Übersicht: Wir sind uns bewusst, die Merkmale von Hadoop und HDFS. In diesem Dokument werden wir über die HDFS Föderation sprechen, die uns eine bestehende HDFS Architektur zu verbessern hilft. Es bietet eine klare Trennung zwischen den Namensraum und Lagerung ermöglicht somit die Skalierbarkeit und Isolation auf Cluster-Ebene.
Einführung: Hadoop Bund trennt die Namespace Schicht und Speicherschicht. Es ermöglicht die Blockspeicherschicht. Es erweitert auch die Architektur eines bestehenden HDFS Cluster neue Implementierungen und Anwendungsfälle zu ermöglichen. Die aktuelle HDFS Architektur hat zwei Schichten -
- Namespace - Diese Schicht verwaltet Dateien, Verzeichnisse und blockiert. Diese Schicht unterstützt die grundlegenden Dateisystemoperationen z. Liste der Dateien, Erstellen von Dateien, Änderung von Dateien und Löschen von Dateien und Ordnern.
- Blockspeicher - Diese Schicht besteht aus zwei Teilen -
- Block-Management Diese verwaltet die Datanodes im Cluster und stellt Operationen wie Schöpfung, Streichung, Änderung und Suche. Es kümmert sich auch um die Replikationsmanagement.
- Physische Speicher Dieser speichert die Blöcke und ermöglicht den Zugriff für Lese- oder Schreibvorgänge.
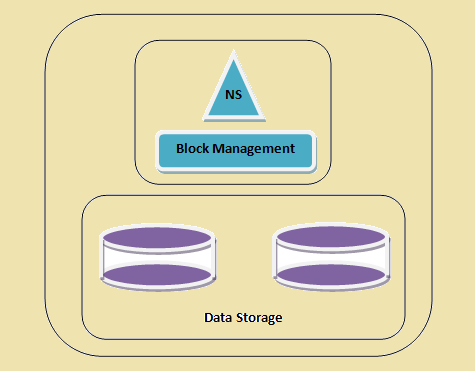
Ein HDFS Cluster
Figure 1: Ein HDFS Cluster
In der aktuellen HDFS Architektur, wir haben nur einen Namensraum für den gesamten Cluster, die durch einen einzigen Namen Knoten verwaltet wird. Mit diesem Ansatz wird es einfacher, die HDFS-Cluster zu implementieren. Diese Schichtung der Architektur funktioniert für kleinere Setups in Ordnung, während für größere Unternehmen, in denen eine große Menge an Daten mit einer schnellen Geschwindigkeit gesorgt werden muss, z.B.. Yahoo und Facebook wurde festgestellt, dass dieser Ansatz hat einige Einschränkungen, die durch die Hadoop Verband behandelt werden. So Hadoop Verband kann als die fortschrittliche Architektur definiert werden, um die Grenzen der gegenwärtigen HDFS Umsetzung zu überwinden.
Lassen Sie uns die Grenzen überprüfen, wie weiter unten erläutert -
- Dicht Blockspeicher und Namespace gekoppelt - In der aktuellen Architektur sind die Blockspeicher und der Namespace eng gekoppelt, welche die alternativen Implementierungen von Namen Knoten herausfordernd macht und schränkt andere Dienste den Blockspeicher direkt zu verwenden,.
- Namespace Skalierbarkeit - Die HDFS Cluster horizontal skaliert von Datanodes Zugabe, aber wir können nicht mehr Namensraum zu einem vorhandenen Cluster hinzufügen, horizontal. Wir können Namensraum vertikal auf einem einzigen NameNode maßstabs. Die NameNode speichert das komplette Dateisystem-Metadaten in seinem Speicher, der die Anzahl der Blöcke begrenzt, Dateien und Verzeichnisse, getragen auf dem Dateisystem zu, das in dem Speicher der einzelnen NameNode untergebracht werden muss,.
- Leistung - Die aktuellen Dateisystemoperationen werden an den Durchsatz eines einheitlichen Namens Knoten beschränkt, die gegenwärtig Träger 60000 gleichzeitige Aufgaben. Aber die neue kommende Karte von Apache reduzieren wird mehr eine Unterstützung haben als 100000 gleichzeitige Aufgaben und so werden mehrere Knoten erfordern.
- Isolation - Im Allgemeinen sind die HDFS-Installationen auf einem Multi-Tenant-Umgebung zur Verfügung, wo eine einzelne Cluster von mehreren Organisationen gemeinsam genutzt wird. In dieser Konfiguration ist ein separater Namensraum nicht möglich, dass eine Anwendung oder eine Organisation.
HDFS Federation:
Hadoop Verband ermöglicht es dem Namensdienst horizontal skaliert. Es verwendet mehrere namenodes oder Namensräume, die voneinander unabhängig sind,. Diese sind unabhängig namenodes föderierte d.h. sie benötigen keine inter Koordination. Diese Datanodes werden als gemeinsame Lagerung von allen namenodes verwendet. Jede DataNode ist mit allen namenodes im Cluster registriert. Diese Datanodes senden regelmäßige Berichte und reagiert auf die Befehle von den Namen Knoten. Wir haben einen Block Pool, der eine Reihe von Blöcken, die zu einem einzigen Namespace gehören. In einem Cluster, die Datanodes speichert Blöcke für alle Block-Pools. Jeder Block Pool verwaltet wird unabhängig. Dies ermöglicht es dem Namensraum-Block-IDs für neue Blöcke zu erzeugen, ohne andere Namensräume zu informieren. Wenn man NameNode versagt aus irgendeinem Grund, die DataNode hält von anderen namenodes auf die Betreuung.
Ein Namespace und seinen Block kollektiv genannt Namespace Volume. Wenn ein Namespace oder ein NameNode am DataNode der entsprechende Block-Pool gelöscht wird, wird automatisch gelöscht. In dem Verfahren der Cluster-up-Abstufungs, jeder Namespace-Volume wird als eine Einheit aufgerüstet.
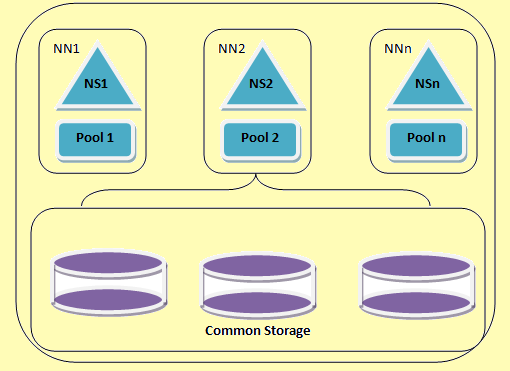
Eine HDFS Föderation Architektur
Figure 2: Eine HDFS Föderation Architektur
Vorteile von Hadoop Federation:
Hadoop Verband kommt mit einigen Vorteilen und Nutzen auf, die wie unter aufgeführt sind -
- Skalierbarkeit und Isolation - Mehrere namenodes horizontal skaliert im Dateisystem-Namensraum nach oben. Dieser trennt tatsächlich Namespace-Volumes für Benutzer und Gruppen von Anwendung und stellt eine absolute Isolation.
- Generisches Storage Service - Der Block-Ebene Pool Abstraktion ermöglicht die Architektur neue Dateisysteme auf der Blockspeicher zu bauen. Wir können auf einfache Weise neue Anwendungen auf dem Blockspeicherschicht aufbauen, ohne das Dateisystem-Schnittstelle. Kundenspezifische Kategorien von Block-Pool kann auch aus dem Pool gebaut werden, die Standard-Block unterschiedlich sind.
- Einfache Konstruktion - Namenodes und Namensräume sind unabhängig voneinander. Es gibt kaum ein Szenario, das Knoten Änderung der bestehenden Namen erfordert. Jeder Name Knoten gebaut robust sein. Federation ist auch abwärtskompatibel. Es lässt sich leicht mit den vorhandenen einzelnen Knoten-Implementierungen, die ohne Änderungen an der Konfiguration arbeiten.
Konfigurieren eines HDFS Federation:
Konfiguration Hadoop Federation ist in einer solchen Weise, dass alle Knoten in dem Cluster die gleiche Konfiguration haben,. Die Konfiguration wird in den folgenden Schritten durchgeführt -
- Step 1 - Die folgenden Parameter muss in der bestehenden Konfiguration hinzugefügt werden, -
- nameservices - Dies ist eine Liste mit Komma getrennt NameServiceIDs konfiguriert. Dieser Parameter wird von Datanodes verwendet, um alle namenodes in dem Cluster zu bestimmen,.
- Step 2 - Die folgenden Konfigurationen muss mit dem entsprechenden Namen Service-ID in die gemeinsame Konfigurationsdatei angehängt werden.
- NameNode
- Secondary NameNode
- BackupNode
Eine Beispielkonfigurationsdatei für zwei namenodes ist unten dargestellt -
Listing 1: Eine Beispielkonfigurationsdatei für zwei Knoten
[Code]
<Konfiguration>
<Eigentum>
<Name>dfs.nameservices</Name>
<Wert>ns1, ns2</Wert>
</Eigentum>
<Eigentum>
<Name>dfs.namenode.rpc-address.ns1</Name>
<Wert>nn-host1:6600</Wert>
</Eigentum>
<Eigentum>
<Name>dfs.namenode.http-address.ns1</Name>
<Wert>nn-host1:8080</Wert>
</Eigentum>
<Eigentum>
<Name>dfs.namenode.secondaryhttp-address.ns1</Name>
<Wert>NHS-host1:8080</Wert>
</Eigentum>
<Eigentum>
<Name>dfs.namenode.rpc-address.ns2</Name>
<Wert>nn-host2:6600</Wert>
</Eigentum>
<Eigentum>
<Name>dfs.namenode.http-address.ns2</Name>
<Wert>nn-host2:8080</Wert>
</Eigentum>
<Eigentum>
<Name>dfs.namenode.secondaryhttp-address.ns2</Name>
<Wert>NHS-host2:8080</Wert>
</Eigentum>
</Konfiguration>
[/Code]
Die Formatierung der NameNode: Lassen Sie uns die Befehle Format NameNode.
- Step 1 – Ein einziger Name Knoten kann unter Verwendung der folgenden formatiert werden -
$HADOOP_USER_HOME / bin / hdfs NameNode -format [-ClusterID <CLUSTER_ID>]
Die Cluster-ID sollte eindeutig sein und darf nicht mit anderen austretenden Cluster-ID-Konflikt. Falls nicht vorhanden, eine eindeutige Cluster-ID wird zum Zeitpunkt der Formatierung erzeugt.
- Step 2 - Zusätzliche NameNode kann mit dem folgenden Befehl formatiert werden -
$HADOOP_PREFIX_HOME / bin / hdfs NameNode -format -clusterid <CLUSTER_ID>
Hier ist es wichtig, dass die Cluster-ID hier erwähnt wird, sollte das gleiche von dem in der erwähnten sein Schritt 1. Wenn diese beiden sind verschieden, die zusätzliche NameNode nicht der Teil des föderierten Clusters sein.
Starten und Stoppen des Clusters: Lassen Sie uns die Befehle prüfen zu starten und die Cluster stoppen.
- Starten Sie den Cluster - Der Cluster kann durch Ausführen des folgenden Befehls gestartet werden -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
- Stoppen Sie den Cluster - Der Cluster kann durch Ausführen des folgenden Befehls gestoppt werden -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
Fügen Sie einen neuen NameNode zu einem vorhandenen Cluster: Wir haben bereits beschrieben, dass mehrere Knoten für die Namen im Herzen von Hadoop Föderation ist. Deshalb ist es wichtig, die Schritte zu verstehen neuen Namen Knoten hinzuzufügen und horizontal skalieren.
Die folgenden Schritte sind erforderlich, um neue namenodes hinzufügen -
- Der Konfigurationsparameter - nameservices muss in der Konfiguration hinzugefügt werden.
- NameServiceID In der Konfiguration muss angefügt werden
- New NameNode auf die Config im Zusammenhang muss in den Konfigurationsdateien hinzugefügt werden.
- Die Konfigurationsdatei sollte an alle Knoten in dem Cluster vermehrt werden.
- Starten Sie die neue NameNode und die sekundäre NameNode
- Aktualisieren Sie die anderen Datanodes die neu hinzugefügte NameNode zu holen, indem Sie den folgenden Befehl ausführen -
o $HADOOP_PREFIX_HOME/bin/hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
- Der obige Befehl muss gegen alle Datanodes auf dem Cluster ausgeführt werden.
Summary: HDFS Verband wurde die Grenzen der früheren HDFS Umsetzung zu überwinden eingeführt. Hinzufügen Skalierbarkeit bei der Namespace-Ebene ist das wichtigste Merkmal von HDFS Föderation Architektur. Aber HDFS Verband ist auch abwärtskompatibel, so dass die einzelnen NameNode Konfiguration funktioniert auch ohne Änderungen.
Lassen Sie uns unsere Diskussion in Form von folgenden Kugeln zusammenfassen
- HDFS Bund trennt die NameNode Schicht und das Speicherschicht.
- HDFS Verband ist auf die Grenzen des einzelnen Knotens HDFS Architektur zu überwinden, wo die Lagerung horizontal skalieren kann nicht den Namespace.
- HDFS Föderation kommt mit folgenden Vorteilen up -
- Isolierung
- Scalability
- Übersichtliches Design
- HDFS Konfiguration ist sehr einfach und ist auch leicht zu handhaben.