Oorsig: Ons is deeglik bewus van die funksies van Hadoop en HDFS. In hierdie dokument sal ons praat oor die HDFS federasie wat ons help om 'n bestaande HDFS argitektuur te verbeter. Dit bied 'n duidelike skeiding tussen naamruimte en stoor in staat stel om sodoende scalability en isolasie op die cluster vlak.
Inleiding: Hadoop federasie skei die naamruimte laag en stoor laag. Dit stel die blok stoor laag. Dit brei ook die argitektuur van 'n bestaande HDFS cluster toe te laat nuwe implementering en gebruik gevalle. Die huidige HDFS argitektuur het twee lae -
- naamruimte - Hierdie laag bestuur lêers, dopgehou en blokke. Hierdie laag ondersteun die basiese lêerstelsel bedrywighede Bv. lys van lêers, skepping van lêers, verandering van lêers en skrap lêers en gidse.
- Blok berging - Hierdie laag bestaan uit twee dele -
- Blok Bestuur Dit bestuur die datanodes in die cluster en bied bedrywighede soos die skepping, skrap, verandering en soek. Dit sorg ook vir die replikasie bestuur.
- fisiese berging Dit slaan die blokke en bied toegang vir lees of skryf bedrywighede.
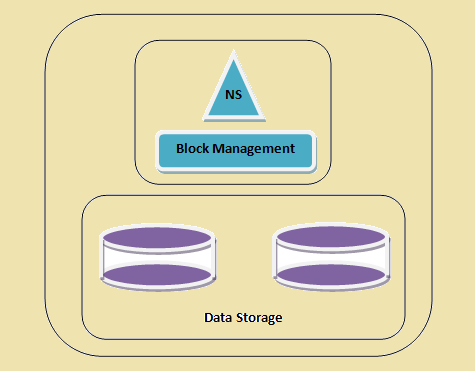
'N HDFS cluster
Figure 1: 'N HDFS cluster
In die huidige HDFS argitektuur, Ons het net een naamruimte vir die hele groep wat bestuur word deur 'n enkele naam node. Die gebruik van hierdie benadering is dit makliker om die HDFS cluster implementeer. Dit gelaagdheid van argitektuur werk goed vir kleiner setups terwyl vir 'n groter organisasies waar 'n groot volume van data moet sorg geneem moet word teen 'n vinnige spoed, Bv. yahoo en Facebook is daar gevind dat hierdie benadering het 'n paar beperkings wat hanteer word deur die Hadoop federasie. So Hadoop federasie kan gedefinieer word as die gevorderde argitektuur aan die beperkings van die huidige HDFS implementering oorkom.
Laat ons die beperkings kyk soos hieronder verduidelik -
- Styf gekoppel Blok berging en Naamruimte - In die huidige argitektuur die blok stoor en die Naamruimte is styf gekoppel wat die alternatiewe implementering van naam knope uitdagende maak en beperk ander dienste aan die blok stoor direk gebruik.
- Naamruimte Scalability - Die HDFS cluster skale horisontaal deur die byvoeging van datanodes maar ons kan nie meer naamruimte horisontaal te voeg tot 'n bestaande groep. Ons kan naamruimte vertikaal skaal op 'n enkele namenode. Die namenode slaan die volledige lêer stelsel metadata binne sy geheue wat die aantal blokke beperk, lêers en dopgehou te ondersteun op die lêer stelsel wat gevolg moet word geakkommodeer in die geheue van die enkele namenode.
- prestasie - Die huidige lêer stelsel bedrywighede is beperk tot die deurset van 'n enkele naam knoop wat op die oomblik ondersteun 60000 konkurrente take. Maar die nuwe komende kaart verminder vanaf Apache sal 'n ondersteuning vir meer as 100000 konkurrente take en dus sal verskeie nodusse vereis.
- isolasie - In die algemeen is die HDFS ontplooi op 'n multi-huurder omgewing waar 'n enkele groep gedeel word deur verskeie organisasies. In hierdie opstel van 'n aparte naamruimte nie moontlik vir 'n program of 'n organisasie.
HDFS Federasie:
Hadoop federasie kan skalering die naam diens horisontaal. Dit maak gebruik van 'n paar namenodes of naamruimtes wat onafhanklik van mekaar is. Dit is Onafhanklike namenodes Federated d.w.z. Hulle vereis nie inter koördinasie. Hierdie datanodes word as algemene stoor deur al die namenodes. Elke datanode geregistreer is by al die namenodes in die cluster. Hierdie datanodes stuur periodieke verslae en reageer op die bevele van die naam knope. Ons het 'n blok swembad wat is 'n versameling van die blokke wat aan 'n enkele naamruimte. In 'n groep, die datanodes winkels blokke vir al die blok swembaddens. Elke blok swembad is onafhanklik bestuur. Dit stel die naam ruimte om blok ids vir nuwe blokke te genereer sonder om ander naamruimtes. As een namenode versuim om enige rede, die datanode hou op die versorging van ander namenodes.
Een naamruimte en sy blok staan gesamentlik bekend as naamruimte Deel. Wanneer 'n naamruimte of 'n namenode is verwyder die ooreenstemmende blok swembad by die datanode is outomaties verwyder. In die proses van cluster up-gradering, elke naamruimte volume is opgegradeer as 'n eenheid.
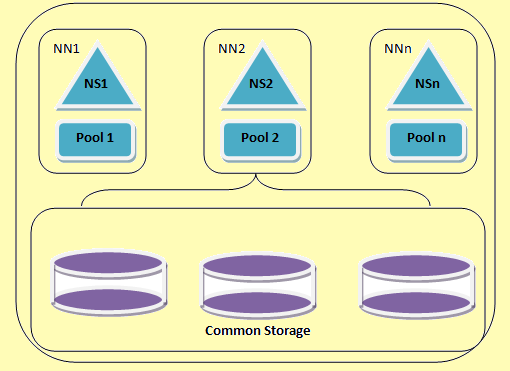
'N HDFS federasie argitektuur
Figure 2: 'N HDFS federasie argitektuur
Voordele van Hadoop Federasie:
Hadoop federasie kom met 'n paar voordele en voordele wat gelys is as onder -
- Scalability en isolasie - Veelvuldige namenodes skale horisontaal in die lêerstelsel naamruimte. Dit skei eintlik naamruimte volumes vir gebruikers en kategorieë van toepassing en bied 'n absolute afsondering.
- Generiese berging Service - Die blok vlak poel onttrekking kan die argitektuur nuwe lêerstelsels bou op die top van blok stoor. Ons kan maklik nuwe programme op die blok stoor laag te bou sonder die gebruik van die lêer stelsel interface. Aangepas kategorieë blok swembad kan ook gebou word wat verskil van die standaard blok swembad is.
- Eenvoudige ontwerp - Namenodes en naamruimtes is onafhanklik van mekaar. Daar is skaars 'n scenario wat vereis verandering van die bestaande naam knope. Elke naam node gebou robuuste te wees. Federasie is ook backwards compatible. Dit integreer maklik met die bestaande enkele nodus ontplooi wat werk sonder enige verstellings veranderinge.
'n HDFS Federasie instel:
Opset van Hadoop Federasie is ontwerp om in so 'n manier dat al die nodes in die cluster dieselfde opset. Die opset is in die volgende stappe gedoen -
- Step 1 - Die volgende parameters moet bygevoeg in die bestaande opset -
- nameservices - Dit is ingestel met 'n lys van kommas geskei NameServiceIDs. Hierdie parameter word deur Datanodes om al die namenodes in die cluster vas te stel.
- Step 2 - Die volgende konfigurasies moet bijvoegsel met die ooreenstemmende naam diens ID saam in die konfigurasielêer.
- Namenode
- Secondary NameNode
- BackupNode
'N Monster konfigurasielêer vir twee namenodes word hieronder getoon -
Listing 1: 'N Voorbeeld Van konfigurasielêer vir twee knope
[Code]
<opset>
<eiendom>
<naam>dfs.nameservices</naam>
<waarde>NS1, ns2</waarde>
</eiendom>
<eiendom>
<naam>dfs.namenode.rpc-address.ns1</naam>
<waarde>nn-host1:6600</waarde>
</eiendom>
<eiendom>
<naam>dfs.namenode.http-address.ns1</naam>
<waarde>nn-host1:8080</waarde>
</eiendom>
<eiendom>
<naam>dfs.namenode.secondaryhttp-address.ns1</naam>
<waarde>NHS-host1:8080</waarde>
</eiendom>
<eiendom>
<naam>dfs.namenode.rpc-address.ns2</naam>
<waarde>nn-host2:6600</waarde>
</eiendom>
<eiendom>
<naam>dfs.namenode.http-address.ns2</naam>
<waarde>nn-host2:8080</waarde>
</eiendom>
<eiendom>
<naam>dfs.namenode.secondaryhttp-address.ns2</naam>
<waarde>NHS-host2:8080</waarde>
</eiendom>
</opset>
[/Code]
Opmaak die Namenode: Laat ons die gebooie aan formaat namenode.
- Step 1 – 'N Enkele naam knoop kan geformateer word met behulp van die volgende -
$HADOOP_USER_HOME / bin / hdfs namenode -format [-clusterId <cluster_id>]
Die cluster ID moet uniek wees en moet nie in stryd met enige ander opwindende cluster ID. Indien nie voorsien, 'n unieke cluster ID gegenereer ten tyde van die uitleg.
- Step 2 - Bykomende namenode kan geformateer word met behulp van die volgende opdrag -
$HADOOP_PREFIX_HOME / bin / hdfs namenode -format -clusterId <cluster_id>
Dit is belangrik hier dat die wat hier genoem cluster ID dieselfde van daardie in die genoemde moet wees stap 1. As hierdie twee verskillende, die bykomende namenode sal nie die deel van die federale cluster wees.
Begin en stop die cluster: Kom ons kyk die bevele om te begin en stop die cluster.
- Begin die cluster - Die groep kan begin deur die uitvoering van die volgende opdrag -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
- Stop die cluster - Die groep kan gestop word deur die uitvoering van die volgende opdrag -
$HADOOP_PREFIX_HOME / bin / start-dfs.sh
Voeg 'n nuwe namenode om 'n bestaande groep: Ons het reeds beskryf wat veelvuldige naam node is in die hart van Hadoop federasie. Daarom is dit belangrik om die stappe om nuwe naam knope voeg en skaal horisontaal verstaan.
Die volgende stappe is nodig om nuwe namenodes voeg -
- Die opset parameter - nameservices moet bygevoeg word in die opset.
- NameServiceID moet bijvoegsel in die opset
- Nuwe Namenode wat verband hou met die config moet bygevoeg word in die konfigurasielêers.
- Die konfigurasielêer moet gepropageer om al die nodes in die cluster.
- Begin die nuwe namenode en die sekondêre namenode
- Verfris die ander datanodes om die nuwe bygevoeg namenode haal deur die loop van die volgende opdrag -
o $ HADOOP_PREFIX_HOME / bin / hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
- Bogenoemde opdrag moet uitgevoer word teen alle datanodes op die cluster.
Summary: HDFS federasie is ingestel om die beperkinge van vroeër HDFS implementering oorkom. Toevoeging van scalability by die naamruimte laag is die belangrikste kenmerk van HDFS federasie argitektuur. Maar HDFS federasie is ook backwards compatible, sodat die enkele namenode opset sal ook werk sonder enige veranderinge.
Kom ons som ons bespreking in die vorm van volgende 'bullets'
- HDFS federasie skei die namenode laag en die stoor laag.
- HDFS federasie is ontwerp om die beperkinge van die enkele nodus HDFS argitektuur oorkom waar die stoor kan vergroot horisontaal nie die naamruimte.
- HDFS federasie kom met volgende voordele -
- isolasie
- Scalability
- eenvoudige ontwerp
- HDFS opset is baie eenvoudig en is ook maklik om te bestuur.