Overzicht: Met zoveel ontwikkelingskaders rond, wordt het belangrijk dat we moeten kunnen opschalen onze applicatie op een bepaald punt van de tijd. Machine learning technieken als clustering en categorisering zijn populair geworden in deze context. Apache Mahout is een raamwerk dat helpt ons om schaalbaarheid te bereiken.
In this document, Ik zal spreken over Apache Mahout en het belang ervan.
Introductie: Apache Mahout is een open source project van Apache Software Foundation of ASF, die het primaire doel van het maken van machine learning algoritme. Ingeleid door een groep ontwikkelaars van de Apache Lucene project, Apache Mahout heeft als doel -
- Bouwen en ondersteunen van een gemeenschap van gebruikers of medewerkers, zodat de toegang tot de broncode van het raamwerk is niet beperkt tot een kleine groep van ontwikkelaars.
- Focus op de praktische problemen, in plaats van ongeziene of onbewezen zaken.
- Zorg voor de juiste documentatie.
Kenmerken van Apache Mahout:
Apache Mahout wordt geleverd met een scala aan functies en functionaliteiten vooral wanneer we het hebben over Clustering en collaborative filtering. De belangrijkste kenmerken zijn opgenomen, zoals onder -
- Proef collaborative filtering - Smaak is een open source project voor collaborative filtering. Het is het deel van de Mahout kader dat machine learning algoritmen om opschaling van onze applicaties biedt. Smaak wordt gebruikt voor persoonlijke aanbevelingen. Deze dagen toen we een website te openen vinden we tal van aanbevelingen met betrekking tot de website die we bekijkt. De volgende figuur toont de architectuur diagram van Taste -
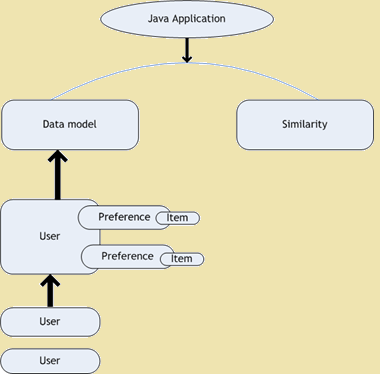
Proef Architectuur diagram
Figure 1: Proef Architectuur diagram
- Mapreduce ingeschakeld implementaties - Verscheidene mapreduce ingeschakeld geclusterd implementaties worden ondersteund in Mahout. Dit bevat K-gemiddelde, fuzzy, baldakijn
- Distributed Navie Bayes en gratis Navie Bayes - Apache mahout heeft de uitvoering voor zowel Navie Bayes en gratis Bayes. Voor de eenvoud Navie bayes worden aangeduid als Bayes en gratis worden aangeduid als CBayes. Bayes worden in tekstindelingsystemen terwijl de CBayes zijn uitbreiding van Bayes die gebruikt worden bij "reeks".
- Het ondersteunt Matrix en andere gerelateerde vector bibliotheken.
Het opzetten van Apache Mahout:
Opzetten Apache Mahout is zeer eenvoudig en kan in de volgende stappen worden uitgevoerd -
- Step 1 - Om te installeren Apache Mahout, we moeten het volgende geïnstalleerd -
- JDK 1.6 or higher
- Mier 1.7 or higher
- Maven 2.9 of hoger - In geval willen we bouwen vanaf de broncode
- Step 2 - Pak het bestand, sample.zip en kopieer de inhoud in bepaalde folder zeggen "apache-mahout-examples".
- Step 3 - Ga in de map - "apache-mahout-voorbeelden" en voer de volgende -
- mier installeren
De laatste stap downloadt de Wikipedia-bestanden en stelt de code.
aanbeveling Engine:
Aanbevelingsmotor is een subklasse van informatiefiltering systeem dat de beoordeling of gebruikersvoorkeuren kan voorspellen kan geven aan een item. Mahout biedt tools en technieken die nuttig zijn de aanbeveling van de motoren met behulp van de 'Taste bibliotheek te bouwen zijn. Met behulp van Taste bibliotheek kunnen we een snelle en flexibele collaborative filtering engine te bouwen. Smaak bestaat uit de volgende vijf hoofdcomponenten die samenwerken met gebruikers, items en voorkeuren -
- Data Model - Dit wordt gebruikt als een opslagsysteem voor gebruikers, items en ook voorkeuren.
- Gebruiker Similarity - Dit is een interface wordt gebruikt om de soortgelijkheid tussen twee gebruikers.
- Punt Gelijkenis - Een interface die wordt gebruikt om de soortgelijkheid tussen twee artikelen.
- recommender - Een interface die wordt gebruikt om aanbevelingen.
- Gebruiker Neighborhood - Een interface die wordt gebruikt voor het berekenen en een buurt van gebruikers van dezelfde categorie die kunnen worden gebruikt door het berekenen Aanbevelers.
Met behulp van deze componenten en hun implementaties, kunnen we een complex aanbeveling systeem op te bouwen. Deze aanbeveling motor kan worden gebruikt in zowel realtime aanbevelingen en offline aanbevelingen. Real-time aanbevelingen kan omgaan met gebruikers tot enkele duizenden, terwijl de offline aanbevelingen kan omgaan met de gebruikers in veel hogere count.
clustering:
Mahout ondersteunt vele clustering mechanismen. Deze algoritmen zijn geschreven in mapreduce. Elk van deze algoritmes heeft zijn eigen set van doelstellingen en criteria. De belangrijkste daarvan zijn opgenomen, zoals onder -
- Canopy - Dit is de meest snelle clustering algoritme dat wordt gebruikt om de eerste zaden voor andere clustering algoritmen creëren.
- k – Middelen of Fuzzy k – betekent - Dit algoritme maakt k clusters gebaseerd op de afstand van de voorwerpen uit het midden van de vorige iteratie.
- Mean - Shift - Dit algoritme heeft geen voorafgaande informatie over het aantal clusters vereisen. Dit kan een willekeurige cluster kan worden verhoogd of verlaagd volgens onze behoefte produceren.
- Dirichlet - Dit algoritme maakt clusters door het combineren van één of meer clustermodellen. Zo krijgen we een voordeel om de best mogelijke is uit een aantal clusters selecteren.
Uit de bovenstaande vier algoritmen opgesomd, de meest gebruikte is de k - middelen algoritme. Of het nu elke clustering algoritme, we moeten de volgende stappen -
- Bereid de ingang. If required, zetten de tekst in numerieke weergave.
- Voer het algoritme van uw keuze met behulp van een van de Hadoop klaar programma's beschikbaar in Mahout.
- Naar behoren de resultaten te evalueren.
- Herhaal deze stappen indien nodig.
Content categoriseren:
Apache Mahout ondersteunt de volgende twee benaderingen te categoriseren of classificatie van de inhoud. Deze zijn voornamelijk gebaseerd op Bayesiaanse statistiek -
- De eerste benadering is rechttoe rechtaan mapreduce ingeschakeld Navie Bayes classifier. Classificatoren van deze categorie zijn bekend snel en accuraat ondanks de aanname dat de gegevens volledig onafhankelijk. Deze classifiers breken wanneer de grootte van de gegevens omhoog gaat of data wordt onderling afhankelijke. Navie Bayes classifier is een tweedelig proces dat een spoor van de kenmerken of gewoon woorden die verband houdt met een document. Deze stap is bekend als opleiding, die ook zorgt voor een model door te kijken naar voorbeelden van reeds ingedeelde inhoud. De tweede stap, bekend als indeling, gebruikt het model dat wordt gemaakt tijdens de training en de inhoud van een nieuw, ongezien document. Dus, om Mahout classifier draaien, moeten we eerst het model te trainen en dan gebruik maken van het model om nieuwe content te classificeren.
- De tweede benadering, die ook bekend staat als een aanvulling Naive Bayes, probeert om enkele van de problemen met de Naive Bayes aanpak te corrigeren en nog steeds houdt de eenvoud en snelheid aangeboden door Navie Bayes.
Het uitvoeren van de Navie Bayes Classifier:
De Navie Bayes classifier vereist het uitvoeren van de volgende mier doelen om uit te voeren -
- ant bereiden-docs - Dit bereidt de set documenten die nodig zijn voor de opleiding.
- ant bereiden test-docs - Dit bereidt de set documenten die nodig zijn voor het testen.
- ant trein - Zodra de training en tests gegevens worden ingesteld, we nodig hebben om de TrainClassifier klasse uitvoeren met het doel - "ant train".
- ant-test - Zodra de bovenstaande doelstellingen worden succesvol uitgevoerd, we nodig hebben om deze doelstelling dat het monster ingang documenten neemt en probeert ze in te delen op basis van het model dat is gemaakt tijdens de training lopen.
Summary: In dit artikel hebben we gezien dat Apache Mahout grote schaal wordt gebruikt voor tekst indeling met behulp van machine learning algoritmen. De technologie is nog steeds en kan worden gebruikt voor verschillende soorten toepassingen ontwikkeling. Laat ons samen te vatten onze discussie in de vorm van volgende kogels -
- Apache Mahout is een open source project van Apache geïntroduceerd door een groep van ontwikkelaars van de Apache Lucene project. Primaire doel van dit project is het algoritme dat machinetaal kan lezen creëren.
- Apache Mahout heeft de volgende belangrijke functies -
- Proef collaborative filtering.
- MapReduce ingeschakeld implementaties.
- Implementatie voor zowel Distributed Navie Bayes en gratis Navie Bayes.
- Ondersteunt matrix en andere gerelateerde vector-gebaseerde bibliotheken.