Visió de conjunt: Som molt conscients de les característiques de Hadoop i HDFS. En aquest document parlarem de la federació HDFS que ens ajuda a millorar una arquitectura existent HDFS. Proporciona una clara separació entre l'espai de noms i l'emmagatzematge per tant permet l'escalabilitat i l'aïllament a nivell de clúster.
Introducció: Hadoop separa la federació espai de noms capa i capa d'emmagatzematge. Permet a la capa d'emmagatzematge de blocs. També amplia l'arquitectura d'un clúster HDFS existent per permetre implementacions i casos d'ús nova. L'arquitectura actual HDFS té dues capes -
- Espai de noms - Aquesta capa gestiona els arxius, directoris i blocs. Aquesta capa és compatible amb el funcionament bàsic del sistema d'arxius per exemple. llista de fitxers, creació d'arxius, modificació dels arxius i l'eliminació d'arxius i carpetes.
- Block Storage - Aquesta capa té dues parts -
- la gestió de blocs Aquest gestiona els DataNodes al clúster i proporciona operacions com la creació, supressió, modificació i recerca. També s'encarrega de la gestió de la replicació.
- emmagatzematge físic Això emmagatzema els blocs i proporciona accés per a operacions de lectura o escriptura.
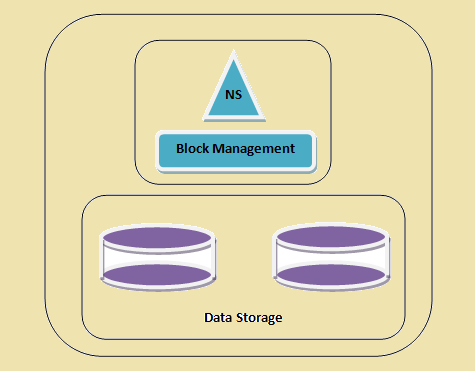
Un clúster HDFS
Figure 1: Un clúster HDFS
En l'actual arquitectura de HDFS, tenim un sol espai de noms per a tot el clúster que és administrat per un únic node del nom. Usant aquest enfocament es fa més fàcil d'implementar el clúster HDFS. Aquesta disposició en capes de l'arquitectura funciona bé per a configuracions amb menys capacitat, mentre que per a les organitzacions més grans, on cal anar amb compte a una velocitat ràpida d'un gran volum de dades, e.g. Yahoo i Facebook es va trobar que aquest enfocament té algunes limitacions que es manegen per la federació Hadoop. Així Hadoop federació es pot definir com l'arquitectura avançada per superar les limitacions d'implementació actual HDFS.
Anem a veure les limitacions tal com s'explica a continuació -
- Estretament acoblat bloc d'emmagatzematge i espai de noms - En l'arquitectura actual de l'emmagatzematge en bloc i l'espai de noms estan estretament unides que fa que les implementacions alternatives de nodes de noms difícils i restringeix altres serveis per utilitzar l'emmagatzematge en bloc directament.
- Escalabilitat espai de noms - El clúster HDFS escales horitzontal mitjançant l'addició d'DataNodes però no podem afegir més espai de noms a un clúster existent horitzontalment. Podem escalar espai de noms vertical en una mateixa NameNode. El NameNode emmagatzema les metadades del sistema d'arxius complet en la seva memòria el que limita el nombre de blocs, els arxius i directoris que s'admeten en el sistema d'arxius que necessita ser allotjats en la memòria de l'única NameNode.
- Rendiment - Les operacions del sistema d'arxius actuals es limiten al rendiment d'un sol node nom que en els suports actuals 60000 tasques concurrents. Però el nou mapa procedent de reduir Apache tindrà un suport per a més de 100000 tasques concurrents i per tant requeriran múltiples nodes.
- aïllament - En general, els desplegaments HDFS estan disponibles en un entorn multi-usuari, on un sol grup és compartit per múltiples organitzacions. En aquesta configuració un espai de noms separat no és possible per a una aplicació o una organització.
Federació HDFS:
Hadoop federació permet escalar el servei de noms horitzontalment. S'utilitza diverses namenodes o espais de noms que són independents entre si. Aquests són namenodes independents federada és a dir. que no requereixen entre la coordinació. Aquests DataNodes s'utilitzen com emmagatzematge comú de tots els namenodes. Cada DataNode s'ha registrat en tots els namenodes del clúster. Aquests DataNodes envien informes periòdics i respon als comandos des dels nodes de noms. Tenim una piscina de bloc que és un conjunt de blocs que pertanyen a un únic espai de noms. En un clúster, DataNodes les botigues de blocs per a totes les piscines de bloc. Cada bloc de la piscina es gestiona de forma independent. Això permet que l'espai de noms per generar identificadors de bloc per a nous blocs sense informar a altres espais de noms. Si un NameNode falla per qualsevol raó, DataNode segueix servint d'altres namenodes.
Un espai de noms i el seu bloc es denominen col·lectivament El volum d'espai de noms. Quan s'elimina un espai de noms o un NameNode la piscina bloc corresponent al DataNode s'elimina automàticament. En el procés d'agrupar fins-gradació, cada volum d'espai de noms s'actualitza com una unitat.
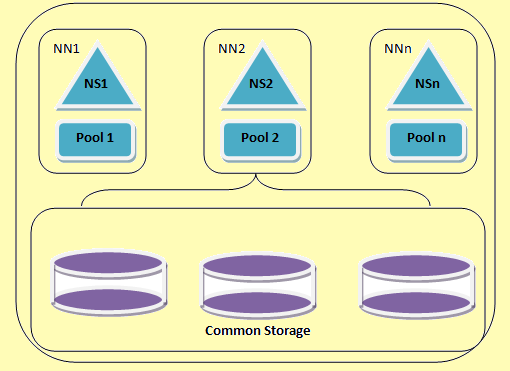
Una arquitectura federació HDFS
Figure 2: Una arquitectura federació HDFS
Beneficis de la Federació Hadoop:
Hadoop federació ve amb alguns avantatges i beneficis que s'enumeren com a baix -
- Escalabilitat i aïllament - Namenodes múltiples escales horitzontal en l'espai de noms del sistema d'arxius. En realitat, això separa volums d'espai de noms d'usuaris i categories d'aplicació i proporciona un aïllament absolut.
- Servei d'emmagatzematge genèric - L'abstracció de la piscina a nivell de bloc permet que l'arquitectura per construir nous sistemes de fitxers a la part superior del bloc d'emmagatzematge. Podem crear fàcilment noves aplicacions a la capa d'emmagatzematge de blocs no usats a la interfície del sistema d'arxius. categories personalitzades de la piscina bloc també poden ser construïts que són diferents de la piscina de bloc per defecte.
- Disseny simple - Namenodes i espais de noms són independents l'un de l'altre. No hi ha pràcticament cap escenari que requereix el canvi de nom dels nodes existents. Cada node del nom està construït per ser robust. Federació també és compatible amb versions anteriors. S'integra fàcilment amb els nous nodes individuals existents que funcionen sense cap canvi de configuració.
Configuració d'una Federació HDFS:
Configuració de la Federació Hadoop està dissenyat de tal manera que tots els nodes de l'agrupació tenen la mateixa configuració. La configuració es porta a terme en els següents passos -
- Step 1 - Els següents paràmetres ha de ser afegit en la configuració existent -
- serveis de noms - Això es configura amb una llista de NameServiceIDs separats per comes. Aquest paràmetre és utilitzat per DataNodes per determinar tots els namenodes del clúster.
- Step 2 - Les següents configuracions ha de ser amb el sufix corresponent al ID de servei de noms a l'arxiu de configuració comuna.
- NameNode
- Secondary NameNode
- BackupNode
Un arxiu de configuració d'exemple per a dues namenodes es mostra a continuació -
Listing 1: Un arxiu de configuració d'exemple per dos nodes
[Code]
<configuració>
<propietat>
<nom>dfs.nameservices</nom>
<valor>ns1, ns2</valor>
</propietat>
<propietat>
<nom>dfs.namenode.rpc-address.ns1</nom>
<valor>nn-sistpral1:6600</valor>
</propietat>
<propietat>
<nom>dfs.namenode.http-address.ns1</nom>
<valor>nn-sistpral1:8080</valor>
</propietat>
<propietat>
<nom>dfs.namenode.secondaryhttp-address.ns1</nom>
<valor>NHS-sistpral1:8080</valor>
</propietat>
<propietat>
<nom>dfs.namenode.rpc-address.ns2</nom>
<valor>nn-host2:6600</valor>
</propietat>
<propietat>
<nom>dfs.namenode.http-address.ns2</nom>
<valor>nn-host2:8080</valor>
</propietat>
<propietat>
<nom>dfs.namenode.secondaryhttp-address.ns2</nom>
<valor>NHS-host2:8080</valor>
</propietat>
</configuració>
[/Code]
Formatació de la NameNode: Vegem les ordres a format NameNode.
- Step 1 – Un node sol nom pot ser formatat utilitzant el següent -
$HADOOP_USER_HOME / bin / hdfs NameNode -format [-ClusterID <CLUSTER_ID>]
El grup ID ha de ser únic i no ha d'entrar en conflicte amb qualsevol altra sortida d'Identificació del clúster. Si no es proporciona, un ID de grup únic es genera en el moment de format.
- Step 2 - NameNode addicional es pot formatar amb la següent comanda -
$HADOOP_PREFIX_HOME / bin / hdfs NameNode -format -clusterId <CLUSTER_ID>
És important aquí que la ID de clúster esmentat aquí, ha de ser el mateix del que s'enumera al pas 1. Si aquests dos són diferents, NameNode addicional no serà la part del clúster federat.
Iniciar i aturar el clúster: Veurem les ordres per iniciar i aturar el clúster.
- Iniciar el clúster - El clúster pot iniciar-se mitjançant l'execució del següent comanda -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
- Aturar el clúster - El clúster es pot aturar mitjançant l'execució del següent comanda -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
Afegir un nou NameNode a un clúster existent: Ja hem descrit que el node de nom múltiple és al cor de Hadoop federació. Per tant, és important entendre els passos per afegir nous nodes de nom i escalar horitzontalment.
Es necessiten els següents passos per afegir nous namenodes -
- El paràmetre de configuració - serveis de noms necessita ser afegit a la configuració.
- NameServiceID ha de ser el sufix en la configuració
- Nova NameNode relacionada amb la configuració ha de ser afegit en els arxius de configuració.
- L'arxiu de configuració ha de ser propagat a tots els nodes del clúster.
- Iniciar el nou NameNode i la secundària NameNode
- Actualitzar els altres DataNodes per recollir el NameNode recentment agregat mitjançant l'execució del següent comanda -
o $HADOOP_PREFIX_HOME/bin/hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
- La comanda anterior s'ha d'executar en tots els DataNodes al clúster.
Summary: HDFS federació s'ha introduït per superar les limitacions de l'anterior aplicació HDFS. Afegint escalabilitat a la capa d'espai de noms és la característica més important de l'arquitectura federació HDFS. Però HDFS federació també és compatible amb versions anteriors, de manera que la configuració de NameNode única també funcionarà sense canvis.
Fem un resum de la nostra discussió en forma de bales següents
- HDFS separa la federació capa NameNode i la capa d'emmagatzematge.
- HDFS federació està dissenyat per superar les limitacions de l'arquitectura de node únic HDFS on l'emmagatzematge es pot ampliar l'espai de noms no horitzontalment.
- HDFS federació ve amb les següents avantatges -
- aïllament
- Scalability
- disseny senzill
- HDFS configuració és molt simple i també és fàcil de manejar.