Áttekintés: A sok fejlesztés keretek körül, fontossá válik, hogy képesnek kell lennünk, hogy fokozzák az alkalmazás bármely adott időpontban. Gépi tanulási technikák, mint a klaszterek és kategorizálás népszerűvé váltak ebben az összefüggésben. Apache Mahout egy keretrendszer, amely segít elérni a skálázhatóság.
In this document, Fogok beszélni Apache Mahout és jelentősége.
Bevezetés: Apache Mahout egy nyílt forráskódú projekt Apache Software Foundation vagy ASF, amelynek elsődleges céllal, hogy létrehozza a gépi tanulás algoritmus. Bevezetett egy csoportja a fejlesztők az Apache Lucene projekt, Apache Mahout az a célja, hogy -
- Építeni, és támogatja a felhasználói közösség, illetve résztvevők, hogy a hozzáférés a forráskódot a keret nem korlátozódik egy kis csoportja a fejlesztők.
- Fókuszban a gyakorlati problémák, ahelyett, láthatatlan vagy bizonyítatlan kérdések.
- A megfelelő dokumentációt.
Jellemzői Apache Mahout:
Apache Mahout jön egy sor tulajdonságokat és funkciókat, különösen, ha beszélünk Klaszterek és csoportos. A legfontosabb funkciók vannak felsorolva alatt -
- Íz Collaborative Filtering – Íz egy nyílt forráskódú projekt együttműködő szűrés. Ez a része a Mahout keret, amely a gépi tanulási algoritmusok bővíteni alkalmazásainkat. Ízében személyes ajánlások. Manapság, amikor megnyit egy weboldalt találunk bőven ajánlások az oldallal kapcsolatban, hogy mi a böngészés. Az alábbi ábrán az architektúra diagram Taste -
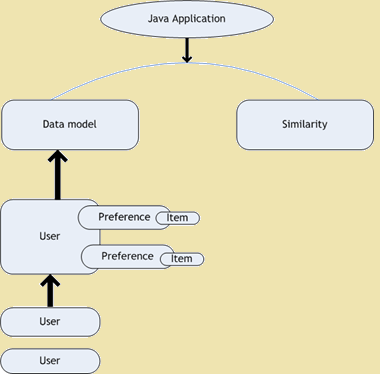
Íz architektúra diagram
Figure 1: Íz architektúra diagram
- Mapreduce engedélyezve megvalósítások - Több mapreduce kompatibilis fürtözött implementáció támogatja Mahout. Ebbe beletartozik K-közép, elmosódott, Ejtőernyőkupola
- Elosztott Navie Bayes és ingyenes Navie Bayes - Apache elefántápoló van végrehajtására egyaránt Navie Bayes és ingyenes Bayes. Az egyszerűség kedvéért Navie Bayes nevezzük, melynek Bayes és ingyenes nevezzük, melynek CBayes. Bayes használják szövegosztályozási míg a CBayes vannak kiterjesztése Bayes amelyeket az említett "Datasets '.
- Támogatja Mátrix és egyéb kapcsolódó vektor könyvtárak.
Beállítása Apache Mahout:
Beállítása Apache Mahout nagyon egyszerű, és el lehet végezni a következő lépésekben -
- Step 1 - Annak érdekében, hogy a telepítést Apache Mahout, mi kell a következő telepített -
- JDK 1.6 or higher
- Hangya 1.7 or higher
- Maven 2.9 vagy magasabb - Abban az esetben szeretnénk építeni a forráskódot
- Step 2 - Csomagolja ki a fájlt, sample.zip és másolja a tartalmát néhány mappát, hogy "apache-elefántápoló-példák".
- Step 3 - Menj be a mappa - "apache-elefántápoló-példák", és futtassa a következő -
- hangya telepíteni
Az utolsó lépés letölti a Wikipédia fájlokat és lefordítja a kódot.
ajánlás Engine:
Ajánlás motor egy alosztálya információs szűrőrendszer, amely meg tudja jósolni a minősítés vagy a beállítások a felhasználó adhat egy tételt. Mahout eszközöket és technikákat, amelyek hasznosak építeni ajánlás motorok az 'íz' könyvtár. Használata Íz könyvtár tudunk építeni egy gyors és rugalmas Collaborative szűrőmotor. Íz áll a következő öt fő összetevőre amely együttműködik a felhasználók, elemek és preferenciák -
- Adatmodell - Ezt használják, mint a tároló rendszer a felhasználók, tételek és kedvezmények.
- Felhasználói Hasonlóság - Ez egy felület meghatározására használt közötti hasonlóság két felhasználó.
- Pont Hasonlóság - Interfész mellyel a hasonlósági elemek közé.
- Ajánló - Egy interfész, mellyel ajánlásokat.
- Felhasználói Neighborhood - Egy felület, amely alkalmazzuk, hogy kiszámítsuk, és kiszámítja a szomszédságában felhasználók azonos kategóriájú, amely felhasználható a Recommenders.
Ezekkel összetevők és megvalósítások, tudunk építeni egy komplex javaslatot rendszer. Ez az ajánlás a motor használható mind a valós idejű ajánlások és az offline ajánlások. Valós idejű ajánlások képes kezelni a felhasználók akár néhány ezer, míg az offline ajánlások képes kezelni a felhasználók sokkal nagyobb száma.
Klaszterek:
Mahout támogat sok csoportosítási mechanizmusok. Ezek az algoritmusok vannak írva mapreduce. Minden ilyen algoritmusok a saját célokat és kritériumokat. A legfontosabbak vannak felsorolva alatt -
- Ejtőernyőkupola - Ez a leginkább gyors csoportosítási algoritmus célja, hogy kezdeti mag más csoportosítási algoritmusok.
- k – Eszközzel vagy Fuzzy k – jelenti - Ez az algoritmus létrehoz k klaszterek távolság alapján a tételek a központtól az előző iteráció.
- Jelent - Shift - Ez az algoritmus nem igényel semmilyen előzetes információt a klaszterek számát. Ez képes egy tetszőleges klaszter, amely lehet növelni vagy csökkenteni, mint egy igényünk.
- Dirichlet - Ez az algoritmus létrehoz klaszterek kombinálásával egy vagy több fürt modellek. Így kapunk egy előnye, hogy kiválassza a lehető legjobb egy-egy klaszterek száma.
Ki a fenti négy algoritmusok felsorolt, a leggyakrabban használt a K - azt jelenti algoritmus. Legyen az bármilyen csoportosítás algoritmus, követnünk kell ezeket a lépéseket -
- Készítsük el a bemeneti. If required, alakítják a szöveget, numerikus.
- Végrehajtás az algoritmus a választott segítségével bármelyik Hadoop készen rendelkezésre álló programok Mahout.
- Megfelelően értékelni az eredményeket.
- Hajtogat alábbi lépéseket, ha szükséges.
tartalom kategorizálás:
Apache Mahout támogatja a következő két megközelítés kategorizálni vagy osztályozása a tartalom. Ezek főleg a Bayes statisztika -
- Az első megközelítés egyenesen előre mapreduce engedélyezve Navie Bayes osztályozó. Osztályozók e kategória ismert, hogy a gyors és pontos annak ellenére, hogy a feltételezést, hogy az adatok teljesen független. Ezek osztályozók lebontják, ha a mérete az adatok felmegy vagy adatokhoz jut egymással összefüggő. Navie Bayes osztályozó egy két részből álló folyamat, amely megtartja a pályán a funkciók, vagy egyszerűen csak szavak, amelyek egy dokumentummal társítható. Ez a lépés az úgynevezett képzést is létrehoz egy modellt nézi példákat már besorolt tartalom. A második lépés, ismert osztályozás, használja a modell, amely során jön létre a képzés és a tartalmat egy új, láthatatlan dokumentum. Ennélfogva, érdekében, hogy fut Mahout a osztályozót, először ki kell képezni a modell, majd a modell minősítette az új tartalom.
- A második megközelítés, amely szintén ismert, mint kiegészítő Naiv Bayes, igyekszik orvosolni egyes kérdéseket a Naiv Bayes megközelítés és továbbra is fenntartja az egyszerűség és gyorsaság nyújtotta Navie Bayes.
Futás a Navie Bayes osztályozó:
A Navie Bayes osztályozó igényel végrehajtó a következő hangya célok végrehajtása érdekében -
- hangya készít-docs - Előkészíti a sor dokumentumot, amelyek a képzéshez szükséges.
- hangya készít-teszt-docs - Előkészíti a sor dokumentumot, amelyek szükségesek a vizsgálatok.
- hangya vonat - Miután a képzés és a vizsgálatok adatai vannak beállítva, meg kell futtatni a TrainClassifier osztályban a cél - "ant vonat".
- hangya teszt - Ha a fenti célok sikeresen végrehajtásra, meg kell futtatni ezt a célt, hogy azon a minta input dokumentumok és megpróbálja sorolják őket a modell alapján létrehozott edzés közben.
Summary: Ebben a cikkben azt láttuk, hogy az Apache Mahout széles körben használják a szöveges besorolás felhasználásával gépi tanulási algoritmusok. A technológia még mindig növekszik, és fel lehet használni a különböző típusú alkalmazás fejlesztés. Let us summarize our discussion in the form of following bullets –
- Apache Mahout egy nyílt forráskódú projekt Apache által bevezetett fejlesztők egy csoportja az Apache Lucene projekt. Elsődleges cél a projekt célja, hogy hozzon létre algoritmus, amely képes olvasni gépi nyelv.
- Apache Mahout a következő fontos jellemzői -
- Íz Collaborative Filtering.
- MapReduce engedélyezve megvalósítások.
- Végrehajtás mindkét Elosztott Navie Bayes és ingyenes Navie Bayes.
- Támogatja mátrix és egyéb kapcsolódó vektoros könyvtárak.