä tallentaa lohkot ja tarjoaa pääsyn lukea tai kirjoittaa toimintaa.
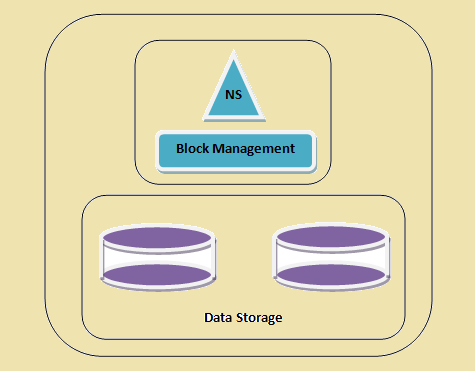
HDFS klusteri
Figure 1: HDFS klusteri
Nykyisessä HDFS arkkitehtuuri, meillä on vain yksi nimiavaruutta koko klusteri, joka hallinnoi yksi nimi solmussa. Tätä lähestymistapaa käyttäen on helpompi toteuttaa HDFS klusterin. Tämä Kerrostaa arkkitehtuuri toimii hyvin pienten asetelmia kun taas suurten organisaatioiden jossa valtava määrä tietoja on pidettävä huolta nopealla nopeudella, esim. Yahoo ja Facebook todettiin, että tällä lähestymistavalla on joitakin rajoituksia, jotka hoitavat Hadoop liitto. Joten Hadoop liitto voidaan määritellä kehittynyt arkkitehtuuri rajoitusten voittamiseksi nykyisen HDFS täytäntöönpanon.
Olkaamme tarkista rajoitukset, kuten jäljempänä selitetään -
- Tiiviisti yhdistettynä Block Storage ja Nimiavaruuden - Nykyisessä arkkitehtuuri lohkon varastoinnin ja nimitilan tiiviisti kytketty mikä tekee vaihtoehtoinen toteutuksia nimi solmujen haastavia ja rajoittaa muita palveluja käyttää lohkon muistilta.
- Nimiavaruuden skaalautuvuus - HDFS klusteri skaalautuu horisontaalisesti lisäämällä datanodes mutta emme voi lisätä nimiavaruudesta olemassa olevaan klusteriin vaakasuoraan. Voimme skaalata nimiavaruuden pystysuunnassa yhdellä namenode. Namenode tallentaa koko tiedostojärjestelmän metatiedot sen muisti, joka rajoittaa määrä lohkoja, tiedostojen ja hakemistojen tuettavat tiedostojärjestelmään, joka on sovitettu muistiin yhden namenode.
- Performance - Nykyisen tiedostojärjestelmän toiminnot rajoittuvat läpimeno yhden nimen solmu, joka tällä hetkellä tukee 60000 samanaikaiset tehtävät. Mutta uusi tulevan kartan hidastumiseen Apache on tukea yli 100000 samanaikainen tehtäviä ja siten edellyttää useita solmuja.
- Isolation - Yleensä HDFS asennuksia ovat saatavilla usean vuokralaisen ympäristö, jossa yksi klusteri on jaettu usean organisaatiot. Tässä setup erillinen nimiavaruus ei ole mahdollista yhden sovelluksen tai yhden organisaation.
HDFS Federation:
Hadoop liitto mahdollistaa skaalaus nimipalvelun vaakasuunnassa. Se käyttää useita namenodes tai nimiavaruuksia, jotka ovat toisistaan riippumattomia. Nämä ovat Independent namenodes hajautettuun so. ne eivät vaadi inter koordinointi. Näitä datanodes käytetään yhteisvarastointia kaikkien namenodes. Jokainen datanode rekisteröidään kaikki namenodes klusteriin. Nämä datanodes lähettää säännöllisesti raportteja ja vastaa komentoihin nimeä solmut. Olemme lohko allas, joka on joukko lohkoja, jotka kuuluvat yhteen nimiavaruuteen. Klusterissa, datanodes tallentaa lohkojen kaikille lohkon altaat. Jokainen lohko allas hallitaan itsenäisesti. Tämä mahdollistaa nimiavaruuden tuottaa lohkoon ids uusia lohkoja ilmoittamatta muita nimiavaruuksittain. Jos yksi namenode epäonnistuu jostain syystä, datanode pitää palvelemaan muista namenodes.
Yksi nimiavaruus ja sen lohkon kutsutaan yhteisnimellä nimiavaruuden Volume. Kun nimiavaruuden tai namenode poistetaan vastaavan lohkon altaan datanode poistetaan automaattisesti. Prosessissa klusterin ajan porrastus, Kunkin nimiavaruus tilavuus on päivittänyt yksikkönä.
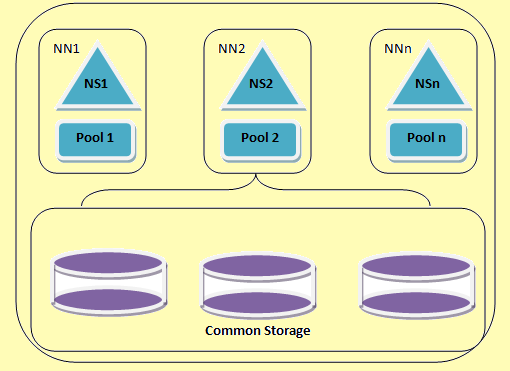
HDFS liitto arkkitehtuuri
Figure 2: HDFS liitto arkkitehtuuri
Edut Hadoop Federation:
Hadoop liitto päätyy joitakin etuja ja hyötyjä, jotka on lueteltu alla -
- Skaalautuvuus ja eristäminen - Useita namenodes vaakasuunnassa skaalautuu tiedostojärjestelmään nimiavaruuden. Tämä itse asiassa erottaa nimiavaruutta volyymit käyttäjille ja luokkien hakemuksen ja antaa ehdoton eristäminen.
- Generic Storage Service - Lohko taso allas abstraktio sallii arkkitehtuuri rakentaa uusia tiedostojärjestelmiä alustan päällä varastointi. Voimme helposti rakentaa uusia sovelluksia lohko varastointikerrosta ilman tiedostojärjestelmä käyttöliittymän. Räätälöidyt luokat lohkon allas voidaan rakentaa myös jotka eroavat oletuksena lohkon allas.
- Yksinkertainen Design - Namenodes ja namespaces ovat toisistaan riippumattomia. On tuskin skenaario, joka edellyttää muuttamalla nykyistä nimeä solmut. Jokainen nimi solmu on rakennettu vankaksi. Federation on myös taaksepäin yhteensopiva. Se integroituu helposti nykyisen yhden solmun asennuksia, jotka toimivat ilman asetusten muutoksia.
Konfigurointi HDFS Federation:
Kokoonpano Hadoop Federation on suunniteltu siten, että kaikki solmut klusterin on sama konfiguraatio. Konfiguraatio suoritetaan seuraavat vaiheet -
- Step 1 - Seuraavat parametrit on lisättävä nykyiseen kokoonpano -
- nameservices - Tämä on määritetty luettelo pilkulla erotettu NameServiceIDs. Tämä parametri on käytössä Datanodes määrätä kaikista namenodes klusteriin.
- Step 2 - Seuraavat kokoonpanot on kirjaimella vastaava nimi huoltotunnusnumero yhteiseen asetustiedostoa.
- Namenode
- Secondary NameNode
- BackupNode
Näyte konfiguraatiotiedosto kaksi namenodes on esitetty alla -
Listing 1: Näyte konfiguraatiotiedosto kaksi solmua
[Code]
<kokoonpano>
<omaisuus>
<nimi>dfs.nameservices</nimi>
<arvo>ns1,ns2</arvo>
</omaisuus>
<omaisuus>
<nimi>dfs.namenode.rpc-address.ns1</nimi>
<arvo>nn-palvelimen1:6600</arvo>
</omaisuus>
<omaisuus>
<nimi>dfs.namenode.http-address.ns1</nimi>
<arvo>nn-palvelimen1:8080</arvo>
</omaisuus>
<omaisuus>
<nimi>dfs.namenode.secondaryhttp-address.ns1</nimi>
<arvo>NHS-palvelimen1:8080</arvo>
</omaisuus>
<omaisuus>
<nimi>dfs.namenode.rpc-address.ns2</nimi>
<arvo>nn-host2:6600</arvo>
</omaisuus>
<omaisuus>
<nimi>dfs.namenode.http-address.ns2</nimi>
<arvo>nn-host2:8080</arvo>
</omaisuus>
<omaisuus>
<nimi>dfs.namenode.secondaryhttp-address.ns2</nimi>
<arvo>NHS-host2:8080</arvo>
</omaisuus>
</kokoonpano>
[/Code]
Alustaminen Namenode: Olkaamme komentoja muotoon namenode.
- Step 1 – Yksi nimi solmu voidaan muotoilla käyttämällä seuraavaa -
$HADOOP_USER_HOME / bin / HDFS namenode -formaatissa [-ClusterID <cluster_id>]
Klusteri id pitäisi olla ainutlaatuinen ja ei saa olla ristiriidassa minkään muun poistuvan klusterin id. Jos ei anneta, ainutlaatuinen klusteri id syntyy aikaan muotoilua.
- Step 2 - Muita namenode voidaan muotoilla seuraavalla komennolla -
$HADOOP_PREFIX_HOME / bin / HDFS namenode -muodossa -clusterId <cluster_id>
Tässä yhteydessä on tärkeää, että klusterin id tässä mainitut pitäisi olla sama kyseisen mainittu vaihe 1. Jos nämä kaksi ovat erilaisia, ylimääräiset namenode ei tule olemaan osa hajautetun klusterin.
Käynnistys ja pysäytys klusterin: Olkaamme tarkista komentoja aloittaa ja lopettaa klusterin.
- Käynnistä klusteri - Klusteri voidaan aloittaa suorittamalla seuraava komento -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
- Pysäytä klusteri - Klusteri voidaan pysäyttää suorittamalla seuraava komento -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
Lisää uusi namenode olemassa olevaan klusteriin: Olemme jo kuvattu, että useita nimi solmu on ytimessä Hadoop liittovaltio. Joten on tärkeää ymmärtää vaiheet lisätä uuden nimen solmuja ja skaalata vaakasuunnassa.
Seuraavat vaiheet ovat tarpeen lisätä uusia namenodes -
- Konfiguraatio parametri - nameservices täytyy lisätä konfiguraation.
- NameServiceID on kirjaimella konfiguraatiossa
- Uusi Namenode liittyvät config on lisättävä asetustiedostot.
- Asetustiedosto olisi leviää kaikkiin solmut klusterin.
- Aloita uusi namenode ja toissijainen namenode
- Päivitä muut datanodes valita äskettäin lisätty namenode suorittamalla seuraava komento -
o $HADOOP_PREFIX_HOME/bin/hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
- Yllä komento pitää suorittaa kaikkia datanodes klusterin.
Summary: HDFS liitto on otettu käyttöön korjata puutteet aiemmin HDFS täytäntöönpanon. Lisäämällä skaalautuvuus on nimiavaruuden kerros on tärkein ominaisuus HDFS liittovaltion arkkitehtuuri. Mutta HDFS liitto on myös taaksepäin yhteensopiva, joten yhden namenode kokoonpano toimii myös ilman muutoksia.
Olkaamme yhteenveto keskusteluamme muodossa seuraavat luoteja
- HDFS liitto erottaa namenode kerros ja varastointikerroksen.
- HDFS liitto on suunniteltu voittamaan rajoitukset yhden solmun HDFS arkkitehtuuria, jossa varastointi skaalautuu jopa vaakasuunnassa ei nimitilaa.
- HDFS liitto päätyy seuraavia etuja -
- Eristäminen
- Scalability
- yksinkertainen malli
- HDFS kokoonpano on hyvin yksinkertainen ja se on myös helppo hallita.