Přehled: Jsme si dobře vědomi z rysů Hadoop a HDFS. V tomto dokumentu se budeme hovořit o federaci HDFS což nám pomáhá zlepšit stávající HDFS architekturu. Poskytuje jasné oddělení mezi názvů a skladování tedy umožňuje škálovatelnost a izolaci na úrovni uskupení.
Úvod: Hadoop federace odděluje namespace vrstva a Zásobní vrstva. Umožňuje blokovat zásobní vrstvu. To také rozšiřuje architekturu existujícího clusteru HDFS, aby nové implementace a případy užití. Aktuální HDFS architektura má dvě vrstvy -
- namespace - Tato vrstva spravuje soubory, adresáře a bloky. Tato vrstva podporuje základní systémové operace, např. výpis souborů, Vytváření souborů, modifikace souborů a smazání souborů a složek.
- Block Storage - Tato vrstva má dvě části -
- Block Správa Tato spravuje datanodes v klastru a poskytuje operace, jako je vytvoření, vymazání, modifikace a vyhledávání. To se také stará o řízení replikace.
- Fyzické skladování To ukládá bloky a poskytuje přístup pro čtení nebo zápisu.
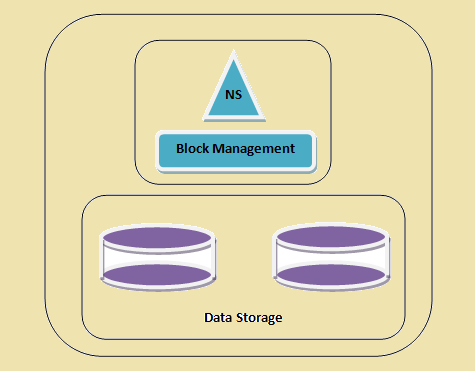
Cluster HDFS
Figure 1: Cluster HDFS
V současném HDFS architektury, Máme jen jeden obor názvů pro celý cluster, který je spravován jednoho uzlu jméno. Použití tohoto přístupu je snadnější implementovat clusteru HDFS. Toto vrstvení architektury funguje pro menší sestavách, zatímco u větších organizacích, kde musí být postaráno v rychlém rychlostí obrovský objem dat, např. Yahoo a Facebook bylo zjištěno, že tento přístup má některá omezení, které jsou zpracovány Hadoop federace. Takže Hadoop federace může být definována jako pokročilé architektury překonat omezení současného provádění HDFS.
Pojďme zjistit omezení, jak je vysvětleno níže -
- Pevně spojený Block Storage a Namespace - V současné architektuře skladování blok a Namespace jsou pevně spojeny který dělá alternativní implementací jmenných uzlů náročných a omezuje další služby použít úložiště bloku přímo.
- Namespace škálovatelnost - Klastr HDFS váhy horizontálně přidáním datanodes ale nemůžeme přidat více názvů do existujícího clusteru vodorovně. Můžeme měřítko jmenný prostor ve svislém směru na jediném namenode. Namenode ukládá kompletní systém souborů metadata do své paměti, která omezuje počet bloků, soubory a adresáře, které mají být podporovány na souborovém systému, který potřebuje být ubytováni v paměti jednotné namenode.
- Představení - Existující systém souborů operace jsou omezeny na propustnost jednoho uzlu jméno, které v současné době podpěrách 60000 souběžných úkoly. Ale nový příchod mapreduce od Apache bude mít podporu pro více než 100000 souběžných úkoly a tudíž budou vyžadovat více uzlů.
- izolace - Obecně jsou k dispozici rozmístění HDFS na multi-tenant prostředí, kde je jediná clusteru sdílené více organizací. Při tomto nastavení samostatný obor názvů není možné, aby jedna aplikace nebo jedné organizace.
HDFS federace:
Hadoop federace umožňuje horizontální škálování názvu služby. Využívá několik namenodes nebo jmenné prostory, které jsou na sobě nezávislé. Jsou to Nezávislé namenodes federated tj. nevyžadují inter koordinace. Tyto datanodes jsou používány jako společné skladování všemi namenodes. Každý datanode je registrována u všech namenodes v clusteru. Tyto datanodes posílat pravidelné zprávy a reaguje na povely ze jména uzlů. Máme blok bazén, který je sada bloků, které patří do jedné namespace. V clusteru, že datanodes ukládá bloky pro všechny blokové bazénů. Každý blok Bazén je řízen nezávisle. To umožňuje název místa ke generování blok identifikátory pro nové bloky, aniž by informoval další jmenné prostory. Jestliže jeden namenode z nějakého důvodu selže, datanode drží na porce od jiných namenodes.
Jeden namespace a jeho blok se souhrnně nazývají namespace Volume. Při odstranění názvů nebo namenode odpovídající blok bazén v datanode je automaticky smazán. V procesu clusteru up-gradaci, Každý svazek namespace je aktualizován jako celek.
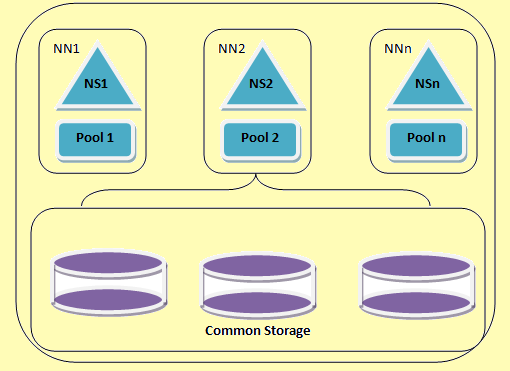
HDFS federace architektura
Figure 2: HDFS federace architektura
Výhody Hadoop federace:
Hadoop federace přijde s některými výhodami a přínosy, které jsou uvedeny jako pod -
- Škálovatelnost a izolace - Několik namenodes horizontálně rozšířitelná až do souborového systému jmenného prostoru. Toto vlastně odděluje objemy jmenném prostoru pro uživatele a kategorie aplikace a poskytuje absolutní izolaci.
- Generic Storage Service - Abstrakce na úrovni bloku bazén umožňuje architekturu vybudovat nové souborové systémy na vrcholu blokových úložišť. Můžeme snadno vytvářet nové aplikace na bloku zásobní vrstvě bez použití rozhraní systému souborů. Upravené kategorií bloku bazénu mohou být také postaveny, které se liší od výchozí bloku bazénu.
- Jednoduchý design - Namenodes a jmenné prostory jsou na sobě nezávislé. Tam je téměř žádný scénář, který vyžaduje změnu stávající název uzly. Každý uzel jméno je postavena tak, aby robustní. Federace je také zpětně kompatibilní. To lze snadno integrovat se stávajícími jeden uzel nasazení, které pracují bez jakýchkoliv změn konfigurace.
Konfigurace HDFS federaci:
Konfigurace Hadoop federace je navržen takovým způsobem, že všechny uzly v klastru mají stejnou konfiguraci. Konfigurace se provádí v následujících krocích -
- Step 1 - Následující parametry musí být přidán do stávající konfigurace -
- nameservices - To je konfigurován pomocí seznamu oddělených čárkou NameServiceIDs. Tento parametr je používán Datanodes k určení všech namenodes v clusteru.
- Step 2 - Následující konfigurace je třeba suffixed s odpovídajícím ID název služby do společného konfiguračního souboru.
- Namenode
- Secondary NameNode
- BackupNode
Následuje jednoduchý konfigurační soubor pro dvě namenodes je uveden níže -
Listing 1: Následuje jednoduchý konfigurační soubor pro dva uzly
[Code]
<konfigurace>
<majetek>
<jméno>dfs.nameservices</jméno>
<hodnota>NS1, NS2</hodnota>
</majetek>
<majetek>
<jméno>dfs.namenode.rpc-address.ns1</jméno>
<hodnota>nn-host1:6600</hodnota>
</majetek>
<majetek>
<jméno>dfs.namenode.http-address.ns1</jméno>
<hodnota>nn-host1:8080</hodnota>
</majetek>
<majetek>
<jméno>dfs.namenode.secondaryhttp-address.ns1</jméno>
<hodnota>NHS-host1:8080</hodnota>
</majetek>
<majetek>
<jméno>dfs.namenode.rpc-address.ns2</jméno>
<hodnota>nn-host2:6600</hodnota>
</majetek>
<majetek>
<jméno>dfs.namenode.http-address.ns2</jméno>
<hodnota>nn-host2:8080</hodnota>
</majetek>
<majetek>
<jméno>dfs.namenode.secondaryhttp-address.ns2</jméno>
<hodnota>NHS-host2:8080</hodnota>
</majetek>
</konfigurace>
[/Code]
Formátování Namenode: Nechť nám příkazy do formátu namenode.
- Step 1 – Uzel jediný název může být formátován pomocí následující -
$HADOOP_USER_HOME / bin / hdfs namenode -formát [-Číslo klastru <cluster_id>]
Id klastr by měl být jedinečný a nesmí být v rozporu s žádným jiným vystupujícího clusteru ID. Pokud tomu tak není poskytována, jedinečný shluk id je generován v okamžiku formátování.
- Step 2 - Dodatečné namenode lze formátovat pomocí následujícího příkazu -
$HADOOP_PREFIX_HOME / bin / hdfs namenode -formát -clusterId <cluster_id>
Je zde důležité, aby id klastr zde výše by měl být stejné, který je uveden v části krok 1. Pokud jsou tyto dvě odlišné, dodatečná namenode nebude součástí federované clusteru.
Spouštění a zastavování clusteru: Pojďme zkontrolovat příkazy ke spuštění a zastavení cluster.
- Spuštění clusteru - Klastr lze spustit spuštěním následujícího příkazu -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
- Zastavit cluster - Clusteru lze zastavit spuštěním následujícího příkazu -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
Přidat nový namenode do existujícího clusteru: Už jsme popsali, že vícenásobný uzel je v centru Hadoop federace. Tak to je důležité pochopit kroky pro přidání nových názvů uzlů a měřítko vodorovně.
Následující kroky jsou potřebné k přidání nových namenodes -
- Konfigurační parametr - nameservices musí být přidán v konfiguraci.
- NameServiceID musí být v konfiguraci suffixed
- New Namenode vztahující se k config musí být přidán v konfiguračních souborech.
- Konfigurační soubor by měl být rozšířena do všech uzlů v clusteru.
- Spusťte nový namenode a sekundární namenode
- Refresh ostatní datanodes vybrat nově přidané namenode spuštěním následujícího příkazu -
o $HADOOP_PREFIX_HOME/bin/hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
- Výše uvedený příkaz musí být spuštěn proti všem datanodes na clusteru.
Summary: HDFS federace byla zavedena k překonání omezení dřívější realizace HDFS. Přidání škálovatelnost v oboru názvů vrstvy je nejdůležitějším rysem HDFS federace architektury. Ale HDFS federace je také zpětně kompatibilní, takže jediný konfigurační namenode bude také pracovat bez jakýchkoliv změn.
Shrňme si naši diskusi v podobě těchto střel
- HDFS federace odděluje namenode vrstva a Zásobní vrstva.
- HDFS federace je určen k překonání omezení na jednotném uzlu HDFS architektuře, kde je skladování může zvýšit vodorovně ne názvů.
- HDFS federace přichází s následující výhody -
- Izolace
- Scalability
- jednoduchý design
- Konfigurace HDFS je velmi jednoduchá a je snadno ovladatelné.