概观: 周围这么多的开发框架, 我们应该能够在任何给定时间点,以扩大我们的应用程序就变得很重要. 学习机一样的聚类和分类技术,在这方面已经成为流行. 阿帕奇Mahout的是一个框架,帮助我们实现可扩展性.
In this document, 我将谈论的Apache Mahout中和它的重要性.
介绍: 阿帕奇Mahout的是Apache软件基金会或ASF的一个开源项目有创造机器学习算法的主要目标. 由来自Apache Lucene项目开发组的介绍, 阿帕奇Mahout的有,目的是 -
- 建立和支持用户或贡献者社区,使访问源代码的框架并不局限于一小部分开发商.
- 着眼于实际问题, 而不是看不见或未经证实的问题.
- 提供适当的文件.
阿帕奇亨利马乌的特点:
阿帕奇亨利马乌自带的特性和功能的阵列特别是当我们谈论集群和协同过滤. 最重要的特性被列为下 -
- 品尝协同过滤 - 味道 是协同过滤的一个开源项目. 这是Mahout的框架,它提供了机器学习算法,以扩大我们的应用程序的一部分. 味道是用于个人的建议. 当我们打开一个网站,这些天来,我们发现大量的相关网站的建议,我们正在浏览. 下图显示了味的架构图 -
品尝架构图
Figure 1: 品尝架构图
- 地图启用降低实现 - 几个地图启用减少聚集实现,在支持亨利马乌. 这包括 K均值, 模糊, 华盖
- 分布式贝叶斯Navie和免费Navie贝叶斯 - 阿帕奇象夫有两个Navie贝叶斯和贝叶斯免费实施. 为简单起见Navie贝叶斯作为贝叶斯和免费简称被称为CBayes. 贝叶斯在文本分类使用,而CBayes是贝叶斯的扩展,它在“数据集”的情况下使用.
- 它支持矩阵等相关载体库.
设置Apache Mahout的:
设置Apache亨利马乌是非常简单,并且可以在下面的步骤来进行 -
- Step 1 - 为了配置Apache Mahout中, 我们应该有以下安装 -
- JDK 1.6 or higher
- 蚂蚁 1.7 or higher
- Maven的 2.9 或更高 - 如果我们想从源代码来构建
- Step 2 - 解压缩文件, sample.zip和复制的内容在某些文件夹中说:“Apache的象夫 - 示例”.
- Step 3 - 进入里面的文件夹 - “Apache的象夫-例子”,并运行下面的 -
- 蚂蚁安装
最后一步下载维基百科的文件和编译代码.
推荐引擎:
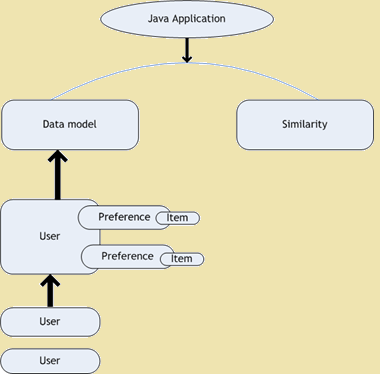
推荐引擎是信息过滤系统的一个子类,可以预测评级或偏好的用户可以给一个项目. 亨利马乌提供工具的,哪些是有利于建立一个使用'味道'库推荐引擎技术. 使用味道库,我们可以建立一个快速,灵活的协同过滤引擎. 味道是由它与用户携手以下五个主要组件, 项目和喜好 -
- 数据模型 - 这被用作用户的存储系统, 项目还喜好.
- 用户相似性 - 这是用来定义两个用户之间的相似性的接口.
- 项目相似 - 这是用来定义两个项目之间的相似性的接口.
- 推荐人 - 这是用来提供建议的接口.
- 用户邻居 - 这是用来计算和计算可以由条引荐使用相同类别的用户的邻域的接口.
使用这些组件和它们的实现, 我们可以建立一个复杂的推荐系统. 这个推荐引擎可以同时实时的建议和离线建议使用. 实时建议可处理用户达几千,而离线建议可以在更高的计数处理用户.
集群:
Mahout的支持许多集群机制. 这些算法都写在地图降低. 每一种算法都有自己的目标和标准. 其中重要的被列为下 -
- 冠层 - 这是用于创建其他聚类算法初始种子最快速聚类算法.
- ķ – 手段或模糊ķ – 意味着 - 这个算法将基于物品从先前迭代的中心的距离k个簇.
- 意思是 - 转变 - 这个算法不需要关于簇的数目的任何先验信息. 这可能会产生可被增加或减少按照我们需要的任意簇.
- 狄氏 - 这个算法通过组合一个或多个群集模型创建集群. 因此,我们得到一个优势,选择从多个簇的可能的最佳1.
出了上述四种算法上市, 最常用的是第k - means算法. 无论是任何聚类算法, 我们必须按照下列步骤 -
- 准备输入. If required, 转换成文本数字表示.
- 通过使用任何Hadoop的准备方案在Mahout中可用的执行你所选择的算法.
- 正确评估结果.
- 如果需要的话重复这些步骤.
内容分类:
阿帕奇亨利马乌支持以下两种方法进行分类或分类内容. 这主要是基于贝叶斯统计 -
- 第一种方法是直截了当的Map Reduce启用Navie贝叶斯分类器. 这一类的分类器被称为是快速和准确的,尽管有该数据是完全独立的假设. 这些分类分解时的数据的大小上升或数据成为相互依存的. Navie贝叶斯分类器是一个两部分的方法,该方法保持的,其与文档相关联的特征或仅仅字的轨道. 此步骤被称为训练也通过观察已分类的内容的示例创建模型. 第二步骤, 即分类, 使用该培训期间创建的模型和新的内容, 看不见的文件. 于是, 为了运行亨利马乌的分类, 我们首先需要训练模型,然后使用该模型对新内容进行分类.
- 第二种方法, 其也被称为互补朴素贝叶斯, 试图纠正一些与朴素贝叶斯方法的问题,并仍然保持由Navie贝叶斯提供的简单和速度.
运行Navie贝叶斯分类:
该Navie贝叶斯分类要求,以执行执行以下Ant目标 -
- 蚂蚁准备,文档 - 这个准备所需要的培训组文件.
- 蚂蚁准备测试,文档 - 此准备所需要测试的一组文件.
- 蚂蚁列车 - 一旦训练和测试数据设置, 我们需要用目标来运行TrainClassifier类 - “蚁列车”.
- 蚂蚁测试 - 一旦上述目标被成功执行, 我们需要运行这个目标,是以样本输入文件,并尝试基于在训练时建立的模型对它们进行分类.
Summary: 在这篇文章中,我们已经看到,阿帕奇亨利马乌被广泛用于文本分类利用机器学习算法. 的技术仍在增长,并且可以用于不同类型的应用程序开发. 让我们总结一下我们在下面的项目符号的形式讨论 -
- 阿帕奇Mahout的是Apache的一个开源项目由一组开发人员从Apache Lucene项目介绍. 该项目的主要目标是创建算法,可以读取机器语言.
- 阿帕奇亨利马乌具有以下重要特征 -
- 品尝协同过滤.
- MapReduce的启用实现.
- 实施为分布式贝叶斯Navie和免费Navie贝叶斯.
- 支持矩阵等相关载体基础库.